|
連載 .NET&Windows Vistaへ広がるDirectXの世界 第1回 DirectXの真実 NyaRuRu2006/06/21 |
 |
|
|
|
■ドライバ・モデル
Direct3DのAPIは、登場以来ずっとステート・マシン方式を採用している。DirectXには数十から数百の描画ステートが存在し、描画命令を発行した時点での設定によって描画結果が変化する。
パフォーマンス上の理由から、ステートの変更や描画命令はバッチ処理が基本となる。バッチ化が有効な理由は主に2つあり、描画処理をまとめてドライバに転送することでプロセスがカーネル・モードに遷移する回数を減らすことと、ドライバ以下のレベルで行われるキューイングによってGPUにアイドル時間をつくらないことである。
DirectX 2で導入されたDirect3D(初代)では、ドライバ呼び出しに用いるバッチの作成はプログラマーの仕事であった。DirectX 2での描画設定の変更や描画命令には対応するバイト・コードが定義されていて、これを実行バッファと呼ばれる専用の領域に格納し、APIを呼ぶことで順番に実行していく。まるでネットワーク通信のようなこの仕組みは、複雑かつ煩雑であるとして開発者には不評であった。
これを受けて、DirectX 5ではDrawPrimitiveと呼ばれる描画APIやSetRenderStateと呼ばれるステート変更APIが用意された。実際にはDirectXランタイム・ライブラリが開発者の代わりにドライバ呼び出しをバッチ化してくれる。開発者が呼び出したSetRenderStateはいったんランタイム・ライブラリ内にキューイングされ、DrawPrimitiveが呼び出されたタイミングでまとめて渡される。
現在Windows XPやWindows Server 2003で使用されているDirectXのドライバ・モデルは、Windows 2000に合わせて登場したDirectX 6がベースである。
DirectX 6以降は描画コマンドのキューイング先はコマンド・バッファと呼ばれるようになり、DrawPrimitive APIに対応する描画コマンドもキューイングが行われる。API呼び出しの結果コマンド・バッファがいっぱいになると、DirectXランタイム・ライブラリはドライバの関数をコールバックしてコマンド・バッファの処理を要請する。
プロファイラを用いて1回のDrawPrimitive APIの呼び出し時間を計測すると大抵はかなり低い値が得られるが、コマンド・バッファのフラッシュが発生した場合(バッファが空になる場合)は1回の呼び出しである程度の時間ブロックされるように見える。実効スループットを考えるときはフラッシュ時の所要時間も考慮に入れる必要がある。
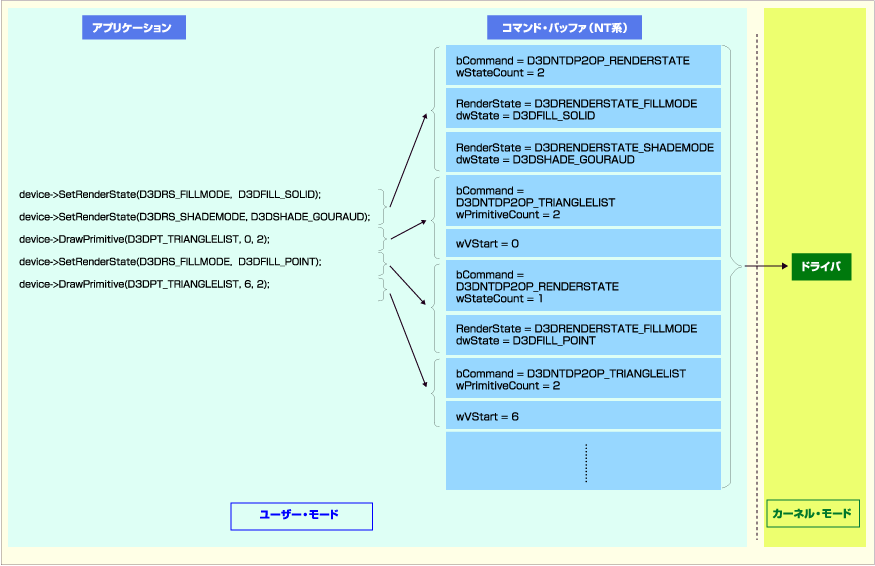 |
| DirectX 6以降におけるコマンド・バッファへの描画コマンドのキューイング |
また、DirectXランタイム・ライブラリによる変換レイヤが1段存在することは、DirectXのアップデートという面でも比較的大きな意味を持っていた。
アプリケーションから見たDirectXの変更は、ハードウェアの新機能への対応と、プログラミング・モデルの整理という点でAPIの変化である。しかし、ドライバ・モデルで見ればWindows 2000&DirectX 6以降は基本的に同じ仕組みが使用されており、新機能の追加は主に新しいコマンドの追加によって対応されてきた。DirectX 8用のドライバで、制限付きながらDirectX 9のアプリケーションを動かすことが可能なのはこのためだ*8。
| *8 Windows Vistaで導入されるDirectX 10では、ドライバ・アーキテクチャからの大幅な変更が予定されており、そのドライバ・モデルはWindows Vista専用になる見込みである。 |
