
XMLデータベース開発方法論(1) Page 4/4
序章、データ処理技法の地政学
川俣 晶
株式会社ピーデー
2005/6/28
XMLは、RDBとAWKの間に引いた線の中間に位置する点の1つとなる。
つまり、XMLとはRDBから見れば「不定型」寄りであり、AWKから見れば「定型」寄りの存在ということである。
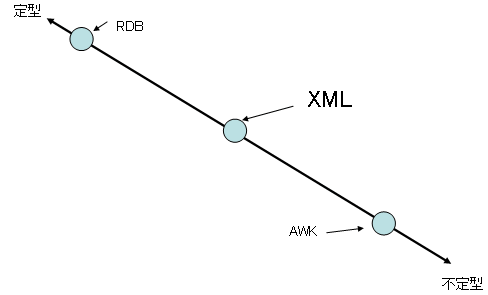 |
| 図6 XMLのポジション (注:雰囲気を把握するために単純化した説明図であって、内容は厳密に正確ではない) |
XMLが誕生したときに、「これだ!」と即座に飛びついたというのは、RDBとAWKの中間の、しかも絶妙にうまいポジションにそれがあったためだ。過去に、その点を占める技術はなかったので、まさに欲しかったものが出てきた、という印象だった。
しかし、なぜそれが欲しかったのだろうか。
筆者は、まずRDBに見捨てられた。RDBが、多品種・少量・不定型のデータをリーズナブルに処理してくれないことは、経験的によく分かっていた。そのニーズはAWKによって解消することはできたが、100%満足というわけではなかった。不定型のデータを処理できるのはよいのだが、込み入ったデータを扱うにはまるで意味不明の呪文のような複雑な正規表現を書かねばならず、それだけ努力をしても適切にデータとそれ以外を識別できないケースがあったからだ。
例えば、データを含むテキストから数値だけを抜き出そうとしているとしよう。以下のようなテキストから半角数字の列(ここでは「409」)を抜き出して数値として集計するなど、AWKを使えば難しくはない。
409円のコミックを啓文堂書店で購入しました。 |
しかし、以下のような文章が出てきたらどうなるだろうか。
100円ショップで、700円の買い物をしました。 |
この場合は「100円ショップ」のような単語の「100」も数値と認識してしまう誤動作もあり得る。もちろん正規表現を工夫すれば、「円ショップ」と続いたときには対象としないように記述することもできるが、このような例外は100円ショップ1つとは限らない。それらも扱うために、このような対処を繰り返していくと正規表現は扱いきれない怪物に成長してしまう。
これを回避するために、もっと厳密かつ簡易に対象を判定できるヒントを埋め込めないものだろうか、ということを考えていた。
XMLは、まさにこの目的にピッタリと思えた。この事例は、XMLを使うと以下のように記述できる(以下は厳密なものではなく、あくまでイメージとして見ていただきたい)。
<店名>100円ショップ</店名>で、<価格>700</価格>円の買い物をしました。 |
このようなXML文書を書くことができれば、価格だけ集計するために、もはや正規表現を工夫する必要はない。まさに「価格」と名付けられた要素の内容だけを集計すればよいわけである。価格要素や店名要素の導入は、完全に「不定型」であったデータ処理に、「定型」性を導入することにほかならない。
「定型」性の導入と同時に、全体として強い「不定型」性を残していることにも注目できる。RDBを使うときのように、テーブルを設計したり、データを正規化する必要はない。データの構造は変えずに、ヒントとなるタグを挿入しているだけである。
つまり、XMLとは、テキストでデータを記述するというAWK的テキスト処理の世界を継承しつつ、そこに要素や属性という構造を導入することで、自由を制約した言語であると見ることができる。自由の制約は、利用者がより少ない手間で成果を得られるようにするために導入される。しかし、自由の制約は最小限に抑えられ、RDBと同水準の高い秩序は要求していない。
念のために補足すると、XMLに対するこのような視点は、すべてのXML利用者の共通認識ではない。例えば、すべてのXML文書は厳格に規定されたスキーマに沿って記述されるべきであり、不定型の既存文章にタグを埋め込んだ程度でXML文書と称するのは間違っているという考え方もあり得る。しかし、本連載では私の体験をスタートラインにして一般論に展開していく手順を取る関係上、上記のような解釈でXMLを見ていくものとする。もちろん、このような視点とは別の多くのXMLを見る視点があることは、議論を展開する際には踏まえていく予定である。
