Viper 2で学ぶXMLデータベース最新事情(1)
なぜ彼はLAMPを捨てXML DBに走ったのか
日本アイ・ビー・エム
中林 紀彦
2007/10/22
■XMLデータベースという選択肢
今回のような問題を防ぐために、Kさんはどうすればよかったのでしょうか? 実はアーキテクチャの選択の際に、「この部分は迷うことなくLAMPを選択しました」とLAMPのアーキテクチャを使ってしまったことが、データベースの設計に関するさまざまな問題の原因でした。このようなケースではMySQL(リレーショナル・データベース)よりももっと向いているデータベースがあります。そうです、XMLデータベースです。
XMLデータベースはなぜ向いているのでしょうか? XMLデータベースはリレーショナル・データベースよりも変更に関して柔軟に対応できるからです。皆さんからは「XMLデータベースなんて数年前にはやったけど広まらなかったよね」とか、「XMLデータベースは知っているけど値段が高くてとても簡単には使えそうにないよ」といった声が聞こえてきそうですが、そんなことはありません。
IBMがリレーショナル・データベースに続く第3世代のデータベースとしてハイブリッド・データベースを世に出してからすでに1年以上が経過し、もうすぐDB2 Viper 2(DB2 9.5)と呼ばれる新しいバージョンも登場してきます(2007年10月31日より提供開始)。Viper 2では、「トランザクショナルXML」と呼ばれるように、専用のXMLストレージ(pureXML™)にさらに磨きをかけています(注3)。しかもDB2 Express-C 9という形でフリーで利用できるものも公開されていますので、これを利用することで、サービス開始時の投資を抑えることもできます。
| 注3:V8までのDB2を含む従来のリレーショナル・データベースでもXMLを扱うことはできましたが、既存のデータベースの機能を利用したいわば“暫定的”な対応方法でした。XMLの格納方法は大きく2種類あり、XMLをテーブルの各列にマッピングする、シュレッディング方式と、VARCHARやCLOBといった列にそのままの形で保管する方式の2種類の方法が採用されていました。どちらの方式もそれぞれ、柔軟性とパフォーマンスのトレードオフで、両方の長所を持った本当の意味でのXMLデータベースとは呼べませんでした。 参考:従来のXML格納方式「連載:DB2でXMLを操作する(1)」 |
■XMLデータベース(Viper 2)による実装
それでは、実際に先ほど紹介した例をViper 2を使って具体的に実装していってみましょう。
インストール
XMLデータベースといっても特別なことはありません。以下にダウンロードとインストールに関する情報を載せておきます。これを見れば簡単にダウンロードからインストールまで行えるでしょう。ちなみに筆者の環境(Red Hat Linux Enterprise Server 5にViper2 Open Betaをインストール)では5分程度でインストールが完了しました。
- ダウンロードサイト
DB2 Express-C 9
Viper2 Open Beta
- インストールに関する情報
DB2 9 入門
データベースの作成
これも通常のリレーショナル・データベースの作成となんら変わりはありません。ただし気を付けるべき点としては、データベースのコードページ(文字コード)です。Viper 2では、UTF-8以外の文字コードでもXML列を扱えるようになるのですが、現行バージョンDB2 9では、UTF-8のみXML列をサポートします。日本語を扱うケースでは、Viper 2以降でもUTF-8をお勧めします。これは、XMLの検索言語であるXQueryなどで日本語を扱う際に、UTF-8以外では問題となるコードがあるからです(これ以降のコマンド発行は、すべてデフォルトのインスタンス・ユーザー「db2inst1」で実行しています)。
$ db2 create database xmlsampl using codeset UTF-8 territory JP |
| リスト2 文字コードにUTF-8を指定したデータベースの作成 |
テーブルの設計・作成
さて、MySQL(リレーショナル・データベース)のケースでは課題の多かったテーブルの設計ですが、XMLデータベースについてはまったく悩む必要はありません。要件のあやふやな今回のようなケースに関しては、すべての項目をXML列で吸収してしまいます。
それではXMLを扱うために、XMLデータに対応したテーブルを作成しましょう。といっても特に難しいことはなく、XML列を通常のCREATE TABLE文で指定するだけです。
$ db2 connect to xmlsampl |
| リスト3 XML列を指定したテーブル作成 |
