仕組みを「見える化」してみた
アナハイムテクノロジー
はやしつとむ
2009/2/19
PageType=4:ポインタページ(Pointer Page)
PageType=4は、ポインタページです。各ポインタページはデータページに関する情報を保持しています。ポインタページは特定の<テーブル>(データベース上に作成されるテーブルです。本稿では以降、分かり難いので<>書きします)に関連付いていて、それぞれシーケンス(連番)で管理されているので、こうした情報も格納されています。
ポインタページのヘッダの追加情報としては、この<テーブル>上のシーケンス、この<テーブル>の次のポインタページのページ番号、ページ上の次の空きスロット、ページ上で使用されているスロット数、<テーブル>のリレーションID、未使用領域を持つデータページの情報を格納している最初のスロットのオフセット、同様に未使用領域を持つデータページの情報を格納している最後のスロットへのオフセットとなっています。
ポインタページは<テーブル>上で使用されているデータページのページ番号を示す32bitの整数の配列を含んでいます。
ポインタページの最後には、各データページのフィルレベル(データがどれだけ詰まっているか)を示すbit配列が格納されています。
●PointerPageの図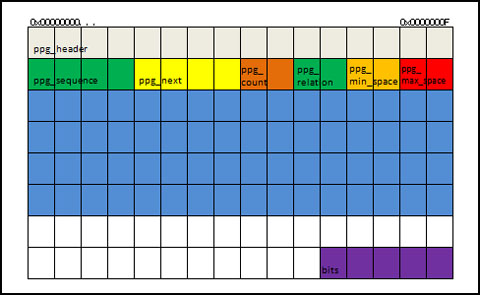
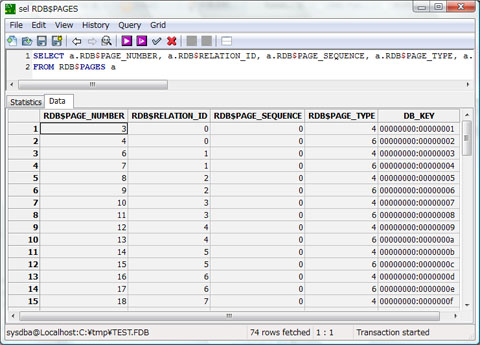
Firebirdがある<テーブル>の何らかのデータにたどり着くためには、データベースの先頭の固定位置に配置されているシステムテーブルから検索を開始します。そこからリレーションIDを介して、一番先頭にあるRDB$PAGESに保持されている各テーブルのポインタページをサーチし、そこからさらに、データページのページ番号を確認して、実際のデータにたどり着くというわけです。
●RDB$RELATIONS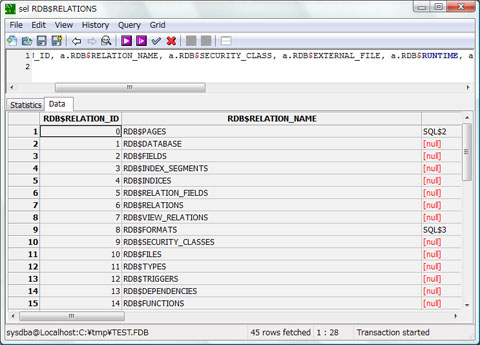
●RDB$PAGES
PageType=5:データページ(Data Page)
PageType=5は、データページです。各データページは特定の<テーブル>に関連付いています。つまり、1つのデータページに複数の<テーブル>は格納されません。
データページのヘッダの追加情報としては、<テーブル>に関連付いたデータページのリスト上での位置情報、<テーブル>のリレーションID、このデータページ上のエントリ数があります。
データページの中身としては、16bitのワードが、2つの配列から始まります。配列の1番目の要素は、ページ上のデータ(レコード・Blob・レコード断片)へのオフセットです。2番目の要素は、そのデータの長さです。このインデックスは、ページの上から下に埋められていきます。
逆に、データ(レコード・BLOB・レコード断片)自体は、ページの最後から始まって、上に向かって埋められていきます。ちょうど真ん中へ向かって両側から埋まっていく感じですね。
●DataPage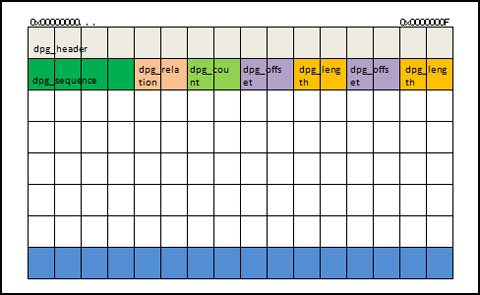
PageType=6:インデックスルートページ(Index Root Page)
PageType=6はインデックスルートページです。各<テーブル>には必ず1つのインデックスルートページが存在し、<テーブル>のインデックスの詳細が格納されます。Firebird 1.5以降のバージョンでは、このページにはIRT(どこにも資料がありませんが、Index RooTの略称のようです)に関する情報が格納されています。
インデックスルートページのヘッダの追加情報としては、リレーションID、<テーブル>に作成されているインデックス数があります。
インデックスページの中身としては、インデックスディスクプリタが上から下に向かって埋められていき、インデックスセグメントディスクプリタが下から上に向かって埋められていきます。
各インデックスディスクプリタはインデックスの選択(インデックスがすでに作成されている場合)またはトランザクションID(インデックスが作成中の場合)から始まります。続く32bitは実際のインデックスが格納されている最初のページのページ番号が入っています。その次は、ページの下部に格納されているフィールドディスクプリタへの32bitのオフセットです。そして、キーフィールドの数がbyteで入り、最後にフラグが付いています。