他方、最近の環境ではドライバ層以下でも比較的長大なパイプライン処理が行われている。マイクロソフトは、ドライバに対する画面更新命令がウィンドウ当たり最大3回までキューイングされることを許している*9。このような巨大なバッファリングは、GPUのアイドル時間をつくらないという意味と、パイプラインのレイテンシ増加を隠ぺいするという2つの意味がある。
| *9 DirectX 10の3DグラフィックスAPIであるDirect3D 10では、IDirect3DDevice9Ex::SetMaximumFrameLatency APIによって画面更新の最大キューイング回数をアプリケーションから変更できるようになる。 |
次の図は、アプリケーション/GPU/画面表示のタイミングにそれぞれ時間差があることを示したものである。ハードウェアが大きなレイテンシを持っていたり、特定のフレームで瞬間的にGPUの処理量が増加したりしても、スループットの低下が小さく収まるが、リアルタイム性の強いゲームなどでは応答性が悪化するという側面もある。
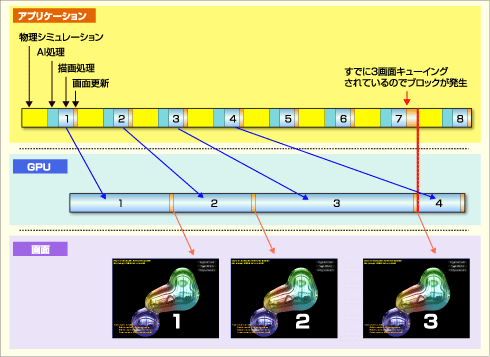 |
| アプリケーション/GPU/画面表示の時間のずれ |
■ボトルネック
コマンド・バッファのフラッシュは、CPUによってスループットが決定される部分である。1回のフラッシュでGPUに投入される仕事量は、コマンドの内容によって数ポリゴンから数万ポリゴン、あるいは数ピクセルから数百万ピクセルと非常に大きな広がりがある。
つまり、描画コマンド当たりの平均GPU負荷が小さすぎると、コマンド・バッファのフラッシュにCPUの空き時間すべてを費やしてもGPUの性能をすべて引き出せないことになる。
実は数年前からマイクロソフトや各GPUベンダは「CPUがボトルネックとなる」可能性について何度も開発者に注意を促している。3年前のGDC(Game Developers Conference) 2003で用いられたスライドでは、NVIDIA GeForce2 MX(ビデオ・カード)とAthlon XP 2700+(CPU)という組み合わせでさえ、1回の描画で130ポリゴン以上の仕事を投入しない限りGPUの最大スループットが実現できないという事例が示されている。
|
【「CPUがボトルネックとなる」可能性についての関連文献】 |
仮にCPU時間のほぼ100%を描画命令の発行に費やしている状態を基準に取れば、1回当たりの平均仕事投入量を100倍にすることでCPU使用率は1%にまで低下すると予想される。実際この傾向はベンチマーク結果に見ることができる。
以下に代表的な3Dベンチマーク・ソフト「3DMark06」のBatch Size Testsの結果を示す。
テスト環境はThinkPad T60(Intel Core Duo T2500、ATI MOBILITY RADEON X1400)で、CPUクロックを変化させたときの、描画命令1回当たりのポリゴン数(Triangles/Call)と1秒間に表示できるポリゴン数(Throughput (M Triangles/sec))の相関を示している。
| Triangles/Call |
Throughput (M Triangles/sec)
|
|
|
CPU@2GHz
|
CPU@1GHz
|
|
|
8
|
13.078
|
6.818
|
|
32
|
50.934
|
25.898
|
|
128
|
60.431
|
60.431
|
|
512
|
60.69
|
60.684
|
|
2048
|
73.09
|
73.071
|
|
32768
|
73.896
|
73.873
|
| 描画命令1回当たりのポリゴン数と1秒間に表示できるポリゴン数の相関(3DMark06のBatch Size Testsの結果) | ||
これを1秒間の描画回数(Throughput (M Calls/sec))に直してみたのが次の表だ。
| Triangles/Call |
Throughput (M Calls/sec)
|
|
|
CPU@2GHz
|
CPU@1GHz
|
|
|
8
|
1.635
|
0.852
|
|
32
|
1.592
|
0.809
|
