
誕生月分布のプロット
Jリーガーの誕生月別データについては幸いなことにファンの方が「j-league.net」というサイトを運営されていて、そこに2009年までの選手の誕生月とごの人数をカウントしています(Jリーグ100チームを目指して)。これを利用したいと思います。
まずは何より、この図をプロットすることにします。それには上記のページの表は、「生まれ月」カラムには「月」という文字が、「人数」カラムには「人」という文字が含まれていて、このままではデータとして利用できません。細かい作業については、別の機会に記述しますが、まずは整形したデータを別途用意しましたので、それを利用してください。Rのインストール方法については、Windows版とMac版について簡単なチュートリアル動画を用意しましたので、そちらをご覧ください。
ここからの説明は、すでにRがインストールされていることとします。まずは、Rを立ち上げます。
$ R R version 2.10.1 (2009-12-14) Copyright (C) 2009 The R Foundation for Statistical Computing ISBN 3-900051-07-0
Rは、自由なソフトウェアであり、「完全に無保証」です。 一定の条件に従えば、自由にこれを再配布することができます。 配布条件の詳細に関しては、'license()'あるいは'licence()'と入力してください。 Rは多くの貢献者による共同プロジェクトです。
詳しくは'contributors()'と入力してください。 また、RやRのパッケージを出版物で引用する際の形式については 'citation()'と入力してください。
'demo()'と入力すればデモをみることができます。 'help()'とすればオンラインヘルプが出ます。 'help.start()'でHTMLブラウザによるヘルプがみられます。 'q()'と入力すればRを終了します。 >
表示されるプロンプトに以下のコマンドを入力し、Rから直接URLを指定してデータをダウンロードし、そのダウンロードしたデータをメモリ上にロードしてください。
> conn <- url("http://euler.bakfoo.com/public/jleagers.rda")
> load(conn)
>
すると、data.jleagersというオブジェクトが環境に追加されていることが分かります。ls関数で現在ロードされているオブジェクトを列挙することができます。
> ls() [1] "conn" "data.jleagers"
このオブジェクトタイプをみると、Rのデータテーブルという表形式であることが分かります。class関数がオブジェクトのタイプを表示します。
> class(data.jleagers) [1] "matrix"
実際のデータを表示するには、単にそのオブジェクトを呼び出します。
> data.jleagers
jan feb mar apr may jun jul aug sep oct nov dec
[1,] 58 52 60 125 137 110 101 98 108 88 67 69
誕生月ごとのJリーガーの人数が見えます。これは先ほどのページと同じものです。まずは、これをプロットしてみましょう。
> barplot(data.jleagers)
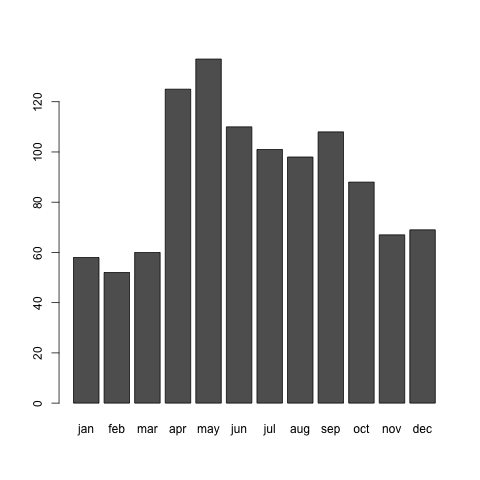
これを見ると分かるように、4月生まれと5月生まれのJリーガーの人数が突出しているように見える一方で、10月以降生まれのJリーガーが少なくなっているように思います。マタイ効果はJリーガーにも存在しそうです。これを定量的に調べるためにはどうすればいいかということを、以下で考えたいと思います。
グラフの印象ではなく、定量的に議論するには
定量的に調べるには、何かのデータと比較しなければなりません。ここでは、Jリーガーは圧倒的に日本人が多いということから、日本で出生した人の誕生月分布を利用したいと思います。日本人の誕生月分布とJリーガーの誕生月分布は統計的な相違があるのかどうか、それを調べればJリーガーの誕生月分布がグラフの印象通り偏っているかどうかを決定することができます。
日本人の誕生月分布は、厚生労働省が人口動態調査として統計をとっていて、「政府統計の総合窓口」からアクセスすることができます。「政府統計の総合窓口」の人口動態調査→平成20年人口動態統計→上巻→出生→年次→2008年と進んで(リンク)、「月別にみた年次別出生数及び率(人口千対)」のCSVをダウンロードします。
