[pandas超入門]探索的データ分析の基礎:タイタニックデータセットを調べてみよう:Pythonデータ処理入門
機械学習やディープラーニングにおいて練習材料としてよく使われるタイタニックデータセットを使って、その概要や、性別と生死に関連があるかどうかを調べてみましょう。
本シリーズと本連載について
本シリーズ「Pythonデータ処理入門」は、Pythonの基礎をマスターした人を対象に以下のような、Pythonを使ってデータを処理しようというときに便利に使えるツールやライブラリ、フレームワークの使い方の基礎を説明するものです。
- NumPy(「NumPy超入門」の目次はこちら)
- pandas(本連載)
- Matplotlib
なお、本連載では以下のバージョンを使用しています。
- Python 3.12
- pandas 2.2.1
前回は欠損値とその処理の仕方を解説しました。今回はタイタニックデータセットを使って、その内容を簡単に確認してみます。
タイタニックデータセット
タイタニックデータセットの詳細については「Titanic:タイタニック号乗客者の生存状況(年齢や性別などの13項目)の表形式データセット」をご覧ください。ただし、前掲のリンクにあったデータセット配布元がリンク切れのようなので、ここではGitHubのpandasリポジトリから取得できるtitanic.csvファイルを使うことにしました。このファイルは前掲のリンクで解説しているタイタニックデータセットと異なる点もあるので、簡単に異なる箇所をまとめておきましょう。
- 行数が891行になっている
- 'PassengerId'行が追加されている
- 幾つかの列が削除されている
こちらのタイタニックデータセットが持つ列は以下のようになっています。
- 'PassengerId':乗客ID。整数値
- 'Survived':生き残ったかどうか。整数値(0:死亡、1:生存)
- 'Pclass':旅客クラス。整数値(1:1等、2:2等、3:3等)
- 'Name':乗客名。文字列
- 'Sex':性別。文字列(male:男性、female:女性)
- 'Age':年齢。浮動小数点数値
- 'SibSp':同乗していた兄弟や配偶者の数。整数値
- 'Parch':同乗していた親や子の数。整数値
- 'Ticket':チケット番号。文字列
- 'Fare':運賃。浮動小数点数値
- 'Cabin':客室番号。文字列
- 'Embarked':乗船地。文字列(S:サウサンプトン、C:シェルブール、Q:クイーンズタウン)
整数値や浮動小数点数値だけではなく、文字列のデータも含んでいます。それらのデータをどのように処理すればよいかも考える必要があるでしょう。
これらの列の中で'Survived'列は他の列とは異なる扱いをされることがよくあります。タイタニックデータセットでは、他の列のデータを総合的に勘案した結果、乗客や乗組員が生き残ったのかどうかを考えることがよくあります。つまり、'Survived'列は他の列を原因として発生した結果であり、他の列は'Survived'列の結果を生み出した要因です。前者を目的変数や正解ラベルと、後者を説明変数や特徴量ということもあります。
まあ、何はともあれ、上記のリンクからtitanic.csvファイルをダウンロードして、読み込んでみることにします。

CSVファイルの読み込みにはpandas.read_csv関数を使います。
import pandas as pd
df = pd.read_csv('titanic.csv')
df
Visual Studio Code(以下、VS Code)で新規にノートブックを作成し、上記コードを実行すると、次のようにtitanic.csvファイルの内容がDataFrameオブジェクトとして読み込まれ、その内容(の一部)が表示されます。

