 |
| アプリケーションのギアを上げよう ― Visual Studio 2010でアプリケーションのパフォーマンス・チューニング ― 第4回 DBアプリケーションのパフォーマンス・チューニング 亀川 和史2011/11/15 |
|
Page1
Page2
|
業務用アプリケーションでは、リレーショナル・データベースを使用するアプリケーションが多いだろう。そこで今回は、データベース・アクセス・アプリケーションにおけるパフォーマンスの調査・チューニング方法および、パフォーマンスを考慮した設計に関して解説する。
本稿では、C#で記述したサンプル・プログラムを示す。
■ データ・アクセスについて
●LINQとストアド・プロシージャ
本稿では、LINQの中でもLINQ to Entities(Entity Framework)および、LINQ to SQLといった、データベース・アクセスを行うための機能に限って取り扱う。LINQ to Entitiesに関しては、「連載:ADO.NET Entity Framework入門」を、LINQ to SQLに関してはVisual Studio 2008時代の記事だが、「特集:C#プログラマーのためのLINQ超入門(後編)」を参照してほしい。LINQ to SQLに関しては.NET Framework 3.5 SP1と,NET Framework 4では大きな差はないが、MSDNライブラリの「.NET Framework 4への移行」に.NET Framework 4での変更点が記載されている。
LINQのデータ・アクセスは非常に便利である。以下のLINQ to Entities(C#)のコードは、CodePlexにおいて配布されているサンプル・データベース「AdventureWorks」のSalesOrderHeaderテーブル(下の図を参照)からSubTotal(合計)が1000以上のレコードを販売日で降順ソートして抽出するサンプルである。
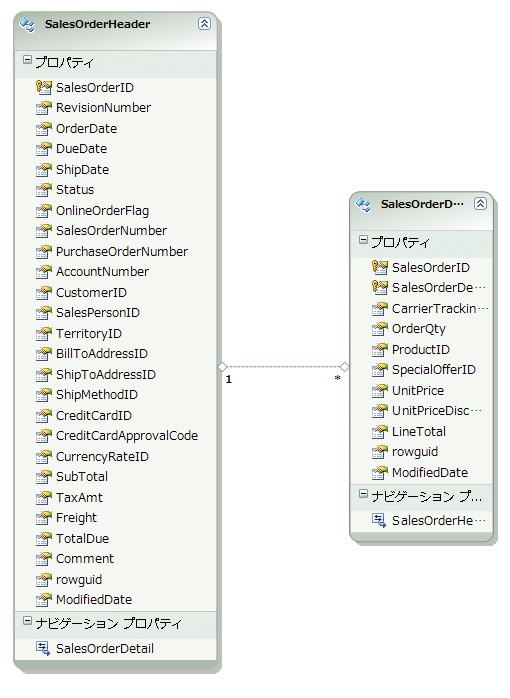 |
| SalesOrderHeaderテーブルのフィールド内容 |
|
|
| SubTotal(合計)が1000以上のレコードを販売日で降順ソートしたデータを抽出するLINQ to Entities(C#)コード |
上記のLINQ to Entitiesコードと同じ処理を、ストアド・プロシージャとADO.NETで書くと以下のようになる。
|
|
| SubTotal(合計)が1000以上のレコードを販売日で降順ソートしたデータを抽出するADO.NET(C#)コード |
|
|
| SubTotal(合計)が1000以上のレコードを販売日で降順ソートしたデータを抽出するストアド・プロシージャ(SQL)コード |
ちなみに、ADO.NETではなくとも、LINQ to Entitiesでストアド・プロシージャを呼び出すこともできる(参考:「第4回 データベースからのEntity Data Model生成」)。
2種類のデータ抽出方法を示したが、実はLINQ to Entitiesによるデータ抽出と、ADO.NETでストアド プロシージャによるデータ抽出では、それぞれの実行内容に少し違いがある。もちろん結果としてコンソールに出力されるデータは同じだが(下の画面はその出力例)、LINQ to Entitiesの場合、select句でエンティティ全体を指定しているため、ストアド・プロシージャ版と比べて、SQL Serverから転送されるデータ量は少し多くなる。
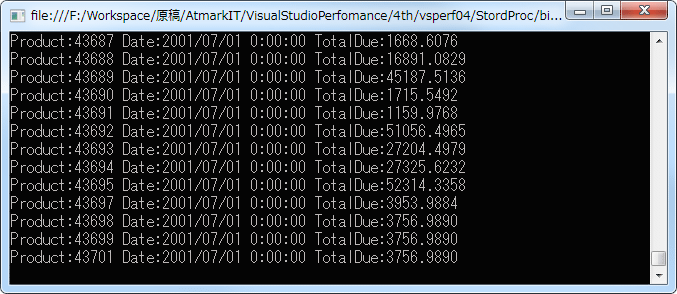 |
| LINQ to Entities版/ADO.NET+ストアド プロシージャ版のデータ出力結果の例 |