ただし、実際にデータを利用するにはある程度の加工をしなければなりませんので、今回は筆者の方でRのデーターフレームとして加工しておきました。Rのプロンプトから以下のコマンドでダウンロードし、メモリにロードしてください。
> conn <- url("http://euler.bakfoo.com/public/japanpop.rda")
> load(conn)
> ls()
[1] "data.japan" "data.jleagers"
> class(data.japan)
[1] "data.frame"
この操作によって、data.japanというデータフレームオブジェクトが読み込まれることになります。このデータは、以下のように先頭を表示すると、年ごとに統計を取った月別出生数となっています。
> head(data.japan)
year total jan feb mar apr may jun jul aug sep
1 1947 2678792 295465 226018 235891 209159 195574 194633 226560 236831 231874
2 1950 2337507 256132 219654 214964 188188 170659 161891 185380 190724 191798
3 1955 1730692 200116 157071 156751 148066 132368 118513 132759 142036 138323
4 1960 1606041 166782 142765 149415 144241 126974 115415 125991 129803 128977
5 1965 1823697 167220 151449 159421 154749 140137 135226 151439 157205 158681
6 1970 1934239 174550 154966 164241 166087 160860 153129 169825 163974 157094
oct nov dec
1 229058 210764 186961
2 187863 185213 185041
3 137054 132986 134649
4 125258 123072 127348
5 159240 144084 144846
6 152911 148875 167727
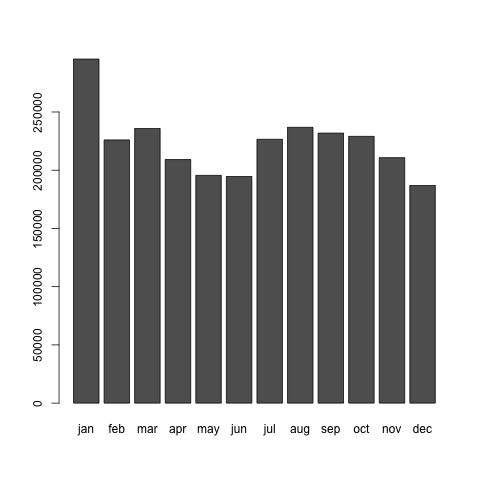
これをプロットしてみましょう。例えば1947年と、最近の2008年をプロットしてみます。データフレームにはプロットに余計なカラムがあるので、それを取り除く処理をしていますが、今回は詳しく述べません。データはbarplot関数により、頻度分布としてプロットします。
> jap1947 <- matrix(data.japan[1,-c(1,2)], nrow=1, byrow=T)
> colnames(jap1947) <- c("jan","feb","mar","apr","may","jun","jul","aug","sep","oct","nov","dec")
> dev.new()
> barplot(jap1947)
> jap2008 <- matrix(data.japan[24,-c(1,2)], nrow=1, byrow=T)
> colnames(jap2008) <- c("jan","feb","mar","apr","may","jun","jul","aug","sep","oct","nov","dec")
> dev.new()
> barplot(jap2008)
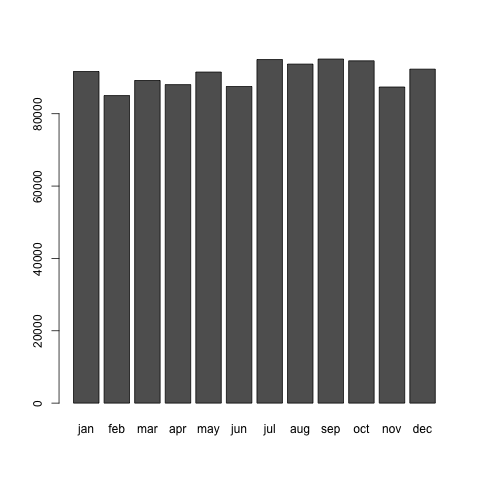
2つのプロットを比べてみると分かりますが、1947年の分布と2008年の分布ではずいぶんと様子が違うことが分かります。
実は先ほど紹介した先行的な解説において、Jリーガーの誕生月分布を調べるときには、日本人の誕生月分布が一様に、つまり1月から12月まで偏りなく分布しているということを前提としていました。しかし、実際の日本人の誕生月分布は一様ではありません。1960年以前は1月の出生数が突出していて、1960年から現在までは1月生まれはそれほど多くはなく、夏生まれが多いというようになっています。この日本人の月別出生数データをこのまま利用すると問題がありそうですので、ちょうどJリーガーの生まれ年あたりの年を利用したいと思います。前述のファンサイトの選手年鑑を見ますと、Jリーガーの現役最年長選手は三浦知良選手と中山雅史選手の1967年生まれで、最年少選手は1993年生まれの月成大輝選手だそうです。この選手はある意味外れ値だとみることにしまして、1975年から1990年までのデータを利用したいと思います。実は先ほどの日本人の誕生日分布のデータは男女を合算したもので、Jリーガーには女性選手はいないという若干の不整合な点があります。そのために、このデータを使うための暗黙の仮定として、女性と男子では月別誕生日分布はそれほど変わらないという仮定を置いています。それでは、データフレームの7行から10行を取り出し、プロットしてみます。