これで取りあえずの準備は完了です。この後は次のようなことをやっていきましょう。
- DataFrameオブジェクトの概要の調査
- タイタニックデータセットを少しだけ調べてみる
DataFrameオブジェクトの概要を調べる
DataFrameオブジェクトの概要を調べるには、以前にも紹介した以下のメソッドなどが使えます。
- pandas.DataFrame.headメソッド
- pandas.DataFrame.infoメソッド
- pandas.DataFrame.tailメソッド
上で見たコードの最終行「df」を実行するだけでも、このDataFrameオブジェクトの先頭5行と末尾5行、それからこのDataFrameオブジェクトには891行×12列のデータが格納されていることが分かります。先頭5行と末尾5行が表示されているので、headメソッドとtailメソッドを試す必要はないでしょうから、ここではinfoメソッドを呼び出してみます。
pandas.DataFrame.infoメソッド
pandas.DataFrame.info(verbose=None, max_cols=None, show_counts=None)
DataFrameオブジェクトの概要を出力する。幾つかのパラメーターを以下に示す。全パラメーターについてはpandasのドキュメント「pandas.DataFrame.info」を参照のこと。
- verbose:概要を全て表示するかどうかの指定。Trueを指定すると概要を全て表示し、Falseを指定すると行数と列数、データ型の要約などだけを表示する。省略時にはpandas.options.display.max_info_columns属性の値よりも列数が少なければTrueを指定したのと同じ振る舞いを、多ければFalseを指定したのと同じ振る舞いをする
- max_cols:概要を全て表示するか、少なく表示するかを切り替える列数を指定する。省略時にはpandas.options.display.max_columns属性の値が指定されたものと見なされる
- show_counts:各列に含まれる欠損値ではない値の数を表示するかどうかを指定する。Trueを指定すると常に表示し、Falseを指定すると常に表示しない。省略時にはDataFrameオブジェクトの行数および列数がpandas.options.display.max_info_rows属性およびpandas.options.display.max_info_columns属性の値よりも小さいかどうかで振る舞いが決定される
まずは特に何も指定しないでinfoメソッドを呼び出してみます。
df.info()
VS Codeでこれを実行した結果を以下に示します。

このように行インデックス(RangeIndex)と列ラベル(columns)の数、各列に欠損していないデータがどれだけ含まれているかや、その列のデータ型が何か、各データ型の列がどれだけあるかといった情報が表示されます。これを見ると'Cabin'列には欠損しているデータが大変多いことが分かりますね。dtypeを見ると、文字列(object型)になっているのは、'Name'列と'Sex'列、'Ticket'列、'Cabin'列、それから'Embarked'列です。このような文字列をデータとして格納している列についていえば、それらをプログラムで機械的に処理する目的で最終的に何らかの数値に変換する必要が出てくるでしょう。このことについては次回に検討するものとします。
次にverboseパラメーターにFalseを指定してみましょう。
df.info(verbose=False)
以下が実行結果です。

今度はmax_colsパラメーターに、DataFrameオブジェクトの列数よりも少ない値を指定してみます。
df.info(max_cols=10)
このDataFrameオブジェクトには12の列があるので、それよりも少ない値がmax_colsパラメーターに渡されたということです。このときには、次のように各列の情報が表示されなくなります。
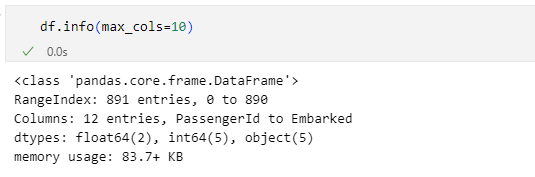
最後にshow_countsパラメーターにFalseを指定してみましょう。
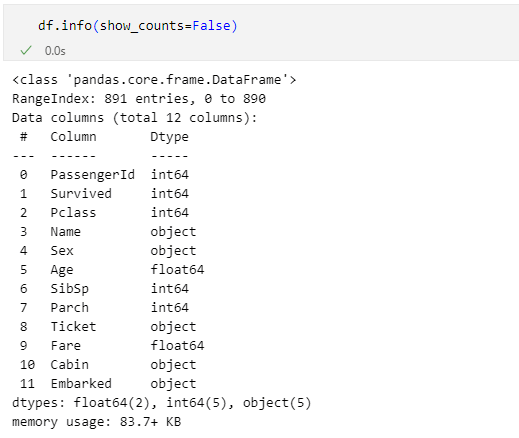
df.info(show_counts=False)
このときには次のように、欠損していないデータの個数が表示されなくなります(各列の列ラベルとその列のデータ型だけが表示される)。
多くの場合は特にパラメーターを指定せずに呼び出すのが正解でしょう。DataFrameオブジェクトの概要を簡潔に教えてもらえるはずです。
もう1つ、DataFrameオブジェクトの概要を知るためのメソッドがあります。それがpandas.DataFrame.describeメソッドです。
pandas.DataFrame.describeメソッド
pandas.DataFrame.describe(percentiles=None, include=None, exclude=None)
DataFrameオブジェクトの基本統計量を表示する。パラメーターを以下に示す。詳細はpandasのドキュメント「pandas.DataFrame.describe」を参照のこと。
- percentiles:表示するパーセンタイルの指定。省略時には[.25, .5, .75]が指定されたものと見なされる
- include:基本統計量を表示する列のデータ型の指定。'all'かデータ型を要素とするリストを指定できる(後述)。省略した場合は数値型の列についてのみ基本統計量を表示する
- exclude:基本統計量の表示から除外する列のデータ型の指定。データ型を要素とするリストを指定できる(後述)。省略した場合は特に除外される列の指定はされなかったと見なされる
先ほどと同様、まずはそのままdescribeメソッドを呼び出してみます。
df.describe()
VS Codeでこのコードを実行すると次のようになります。

