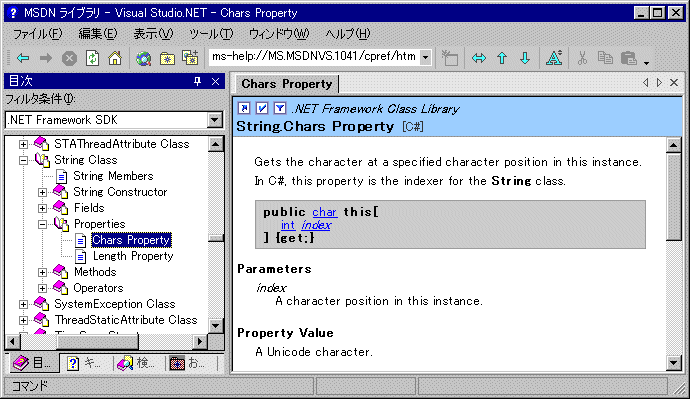
インデクサとは何か
まず、以下のサンプルソースを見ていただきたい。文字列を1文字ずつ表示するという機能を持ったプログラムである。
1: using System;
2:
3: namespace ConsoleApplication38
4: {
5: class Class1
6: {
7: static void Main(string[] args)
8: {
9: string s = "Hello!";
10: for( int i=0; i<s.Length; i++ )
11: {
12: Console.WriteLine( s[i] );
13: }
14: }
15: }
16: } |
|
| 文字列を1文字ずつ表示するサンプル・プログラム1 |
| 文字の配列にアクセスしているように記述しているが、実はインデクサにアクセスしている。 |
このプログラムを実行すると以下のようになる。
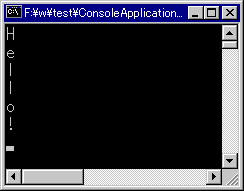 |
| サンプル・プログラム1の実行結果 |
| 文字列中の各文字を改行しながら出力する。
|
さて、このサンプルソースで注目すべき点は、12行目のs[i]と言う記述である。特に注意する必要があるのがC/C++/Javaプログラマである。C/C++/Javaの構文で考えれば、s[i]は配列の値を参照しているように見える。もちろん、C#でも、この構文は通常配列へのアクセスに使われる。しかし、[]でくくる構文は、配列へのアクセスにしか使われないものではない。実は、このサンプルソースでは、配列ではなくインデクサと呼ばれる機能へのアクセスに使われている。これは、C++でオペレータ[]をオーバーライドする場合と類似の機能なので、オペレータのオーバーライドを理解しているC++プログラマは容易に理解できるかもしれない。オペレータのオーバーライドの機能を持たないC/Javaに慣れているプログラマは要注意である。配列とインデクサは全く違う機能なので、両者を区別することはC#を理解する上で重要なポイントになる。
余談だが、配列にアクセスするC++(中身はほとんどC)のサンプルソースを以下に示す。
1: #include "stdio.h"
2: #include "string.h"
3:
4: int main(int argc, char* argv[])
5: {
6: char s[] = "Hello!";
7: for( int i=0; i<strlen(s); i++ )
8: {
9: printf( "%c\n", s[i] );
10: }
11: return 0;
12: }
13: |
|
| C++で記述した、配列にアクセスするサンプル・プログラム2 |
| C/C++では文字列は文字の配列としてアクセスすることができる。 |
このプログラムを実行すると以下のようになる。
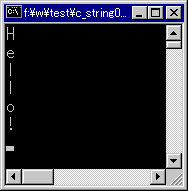 |
| サンプル・プログラム2の実行結果 |
| 文字列中の各文字を改行しながら出力する。
|
このサンプルソースの9行目に記述されているs[i]は、配列へのアクセスである。C/C++では、文字列は文字の配列として表現されているので、文字列は常に配列そのものである。C#では、文字列は文字列型のオブジェクトであり、配列とは違うものなので、最初のサンプルコードのs[i]とは機能的に異なっている。見かけは同じに見えるので注意が必要である。
さて、インデクサとはいったい何だろうか? インデクサが提供する機能とは、「あたかも配列変数にアクセスするかのようなソースコードを記述することで、ユーザーがあらかじめ記述したコードを実行させる機能」と言える。上記の例であるs[i]の場合、パッと見ると、sという配列変数のi番目の要素を取り出しているように見える。しかし、sは、string(System.Stringクラスの別名)型であるので、配列ではない。インデクサの機能が、文字列型のオブジェクトを配列であるかのように見せかけているのである。そして、インデクサにアクセスすると、配列にアクセスする代わりに、リファレンス・マニュアルに記載された以下の機能が呼び出されているのである。残念ながらベータ2の段階では、日本語に未翻訳の項目のようで英語になっているが、要するにCharsという名前だがC#ではインデクサとして実装される、と書かれている。
