|
SQL Serverのロック管理 マイクロソフト コンサルティング本部 赤間 信幸2005/03/01 |
|
|
|
 .NETエンタープライズ
.NETエンタープライズ2.1.2 SQL Serverの内部構造とロック対象となるリソース
SQL Server内部でロックの対象となりうるリソースには、データベースやテーブル、エクステント、ページ、行識別子(RID)、インデックスキーといったものがある。SQL Server EnterpriseManager(SEM)を利用すれば、現在、SQL Server上に立てられているロックの一覧を簡単に参照できる(図2-4)。
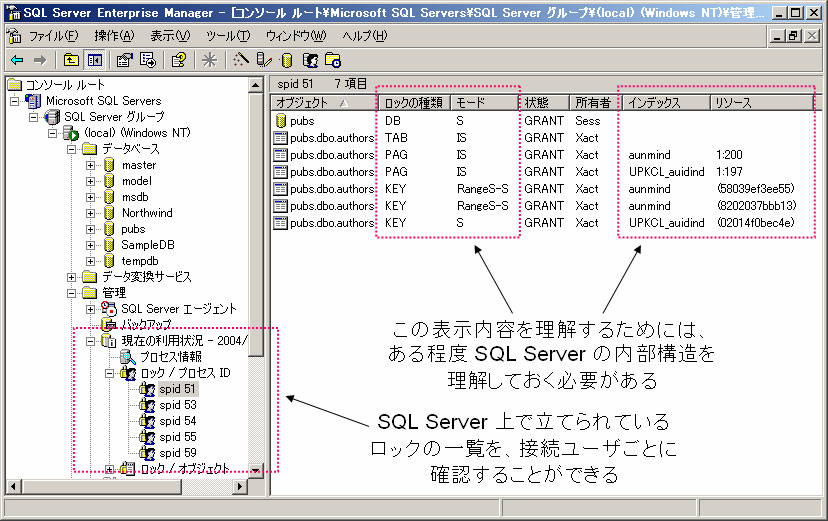 |
| 図2-4 SQL Server Enterprise Managerによるロックの確認画面 |
この画面の内容を正しく理解するためには、ある程度SQL Serverの内部構造について理解しておく必要がある。SQL Serverに添付されているpubsサンプルデータベースを例に取って、以下に簡単にSQL Serverの内部構造を解説する。以降の説明はやや難解かもしれないが、よく分からないという方もとりあえずは読み進めて頂きたい。環境をお持ちの方は、SEMやクエリアナライザを実際に利用して、動作を確認しながら進めていくとよいだろう。
A. データベースの論理構造と物理構造
pubsデータベースは、内部にauthorsテーブルやtitlesテーブルといった複数のテーブルを持っている。そして、各テーブルには検索を高速化するためのインデックスが張られている。例えば著者データを含むauthorsテーブルの場合には、主キーであるau_idの列と、名前を表すau_fnameとau_lnameの列に対してそれぞれインデックスが張られている。これらのインデックスにより、検索処理が高速化されるようになっている※5(図2-5)。
| *5 テーブルに張られているインデックスは、SEM上から確認することができる。 |
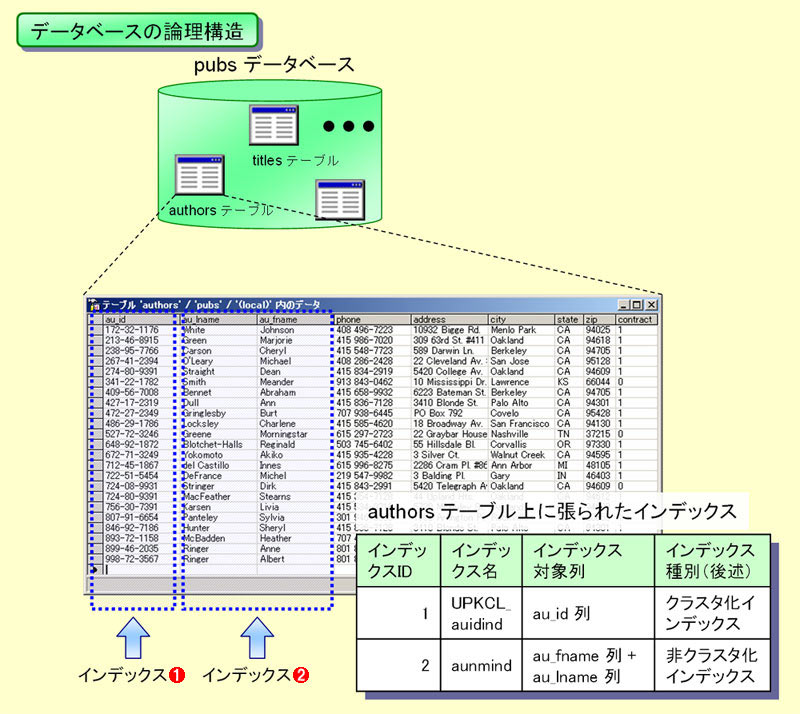 |
| 図2-5 pubsデータベースの論理構造 |
さて、図2-5に示したのはエンドユーザから見えるデータベースの論理構造である。実際には、これらのデータは内部処理に最適化された形で、拡張子.mdfの物理的なファイルに格納されている。図2-6にこの物理構造を示す。このデータベースファイルの中はさらにページと呼ばれる8KB単位の領域に切られており、各ページにはテーブル上のデータやインデックス情報などが格納されるようになっている。
 |
| 図2-6 pubsデータベースの物理構造 |
直感的には、テーブル上のレコードデータとインデックスは内部で別々に格納されているように思われるかもしれないが、多くの場合、レコードデータ(実データ)はインデックスと合体した形でデータベースファイルに格納されている。これを理解するためには、SQL Serverのインデックス構造について理解する必要がある。ここではauthorsテーブルを例に取って解説しよう。