今回の例であれば、必要な列は「SalesOrderID」「OrderDate」「TotalDue」のみなので、LINQ to Entitiesの場合、select句で明示的にそれらの列のみを指定すると(次のコードを参照)、SQL Serverから転送するデータの量を削減できる。
|
|
| select句で明示的に必要な列のみを指定するLINQ to Entities(C#)コード |
select句で列を絞らない場合、実際にEntity Frameworkが発行するSQL文は下記のようになる。
|
|
| select句で列を絞らない場合の、Entity Frameworkが発行するSQL文の例 |
一方、select句で明示的に列を指定すると、Entity Frameworkは下記のようにかなりシンプルなSQL文を発行する。
|
|
| select句で明示的に列を指定した場合の、Entity Frameworkが発行するSQL文 |
例えば数件しか一致しないと分かっているようなクエリや、プライマリ・キーを使用した、必ず一件しか結果が返ってこないような検索であればそれほど問題にならないが、一覧を検索するようなアプリケーションではかなり差が付いてくる。特にSQL Azureを使用した場合などでは下りの転送量に対して課金されるので、無駄な転送が発生するクエリが頻繁に呼び出されると性能が悪く、使用料金も高いアプリケーションになってしまう可能性がある。
| 【コラム】LINQ to Entitiesが発行するSQL文を確認する |
LINQ to SQLにはLogプロパティがあったので、Logプロパティの内容をデバッガやConsole.WriteLineメソッドで出力すればよかった。しかし、Entity FrameworkにはLogプロパティは存在せず、ObjectQueryクラスにある、ToTraceStringメソッドを使用する。 例えば前述のLINQクエリ(=salesHeaderQueryオブジェクト)で発行されるSQL文を確認したい場合、以下のようなコードを記述すればよい。
上記のコードは最小限の処理のみ書いているが、適宜、メソッドに切り出すなどしてデバッグ時に役立ててほしい。 |
データ転送量は、SQL Server Management Studio(以下、SSMS)で調べられる。クエリを実行する際に、ツールバーにある[クライアント統計を含める]ボタンを押しておけば、実際にSQL Serverが転送するデータ量を実行結果の隣のタブに表示する。
以下の画面は、SSMSでストアド・プロシージャを呼び出したとき(=select句で対象列を絞っている場合)のデータ転送量である。
 |
||||||
| select句で対象列を「絞る」クエリを実行した場合のデータ転送量 | ||||||
| SQL Serverへのクエリ実行時のデータ転送量はSSMSで調べられる。 | ||||||
|
一方、select句で対象列を絞らないクエリを実行した場合の転送量は以下の画面のとおりとなる。
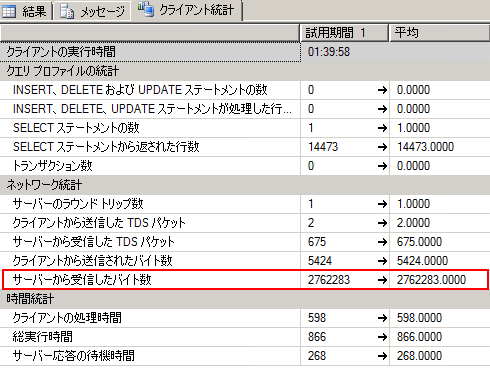 |
|||
| select句で対象列を「絞らない」クエリを実行した場合の転送量 | |||
| データ転送量はSSMSで調べられる。 | |||
|
このように、列を絞っている場合が297Kbytes、絞らない場合が2697Kbytesとなり、その差はほぼ9倍だ。この結果を見ると、多数のクライアントが、列を絞らないクエリを頻繁に実行すると、ネットワークの帯域不足により、性能低下が起きる可能性が高まることが理解できる。
LINQ to Entitiesに比べて、ストアド・プロシージャをADO.NETから呼び出すソース・コードは直感的に分かりづらい。しかし、それでもストアド・プロシージャの利用には以下のようなメリットがある。
-
データベースへのアクセスがデータベース・サーバ内に閉じ込められているため、データベース・サーバのアップグレードを行う場合のSQL文関連のチェックが局所化される。特にSQL Serverの場合、ストアド・プロシージャを暗号化していなければアップグレード・アドバイザで推奨されなくなる機能などがチェックされる