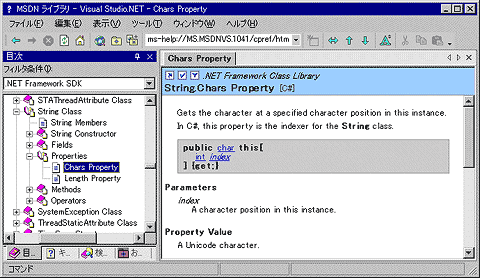 |
| クラス・ライブラリのリファレンス・マニュアル |
| これを見ると、Stringクラスには指定した位置の文字を取得するためのインデクサであるプロパティを持っていることが分かる。
|
このように、.NET Frameworkのクラス・ライブラリ・リファレンスの中には、名前が付いているにもかかわらず、C#ではインデクサとして実装されているものが多く見られる。そのため、インデクサを知らずにC#プログラミングはできないと思ってよいだろう。
インデクサと配列の違い
インデクサと配列の違いを、もっと具体的に調べてみよう。以下のサンプル・ソースコードでは、ほぼ同じ情報をインデクサと配列で表現してみた。なお、配列の詳細は、後でまた詳しく説明する。今は、だいたいこんなものかと思っておいていただきたい。
1: using System;
2:
3: namespace ConsoleApplication39
4: {
5: class Class1
6: {
7: static void Main(string[] args)
8: {
9: string s = "Hello!";
10: char [] a = { 'H', 'e', 'l', 'l', 'o', '!' };
11: Console.WriteLine( a.GetUpperBound(0) );
12: //Console.WriteLine( s.GetUpperBound(0) ); // 'string' に 'GetUpperBound' の定義がありません。
13: Console.WriteLine( s.ToUpper() );
14: //Console.WriteLine( a.ToUpper() ); // 'System.Array' に 'ToUpper' の定義がありません。
15: Console.WriteLine( s.GetType().FullName );
16: Console.WriteLine( a.GetType().FullName );
17: }
18: }
19: } |
|
| インデクサと配列の違いを示すサンプル・プログラム3 |
| C/C++では基本的に文字列と文字の配列はイコールであったが、C#ではまったく異なる。 |
このプログラムを実行すると以下のようになる。
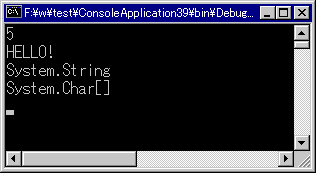 |
| サンプル・プログラム3の実行結果 |
|
文字列はSystem.String型、文字の配列はSystem.Char[]型になっているのが分かる。
|
このサンプルソースでまず注意していただきたいのが、9〜10行目である。9行目では文字列、10行目では文字の配列が宣言されている。C/C++では基本的に文字列と文字の配列はイコールであったが、C#ではまったく別個の方法で宣言されていることが分かるだろう。次に注目していただきたいのは、11〜14行目である。コメントアウトされている行は、入れるとエラーになる行である。11〜12行目では、GetUpperBoundというメソッドを呼んでいるが、これは、配列の上限の添え字の値を返すものである。配列aには適用できるが文字列sには適用できない。文字列を扱うSystem.Stringクラスにインデクサは存在するが、GetUpperBoundメソッドは存在しないのである。同じように、13〜14行目では、文字列には大文字に直すToUpperメソッドがあるが、配列の機能を定義するSystem.ArrayクラスにToUpperメソッドは存在しないことを示している。
実際に、15〜16行目のコードで、それぞれの厳密な型の名前を表示させているが、sはSystem.Stringで、aはSystem.Char[](charの配列のフルネーム)となっており、全く別個のデータ型(クラス)として扱われていることが分かると思う。つまり、インデクサによって配列のようにアクセスできるクラスがあるからと言って、そのクラスが配列の持つ全機能を使えるわけではないのである。
Insider.NET 記事ランキング
本日
月間