図6の「XMLのポジション」によって、RDB、XML、AWKの関係を図で示してみたが、もちろんほかの雑多なデータ処理技術もこの直線上に描いてみることができる。これは、データ処理技法の位置付けを素早く把握するための、一種の「データ処理技法の地図」となる(これが今回の最も重要なポイントである)。
以下の図7は、本来は比較できない技術を1本の直線上に記述している。例えばAWKはプログラム言語だが、CSVはファイル形式である。ここでは、それらの名前で呼ばれる技術そのものではなく、それによって表現されるデータの構造や、それを用いて行うデータ処理などをすべて含めて着目した表現であると考えていただきたい。
 |
| 図7 さまざまな技術たち (注:雰囲気を把握するために単純化した説明図であって、内容は厳密に正確ではない) |
例えば、Excelをデータ処理に使う場合があるが、表は(特殊な機能を使わない限り)厳格に縦横に仕切られている。それにより、1つの行だけセルを1つ多く持つということはできない。その点では、要素にいくらでも子要素を付けることができるXMLよりも定型性が強いといえる。しかし、セルの内容には何を書き込んでもよく、整数と決めたら整数しか入れられないRDBと比較すれば不定型寄りと考えることができる。
例えば、CSVをデータ記述に使う場合があるが、これは大まかにいえばカンマ区切りでデータを記述したテキストファイルにすぎない。機能や制約は非常に少なく、1行当たりの項目数を増減することも明示的には禁止されていない……(と思うが、CSVには厳密な意味での仕様書が存在しないようなので、確実ではない)。そのような理由から、XMLよりも、より不定型寄りの技術であると考えてみた。
この図には、もう1つ、AWKよりも不定型寄りの技術として「手書き文書」というものを書いてみた。もちろん、何の制約もなく紙の上に書かれた文書は、非常に不定型である。途中まで1行だったはずの行が途中から2行に分かれていたり、行と関係なく書き込まれている文字もあるだろう。さらに、字が汚ければ、文字すら確実に判読できず、あいまいになる。前に、AWKが立っている場所を「不定型」処理と考えてみようと書いているが、これは便宜上、そのように考えてみようという意味であり、実際にはAWK以上に不定型なデータ処理はあり得る。同様に、RDBよりも厳格に「定型」性を求めるデータ処理もあり得る。
さて、話を本題に戻そう。
実はAWKの不満をXMLによって完全に解消することには失敗している。
それは、XMLの基本的なコンセプトが間違っているということではない。確かにXMLが存在することによって助かっている体験も多いのである。XMLが有益であることは間違いない。しかし、すべての問題を解決するには、まだまだ多くのハードルがある。
それらのハードルは、低レベルすぎるAPI(DOMやSAX)、手間がかかりすぎるタギング、テキストと区別できない構文上の空白、難解な変換言語(XSLT)などさまざまである。
これらの存在は、XMLを使ったデータ処理が、AWKによるデータ処理ほどシンプルでも気軽でもないことを意味する。しかし、これらはまだしも努力によって克服可能なハードルにすぎない。問題は、努力では克服できないハードルである。
では、努力では克服できないほど高いハードルとは何だろうか。
それは性能面での問題である。
もちろん、AWKには性能の問題などなかったのに、XMLには問題があるという話ではない。AWKと比較して、XMLは応用範囲が広がったことにより、性能の問題が顕在化したということである。つまり、応用範囲が広がるということは、より多様な使い方と、より多様なデータの記述に使われるということを意味する。そして、多様な使い方の中には処理速度が問題にされるものが含まれ、多様なデータの中にはより大量のデータが含まれる。つまり、XMLはAWKでは求められることがあまりなかった「速度」と「大容量」へのニーズにさらされているということである。
しかし、XMLは、AWKと同じくテキストデータとして記述される。テキストデータの処理は効率が悪く、性能を限界まで高めることが原理的にできない。もちろん、効率が悪くても、最近のPCの高速化の恩恵により、小容量データであれば速度が問題にされることは多くはない。しかし、大容量データを扱う場合、現在のPCの性能を持ってしても、圧倒的に性能不足といわざるを得ない。つまり、XMLの普及に伴って、大容量データの高速処理というニーズが発生したものの、原理的にXMLではそれを満たすことができないということである。