-
SQL Server側のチューニング・アドバイザで効率的ではないSQL文のチェックを容易に受けられる。SQL文の実行結果の統計も上記のように表示できる
-
SQL Server の場合、偽装を行うことにより、ストアド・プロシージャ実行中に限り、接続ユーザーよりも高い権限で動作させることができる。少し難しいが、MSDNにその記述がある(参考:「実行コンテキストについて」および「モジュールでの EXECUTE AS の使用」)
-
SQL Server固有のデータ型をはじめとした、データベース・システムの機能を有効に使用できる(Spatial型やhierarchyid型)。これらの型を活用できれば、今までプログラム側で面倒だった処理が。実はデータベース側の機能で実現できてしまうこともある
-
ストアド・プロシージャは、SQL ServerやOracle、DB2といった商用データベース・ソフトウェアだけではなく、MySQLやPostgreSQLといったオープンソースのデータベース・ソフトウェアでもサポートされている。もしも複数のデータベース・ソフトウェアをサポートする必要がある場合は、データベース・ソフトウェアごとにロジックの分離ができるため、ストアド・プロシージャの方が有利だろう(参考:「連載:VB研公開ゼミ議事録 第7回 ADO.NET開発初心者の疑問、解決します!」)
もちろんメリットばかりではなく、デメリットもある。以下に筆者が考える点を列挙する。
- データベース内にあるため、一般的にバージョン管理が面倒になる。ただし、Visual Studioのデータベース・プロジェクト、もしくはSSMSからデータベース・プロジェクトとして作れば、標準のソース管理プラグインでバージョン管理を行える(参考:「MSDN:ソース管理のオプションを設定する方法」)。次の画面は、ソース管理プラグインの設定をしているところ([オプション]ダイアログ)。
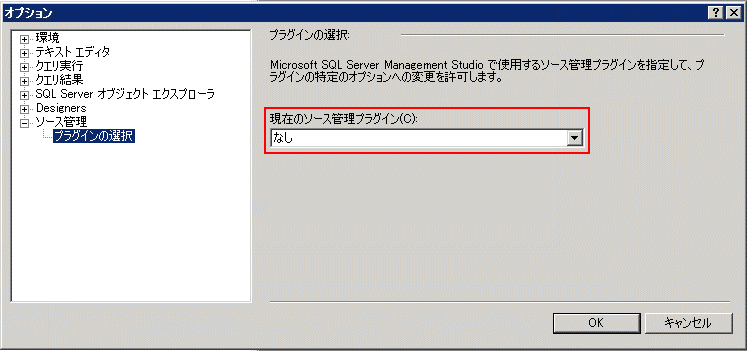 |
| ソース管理プラグインの選択 |
| TFSを使う場合は、Team Explorerのインストールが必要になる。 |
-
パラメータ部分の文字列を使って動的にSQL文を組み立てたり、ストアド・プロシージャ内で文字連結を使ったりして、「execute(string)」でSQL文を実行すると、SQLインジェクションが発生する(もちろん、ADO.NET経由でSqlParameterクラスなどを使わずに、文字列を組み立ててSQL文を実行する場合もSQLインジェクションは発生する)
-
本当に複数のデータベース・ソフトウェアに対応させようとすると、それぞれで多少文法の差や機能差があるので、実装に手間がかかる
-
効率的なSQL文を書くためには、かなりの熟練が必要
デメリットがやや少なそうに見えるが、パフォーマンスを出すためのSQL文は、記述がかなり難しいことが多い。また、ストアド・プロシージャがデータベースの中に入るため、バージョン管理がしにくいという理由で嫌う場合もあるが、有効に使えるので、ぜひ試してほしい。
続いて次のページでは、更新処理のパフォーマンス・チューニングについて説明する。
| INDEX | ||
| アプリケーションのギアを上げよう ― Visual Studio 2010でアプリケーションのパフォーマンス・チューニング | ||
| 第4回 DBアプリケーションのパフォーマンス・チューニング | ||
| 1.データ・アクセスについて:LINQとストアド・プロシージャ | ||
| 2.データ・アクセスについて:更新処理 | ||
| 「アプリケーションのギアを上げよう」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