> slice <- 7:10 > japrecent <- apply(data.japan[slice,], 2, sum)[-c(1,2)]/length(slice) > dev.new() > barplot(japrecent)
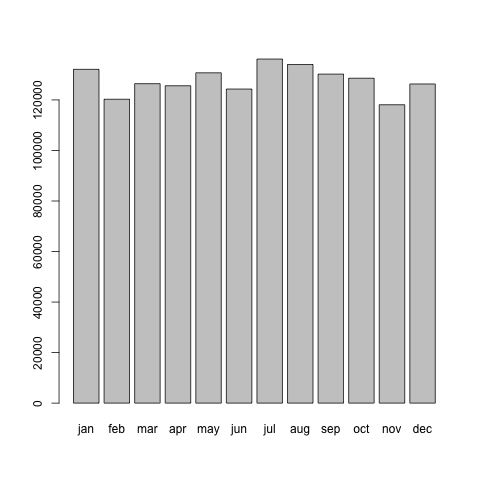
japrecentには1975年から1990年までの日本人の月別の出生数が入っています。data.japanから1975年から1990年までの行を切り出し、カラム方向で和をとるためにapply関数を利用してsum関数を適用しています(この説明については別の回でも繰り返しますので、理解できなくても大丈夫です)。この結果をbarplot関数によりプロットしました。
この日本人の1975年から1990年を合算した日本人の誕生月分布プロットと、Jリーガーの誕生月分布プロットをみると、やはりかなり異なるという印象があります。この定量的解析をこれから行ないます。
3/4 |
| Index | |
| Rは統計解析のブッシュナイフだ | |
| Page1 統計解析の必要性とリテラシー データが豊富に入手できる時代 Rで楽しく統計リテラシーを身に付ける グーグルでも使われているR | |
| Page2 連載の前口上と小理屈 何よりもまず、実践的な統計解析を体験してみる 誕生月によってJリーガーになりにくくなるのか? | |
| Page3 誕生月分布のプロット グラフの印象ではなく、定量的に議論するには |
|
| Page4 次回について 統計的検定を利用する | |
| Coding Edgeお勧め記事 |
| いまさらアルゴリズムを学ぶ意味 コーディングに役立つ! アルゴリズムの基本(1) コンピュータに「3の倍数と3の付く数字」を判断させるにはどうしたらいいか。発想力を鍛えよう |
|
| Zope 3の魅力に迫る Zope 3とは何ぞや?(1) Pythonで書かれたWebアプリケーションフレームワーク「Zope 3」。ほかのソフトウェアとは一体何が違っているのか? |
|
| 貧弱環境プログラミングのススメ 柴田 淳のコーディング天国 高性能なIT機器に囲まれた環境でコンピュータの動作原理に触れることは可能だろうか。貧弱なPC上にビットマップの直線をどうやって引く? |
|
| Haskellプログラミングの楽しみ方 のんびりHaskell(1) 関数型言語に分類されるHaskell。C言語などの手続き型言語とまったく異なるプログラミングの世界に踏み出してみよう |
|
| ちょっと変わったLisp入門 Gaucheでメタプログラミング(1) Lispの一種であるScheme。いくつかある処理系の中でも気軽にスクリプトを書けるGaucheでLispの世界を体験してみよう |
|
- プログラムの実行はどのようにして行われるのか、Linuxカーネルのコードから探る (2017/7/20)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。最終回は、Linuxカーネルの中では、プログラムの起動時にはどのような処理が行われているのかを探る - エンジニアならC言語プログラムの終わりに呼び出されるexit()の中身分かってますよね? (2017/7/13)
C言語の「Hello World!」プログラムで使われる、「printf()」「main()」関数の中身を、デバッガによる解析と逆アセンブル、ソースコード読解などのさまざまな側面から探る連載。今回は、プログラムの終わりに呼び出されるexit()の中身を探る - VBAにおけるFileDialog操作の基本&ドライブの空き容量、ファイルのサイズやタイムスタンプの取得方法 (2017/7/10)
指定したドライブの空き容量、ファイルのタイムスタンプや属性を取得する方法、FileDialog/エクスプローラー操作の基本を紹介します - さらば残業! 面倒くさいエクセル業務を楽にする「Excel VBA」とは (2017/7/6)
日頃発生する“面倒くさい業務”。簡単なプログラミングで効率化できる可能性がある。本稿では、業務で使うことが多い「Microsoft Excel」で使えるVBAを紹介する。※ショートカットキー、アクセスキーの解説あり
|
|
注目のテーマ