各列のデータ数(count)、平均値(mean)、標準偏差(std)、最小値(min)、四分位数(25%、50%、75%)、最大値(max)が表示されることが分かりました。四分位数というのは、データを小さい順に並べた上で全体を4等分し、最小値から4分の1の場所にあるデータ、2分の1の場所にあるデータ、4分の3の場所にあるデータを取り出したものです(これらを25%タイル、50%タイル、75%タイルなどと呼ぶこともあります)。さらにこれを細かく10%、20%、……のように分割することもあり、その場合はパーセンタイルと呼ぶことがあります。四分位数やパーセンタイルは列の中で個々のデータがどのように分布しているかをざっくりと見るのに役立ちます。
例えば、'PassengerId'列は1から891までの連番なので、最小値が1、25%タイルの値は223.5、50%タイルの値は446、75%タイルの値は668.5、最大値が891と等間隔で並んでいます(これはデータに連番で順番を付けただけなので、実際のところ、これには意味はありません)。'Survived'列は死亡が0で、生存が1と2種類のデータしか格納していないのでこれも四分位数を見てもあまり意味はないでしょう。'Pclass'列も同様です。'Age'列には意味がありそうです。25%タイルの値が20.125、75%タイルの値が38.0ということは、乗客と乗組員全体の半数が20歳から38歳で構成されているということです(意外に若い?)。こんな感じでデータを読み解いていくのにdescribeメソッドは役立つことがあります。
なお、percentilesパラメーターには次のようにどの位置のデータを取得したいかをリストに含めて指定します。以下はデフォルトの指定と同じです。
df.describe(percentiles=[.25, .75, .95])
includeパラメーターは基本統計量を表示したい列を指定するのに使います。デフォルトでは数値を要素とする列だけが対象となります。このパラメーターの指定方法は幾つかありますが、簡単なのは'integer'(整数を要素とする列)や'float'(浮動小数点数を要素とする列)、'number'(数値を要素とする列)、'object'(文字列などを要素とする列)などをリストにまとめて渡すものです。以下に例を示します。
df.describe(include=['object'])
includeパラメーターには['object']と指定しているので、ここでは文字列を要素とする列だけが表示の対象となります(文字列以外にもobject型となる値があることには注意してください)。実行結果は次のようになりました。
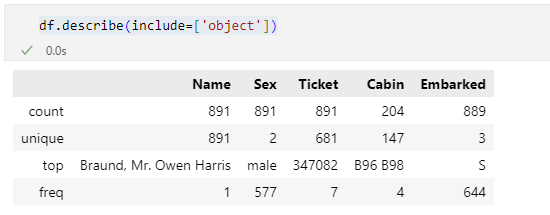
今回は文字列を要素とする列だけが対象となっています。そして、こうした場合には要素数(count)、ユニークな要素の数(unique)、最頻値(top)、最頻値の登場回数(freq)が表示されている点に注目してください。
例えば、'Sex'列を見ると、ユニークな値は2種類(恐らくはmaleとfemale)、最頻値はmaleでその登場回数が577であることから、乗客と乗組員の多くが男性であったことが分かります。
浮動小数点数と文字列を要素とする列を指定するには次のようにします。
df.describe(include=['float', 'object'])
この場合は次のように、各列について表示できないものはNaNが表示されます(内容的には検討する必要はないでしょう)。