では、どのようなところに、高速大容量のXML応用ニーズがあるのだろうか。
まったく個人的な話をすれば、私が開発中のブログ機能を提供するWebアプリケーションの「MagSite1」がこれに相当する。開発中であるため、運用しながらデータ構造が変化していくことがある。そして、要求次第では不定型であったり例外的であったりする情報も扱わねばならない(お客さまは神様なのだ)。しかし、ブログのコンテンツを毎日書き込んでいけば、データの総量は徐々に増えていく。すでに3年ほど試験運用しているが、1日1コンテンツのペースで増えるとすれば、3年で約1000コンテンツとなる(実際にはすでに6000に近いコンテンツを抱えてテスト運用している)。これは、XMLによって迅速に処理するには、かなり重いデータ量といえるが、Webアプリケーションである以上、リクエストには遅くとも数秒以内に対応しなければならない。この問題に対処するために、MagSite1では非XML的なプログラミング・テクニックを多用して対処しているが、要するにトリックのようなデータ構造と大量の例外的処理コードによって成立している好ましからざるプログラムということになる。しかも、トリックと例外処理コードが多いということは、修正に弱くメンテナンス性が低いことを意味する。このようなソースコードは、熱血の精神抜きでは書けないし、可能なら避けたいものである。
このようなニーズは、MagSite1だけでなく、筆者が計画中のほかのソフトにも含まれる。特に、以前から作成したいと思っているToDoリスト管理ソフト(筆者好みの仕様にフルチューンされる)は、運用しつつ、ニーズが発生するごとに動的にデータ構造を変化させていくことを考えている。開発中だからデータ構造が変化するのではなく、変化することが通常の運用の一部となる。
そして、おそらくこのニーズは筆者1人のものではなく、同様のニーズがあちこちに多く潜在的に眠っているという予測も立てることができたのだが、その話題は今回ではまだ語られない。
個人的に筆者がいま切実に必要としているのは、変化に強く、不定型のデータも受け付けると同時に、高速大容量の処理を実現するデータ処理技術である。
XMLでそれが実現できれば理想であるが、テキスト処理の非効率性からそれはあり得ない。では、RDBを使えばよいのかというと、不定型のデータが常時加えられたり取り去られたりするような用途には、あまりに相性が悪すぎる。つまり、「定型・不定型直線」の上で見ると、依然としてニーズの位置はXMLの近くにあり、RDBからは遠く離れていることになる。これほど位置がかけ離れている技術を採用しても、スムーズに作業は進められない。
何かを犠牲にしなければ、このニーズは満たせないことは明らかである。
では何を犠牲として差し出せばよいのだろうか。
そのことを考えたときに「テキストデータである」というXMLの特徴を犠牲にすれば、XMLデータベースという選択肢があることに気付いた。
XMLデータベースを使えば、事前に予測できない不定型のデータが追加されるようなニーズに適合し、しかもテキストデータとして扱われるXML文書よりも、はるかに素早くデータを扱うことができる。テキストデータであることの長所(テキストエディタで見ることができる、など)は、失われるが、それはいつでもテキストデータに戻すことができるという機能で妥協するとしよう。また性能面で、XMLデータベースはRDBに勝てないことが予想されるが、マシンの限界を極めるほどの高速大容量処理はいまのところ想定していないので、これは不問に付そう。
そのような問題意識を持ち始めたころ、Xprioriという無償のXMLデータベース(「NeoCore XMS」の無償版)の存在を知った。偶然にも、その後すぐに、このソフトの評価解説的な仕事を行うことになり、大量のデータを登録したストレス・テスト的な使い方や、込み入ったXPath式を含むクエリを試みた。その結果、技術的観点からは十分にXMLデータベースは高い価値を発揮しそうだという手応えを得た。