|
128
|
0.472
|
0.472
|
|
512
|
0.119
|
0.119
|
|
2048
|
0.036
|
0.036
|
|
32768
|
0.002
|
0.002
|
| Batch Size Testsの結果を1秒間の描画回数に直した結果 | ||
| 3DMark06のテストでは実際には描画ごとにステート変更も行われているため、ステート変更のコストも影響していることに注意。 | ||
それぞれのCPUクロックで8 Triangles/Callと16 Triangles/Callの結果が一致しているのは、CPU時間のほとんどがコマンドの投入処理に費やされ、そこがボトルネックになっているためと考えられる。この予想から導かれる筆者の環境の描画回数は、1GHzのCPUの場合、1秒当たりにおよそ80万回が限界ということになる。
1秒間に最大何回の描画を実行できるか分かったので、これで割り算することで描画命令の発行に費やされるCPU時間を見積もることができる。こうすることで32 Triangles/Call以上でもCPUクロックの変更による影響が予想できる。
| Triangles/Call |
CPU Usage for Rendering
|
|
|
CPU@2GHz
|
CPU@1GHz
|
|
|
8
|
100.0%
|
100.0%
|
|
32
|
97.4%
|
95.0%
|
|
128
|
28.9%
|
55.4%
|
|
512
|
7.3%
|
13.9%
|
|
2048
|
2.2%
|
4.2%
|
|
32768
|
0.1%
|
0.3%
|
| 描画命令の発行に消費されるCPU時間 | ||
8 Triangles/Call(=描画命令1回当たりのポリゴン数が「8」)のときは、CPU時間を100%消費するにもかかわらず、GPUはトップスピードの20%以下の性能しか出せていない。一方で32768 Triangles/Call(=描画命令1回当たりのポリゴン数が「32768」)のときは、1%以下のCPU時間でGPUのトップスピードを実現している。
一般に、凝った画面はそれだけ重いだろうという印象を受けやすい。Windows Vistaの3Dを利用したデスクトップについて、「きっとシンプルな方がCPU負荷は軽いに違いない」と考えるのも仕方がないかもしれない。しかしこのベンチマーク結果は、出力結果の画面の複雑さではなく描画命令数が大きくCPU時間に影響し得ることを示している。
例えば、1000個のアイコンを一度に描画する方法と、100個のアイコンを1つ1つ描画する方法では、CPU使用率という点ではパフォーマンスの逆転が起きても不思議はないということだ。CPU視点での描画コストを、描画結果である画面内容から推し量るのは案外に難しい。
3. まとめ
DirectXはその知名度とは裏腹に、「なぜ動くのか」という点はほとんど知られていないように思う。DirectXの紹介記事の多くはハードウェア性能や3Dの新技術については重点的に説明を行うが、注目しているパフォーマンス指標そのものの意味やアーキテクチャの長期的変化のトレンドといった基本的な部分についてはかえって説明が不足しているように感じられる。本記事が、DirectXの印象と現実のギャップを取り除く一助になれば幸いである。
今回はDirectXの「高速」がどういうものであるか見ていただいた。次回ではDirectXのソフトウェア開発がどういう方向に向かっているかについて解説する。![]()
| INDEX | ||
| .NET&Windows Vistaへ広がるDirectXの世界 | ||
| 第1回 DirectXの真実 | ||
| 1.DirectXとは? | ||
| 2.高速描画の裏事情(1) | ||
| 3.高速描画の裏事情(2) | ||
| 「.NET&Windows Vistaへ広がるDirectXの世界」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