セグメントデスクプリタの配列には、1セグメント当たり2bytesが割り当てられます。1byteはフィールドIDでもう1byteはフィールドタイプです。
PageType=7:インデックスページ(Index<B-tree> Page)
PageType=7はインデックスページ(またはB-treeページ)です。
FirebirdのすべてのインデックスはB-treeの変種注4で、トップページから始まっています。インデックスのルートはこのトップページにあるわけですが、各<テーブル>にも別にインデックスルートページがあるので、ちょっとややこしいですね。インデックスルートページには各インデックスがどのインデックスページに格納されているかという情報が保持されているにすぎません。
B-treeページの追加のヘッダ情報としては、インデックスの同レベルで次に高い値を含むページ番号(right sibling)、同様に次に低い値を含むページ番号(left sibling)、圧縮されたプレフィックス(Firebirdはインデックスのプレフィックスも圧縮しています)が全体で使用しているbyte数、このインデックスが関連付けられている<テーブル>のリレーションID、このページで使用されているbyte数、このページが関連付けられているインデックスでのID、インデックス中でのレベル、などが含まれています。
ページの残りの部分は、インデックスのエントリで埋められています。
●インデックスページ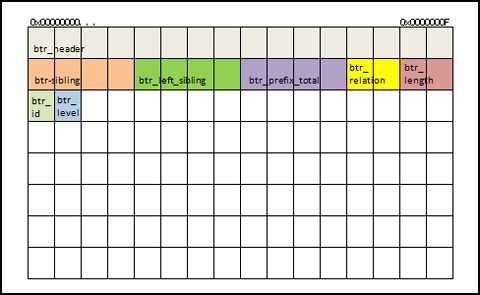
| 3/4 |
| Index | |
| 仕組みを「見える化」してみた | |
| Page 1 ・はじめに VisualODSの使い方 ISQLでサンプルデータベースを作成 |
|
| Page 2 PageType=2:ページインベントリページ(Page Inventory Page) PageType=3:トランザクションインベントリページ(Transaction Inventory Page) |
|
| Page 3 PageType=4:ポインタページ(Pointer Page) PageType=5:データページ(Data Page) PageType=6:インデックスルートページ(Index Root Page) PageType=7:インデックスページ(Index<B-tree> Page) |
|
| Page 4 PageType=8:Blobデータページ(Blob Page) PageType=9:ジェネレータページ(Generator Page) ・最後に |
|
| Yet another OSS DB:Firebird |
- Oracleライセンス「SE2」検証 CPUスレッド数制限はどんな仕組みで制御されるのか (2017/7/26)
データベース管理システムの運用でトラブルが発生したらどうするか。DBサポートスペシャリストが現場目線の解決Tipsをお届けします。今回は、Oracle SE2の「CPUスレッド数制限」がどんな仕組みで行われるのかを検証します - ドメイン参加後、SQL Serverが起動しなくなった (2017/7/24)
本連載では、「SQL Server」で発生するトラブルを「どんな方法で」「どのように」解決していくか、正しい対処のためのノウハウを紹介します。今回は、「ドメイン参加後にSQL Serverが起動しなくなった場合の対処方法」を解説します - さらに高度なSQL実行計画の取得」のために理解しておくべきこと (2017/7/21)
日本オラクルのデータベーススペシャリストが「DBAがすぐ実践できる即効テクニック」を紹介する本連載。今回は「より高度なSQL実行計画を取得するために、理解しておいてほしいこと」を解説します - データベースセキュリティが「各種ガイドライン」に記載され始めている事実 (2017/7/20)
本連載では、「データベースセキュリティに必要な対策」を学び、DBMSでの「具体的な実装方法」や「Tips」などを紹介していきます。今回は、「各種ガイドラインが示すコンプライアンス要件に、データベースのセキュリティはどのように記載されているのか」を解説します
|
|