そう。これが今回の結論である。今回の記事内に取り上げなかった技術を含め、筆者は自分が求めるニーズに合ったデータ処理の手段を探し求めてきた。その結果、多くの候補が脱落して、最後にXMLデータベースだけが残った。つまり、XMLデータベースを使うべきである、と思ったわけではなく、最後に残された唯一の希望としてXMLデータベースを使わざるを得ない、という立場に立たされたのである。であればこそ、なぜXMLデータベースを使わねばならないのか、そしてXMLデータベースからどのような価値を引き出すのかについて、人一倍シビアに見ているつもりである。
本連載は、XMLデータベースを大々的に肯定していくが、その背景にはこのようなシビアな認識がある。
今回は、XMLデータベースの必要性に到達して話は終わった。しかし、これはあまりに筆者固有の状況に依存した必要性にすぎない。次回と次々回は、筆者固有の条件に考察を加え、一般的に同様のニーズがどこにでもあり得ること、そのようなニーズが増えつつあることを示していく予定である。
より具体的にいえば、次回はXMLデータベースを選定するための条件となる「規模」というファクターについて解説したいと考える。「規模」は「データの量」といい換えてもよいが、XMLデータベースが適する条件と「規模」は強い関係があると考えている。規模が変われば性質も変化し、それを扱う最適な技術も変わるのである。これは工学の基本だと勝手に思い込んでいたのだが、IT業界では必ずしも常識ではないようなので、1回分を用いて丁寧に解説を行いたいと思う。つまり、スケーラビリティは常によいものであるという常識のカラを破る行為であるといってもよい。
なお、冒頭の「半熟英雄4」より引用したせりふには、実はXMLデータベースと関連する深い意味がある(そして、もしかしたら複雑系における「カオスの縁」とも関係がある……かもしれない)。それについては、おそらく連載の第3回あたりに明らかにすることができるだろう。(次回へ続く)
| 4/4 |
| Index | |
| XMLデータベース開発方法論(1) 序章、データ処理技法の地政学 |
|
| Page
1 ・本連載の目的 ・本連載の価値観「すべきである」対「せざるを得ない」 ・本連載のお約束 ・筆者の立場と議論の進め方 ・XMLデータベースの定義 |
|
| Page
2 ・ここがスタートライン、データ処理技法の個人史 ・対照的な2つのデータ表現方法 ・例外的処理こそが重要である |
|
| Page
3 ・AWK、使い捨てデータ処理の切り札 ・問題を認識する領域 |
|
| Page
4 ・RDBとAWKの中間ポイントに位置するXML ・さまざまな技術たち ・挫折、XMLはAWKの不満を解消し得なかった ・結末、そしてXMLデータベースへ ・次回予告 |
|
| XMLデータベース開発論 |
- Oracleライセンス「SE2」検証 CPUスレッド数制限はどんな仕組みで制御されるのか (2017/7/26)
データベース管理システムの運用でトラブルが発生したらどうするか。DBサポートスペシャリストが現場目線の解決Tipsをお届けします。今回は、Oracle SE2の「CPUスレッド数制限」がどんな仕組みで行われるのかを検証します - ドメイン参加後、SQL Serverが起動しなくなった (2017/7/24)
本連載では、「SQL Server」で発生するトラブルを「どんな方法で」「どのように」解決していくか、正しい対処のためのノウハウを紹介します。今回は、「ドメイン参加後にSQL Serverが起動しなくなった場合の対処方法」を解説します - さらに高度なSQL実行計画の取得」のために理解しておくべきこと (2017/7/21)
日本オラクルのデータベーススペシャリストが「DBAがすぐ実践できる即効テクニック」を紹介する本連載。今回は「より高度なSQL実行計画を取得するために、理解しておいてほしいこと」を解説します - データベースセキュリティが「各種ガイドライン」に記載され始めている事実 (2017/7/20)
本連載では、「データベースセキュリティに必要な対策」を学び、DBMSでの「具体的な実装方法」や「Tips」などを紹介していきます。今回は、「各種ガイドラインが示すコンプライアンス要件に、データベースのセキュリティはどのように記載されているのか」を解説します
|
|