なお、includeパラメーターには'all'を指定することも可能です。この場合は全ての列が表示の対象となります。
excludeパラメーターは'all'の指定ができないことを除けば、includeパラメーターと同様に指定します。ただし、こちらは統計量の表示対象から除外する列の指定です。デフォルト値は除外するものはない、となりますが、includeパラメーターもexcludeパラメーターも指定しない場合には、数値の列だけを対象とする(includeパラメーターのデフォルト)と除外するものはない(excludeパラメーターのデフォルト)が組み合わさって、結果、数値の列だけが対象となります。excludeパラメーターに何かを指定したときには、それ以外の列が全て対象となる点には注意してください。
最後にこれらのパラメーターの指定方法には他にもいろいろなバリエーションがあります。それらについてはpandasのドキュメント「pandas.DataFrame.describe」を参考にしてください。
タイタニックデータセットをもう少しだけ調べてみる
現在のタイタニックデータセットには文字列を含む列も存在したままですが、それでも乗客と乗組員の特徴と生死を調べることは可能です。ちょっとやってみましょう。
まず思い浮かぶのは、女性と男性とで生存率に差はあるのかどうか、です*1。
tmp0 = df[(df['Sex'] == 'female') & (df['Survived'] == 0)]
tmp1 = df[(df['Sex'] == 'female') & (df['Survived'] == 1)]
tmp2 = df[(df['Sex'] == 'male') & (df['Survived'] == 0)]
tmp3 = df[(df['Sex'] == 'male') & (df['Survived'] == 1)]
survived_rate_f = len(tmp1) / (len(tmp0) + len(tmp1))
survived_rate_m = len(tmp3) / (len(tmp2) + len(tmp3))
print(survived_rate_f, survived_rate_m)
詳しい説明はしませんが、4つの変数に代入しているのはdfの要素の中で'Sex'列の値が'female'か'male'か、加えて'Survived'列の値が0か1かという条件分けに合致している要素です。その数が分かったら、生存者の数を全体の数で割れば生存率が得られるというわけです。
実行結果は以下の通りです。
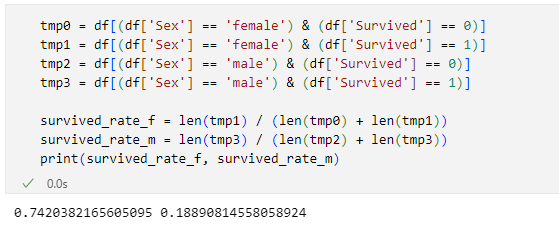
男性よりも女性の方が圧倒的に高い生存率になっていることが分かりました。
*1 実際には、これはpandas.DataFrame.groupbyメソッドを使ってもっとシンプルに書けます(が、まだgroupbyメソッドを紹介していないので、上では面倒なコードになっています)。
tmp = df.groupby('Sex')['Survived'].value_counts(normalize=True)
tmp
同様に、旅客クラス(’Pclass’列)と生存率の関連を見てみました(コードは下の画像を参照。やっていることは上と同じ。groupbyメソッドを使ったコードの実行結果も掲載)。

こちらを見ても旅客クラスがよいほど、生存率は高くなっています。
最後に旅客クラスと性別が生存率にどう関係しているかを見てみましょう(ここではgroupbyメソッドで計算するコードのみを画像に掲載)。

旅客クラスの差と性別の差で、これほどまでに生存率に差があるとは筆者も思っていませんでした。でも、高いお金を払った人を優先的に助けよう、女性を優先的に助けよう、と考えての乗組員の行動なのかもしれませんね。
このように一見すると単なるデータの羅列でしかないデータセットでも、あるデータとあるデータの関連を見つけ出していくことで、何かの出来事(この場合はタイタニックの事故で起きたこと)の背景が浮かび上がることがあります。このように探索的にデータ分析していくことで、より大きな真実が見えてくるかもしれません(ホントかな?)。
次回は欠損値を持つ列('Cabin'列など)をどうすればよいか、文字列を要素とする列をどうすればよいかに着目してDataFrameオブジェクトに手を加えていく予定です。
Copyright© Digital Advantage Corp. All Rights Reserved.