これでXMLが利用可能になりますので、試しにデータを挿入してみましょう。データの挿入には通常のINSERT文を使います。今回はXML列にXMLスキーマを指定していませんので、挿入するXMLは自由です。Well-formed(XML文書として整形されている)であることが唯一の条件です。ですので「すべての開始タグと終了タグが対になっている」「ルートとなるタグがほかのタグの入れ子になっていない」「入れ子になっているタグの終了タグが親タグの終了タグより後にこない」といった条件を満たしてさえいれば、XML列への挿入が可能になります。
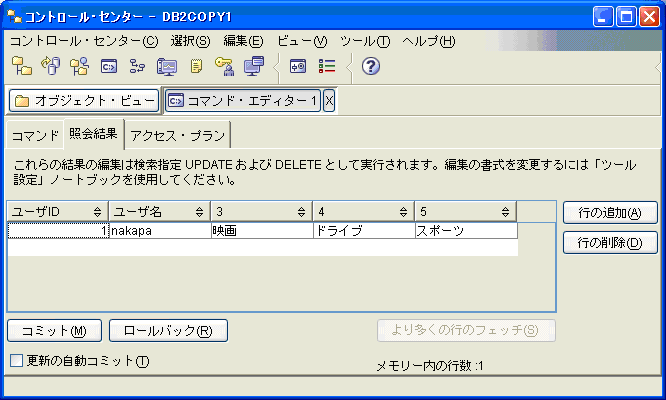
$ db2 "insert into xmluser values (1, '<ユーザ情報><ユーザID>1</ユーザID><ユーザ名>nakapa</ユーザ名><メールアドレス>nakapa@xxx.xxx.xxx</メールアドレス><姓>中林</姓><名>紀彦</名><都道府県>東京都</都道府県><住所>渋谷区</住所></ユーザ情報>')" |
| リスト4 XML列へのXMLデータ挿入 |
<ユーザ情報> |
| リスト5 リスト4で使用したXML |
要件の変更にも柔軟に対応
さてMySQL(リレーショナル・データベース)のケースでは、ここで要件の変更がありました。「興味」を追加する必要が出てきましたが、あせることはありません。データを変更すればすぐに対応可能です。
$ db2 "insert into xmluser values (1, '<ユーザ情報><ユーザID>1</ユーザID><ユーザ名>nakapa</ユーザ名><メールアドレス>nakapa@xxx.xxx.xxx</メールアドレス><姓>中林</姓><名>紀彦</名><都道府県>東京都</都道府県><住所>渋谷区</住所><興味>映画</興味><興味>ドライブ</興味><興味>スポーツ</興味></ユーザ情報>')" |
| リスト6 要件変更に対応したINSERT文 |
<ユーザ情報> |
| リスト7 リスト6で使用したXML |
いかがですか。XMLデータの柔軟さが理解できますね。テーブルの構造にはまったく変更を加えずに対応が可能になりました。この方法であれば、後からどんな項目が追加されてもすぐに対応が可能になります。また構築時だけではなく、サービスの途中でも簡単に変更が可能ですので、どんどん新しい機能を加えて、より良いシステムをつくっていくことが可能になります。
◇
さて、第1回はいかがだったでしょうか? 最近は、リレーショナル・データベースを使うことが常識のようになっていますが、そんなことはありません。今回のケースのように、要件が柔らかかったり、構築期間が非常に短いケースなどではXMLデータベースがその柔軟性を発揮してくれますので、無条件にLAMPを選択するのではなく、Viper 2などのXMLデータベースも選択肢の1つとして入れておいてください。
次回は、XMLデータを検索するための言語「XQuery」についてのお話です。XMLデータの検索には専用のXQueryが必要なのです。(次回へ続く)
問題の解答
|
| 2/2 |
| Index | |
| 連載:Viper 2で学ぶXMLデータベース最新事情(1) なぜ彼はLAMPを捨てXML DBに走ったのか |
|
| Page 1 ・いかにしてKさんは設計変更のワナにはまったか |
|
| Page 2 ・XMLデータベースという選択肢 ・XMLデータベース(Viper 2)による実装 |
|
| Viper 2で学ぶXMLデータベース最新事情 |
- Oracleライセンス「SE2」検証 CPUスレッド数制限はどんな仕組みで制御されるのか (2017/7/26)
データベース管理システムの運用でトラブルが発生したらどうするか。DBサポートスペシャリストが現場目線の解決Tipsをお届けします。今回は、Oracle SE2の「CPUスレッド数制限」がどんな仕組みで行われるのかを検証します - ドメイン参加後、SQL Serverが起動しなくなった (2017/7/24)
本連載では、「SQL Server」で発生するトラブルを「どんな方法で」「どのように」解決していくか、正しい対処のためのノウハウを紹介します。今回は、「ドメイン参加後にSQL Serverが起動しなくなった場合の対処方法」を解説します - さらに高度なSQL実行計画の取得」のために理解しておくべきこと (2017/7/21)
日本オラクルのデータベーススペシャリストが「DBAがすぐ実践できる即効テクニック」を紹介する本連載。今回は「より高度なSQL実行計画を取得するために、理解しておいてほしいこと」を解説します - データベースセキュリティが「各種ガイドライン」に記載され始めている事実 (2017/7/20)
本連載では、「データベースセキュリティに必要な対策」を学び、DBMSでの「具体的な実装方法」や「Tips」などを紹介していきます。今回は、「各種ガイドラインが示すコンプライアンス要件に、データベースのセキュリティはどのように記載されているのか」を解説します
|
|