B. クラスタ化インデックスと非クラスタ化インデックス
SQL Serverのインデックスは、論理的には図2-7のようなBツリー構造と呼ばれる木構造を持っている。Bツリー構造の各ノードは8KBの固定サイズとなっており、各ノードは図2-6に示した物理ファイルの各ページにそのまま格納されるようになっている。
SQL Serverには、クラスタ化インデックスと非クラスタ化インデックスと呼ばれる2種類のインデックスが存在する。図2-5に示したように、authorsテーブルにはこれら2種類のインデックスの両方が張られているが、これらには以下のような違いがある。
 |
| 図2-7 SQL Serverのインデックスの物理構造 |
| ・ クラスタ化インデックス | |
| ・ テーブル上の各行の実データが、リーフレベルのページ上に直接格納される特殊なインデックス。 | |
| ・ 通常は、図2-5のauthorsテーブルの例のように、各テーブルの主キーに対して張られるインデックスをクラスタ化インデックスとして設定する※6。 | |
| ・ 当該テーブルの実データを保有することになるため、クラスタ化インデックスは各テーブルに対して1つしか設定することができない。 | |
| ・ 非クラスタ化インデックス | |
| ・ 純粋なインデックス情報のみを含むインデックス。非クラスタ化インデックスのリーフレベルには実データは格納されていない。 | |
| ・ そのかわりにクラスタ化インデックスのキー(多くの場合は当該テーブルの主キーの情報となる)がポインタ情報として格納されている※7。このポインタ情報はブックマークと呼ばれている。 | |
| ・ 非クラスタ化インデックスは、各テーブルに対して複数設定することができる。 | |
| *6 主キー制約に従属するインデックスは、デフォルトでクラスタ化インデックスとなる。 |
| *7 当該テーブルにクラスタ化インデックスが存在しない場合には、RID(行識別子)がポインタ情報として格納される。本書では解説が複雑化するのを避けるため、テーブルにクラスタ化インデックスが存在しない場合については取り扱わない。興味がある方は、以下の資料を参照のこと。『アーキテクチャ徹底解説Microsoft SQL Server 2000』(日経BPソフトプレス)の「第8章 インデックス」。 |
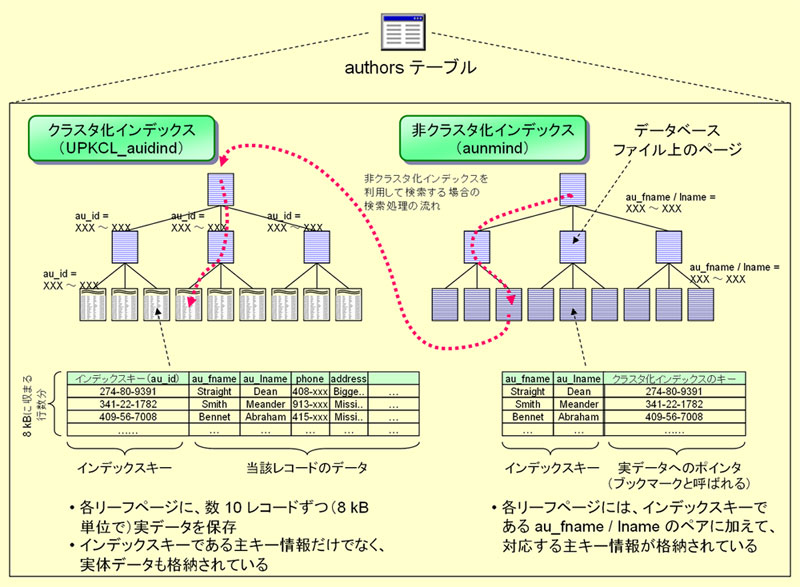 |
| 図2-8 authorsテーブルの内部構造 |
図2-5に示したauthorsテーブルのインデックス構造のイメージを図2-8に示す。
多少複雑だが、キーポイントは以下の2点のみである※8。とりあえずこの点を押さえておけば、SEMのロックに関する情報を理解することはできるだろう。
-
テーブル内の実際の各行のデータは、クラスタ化インデックスのリーフページに格納されている。
-
データベースの物理ファイルの内部では、ページと呼ばれる領域にインデックスデータやレコードデータが保存されている。
|
*8 ここに示したポイントは、 |
C. インテントロック
先に述べたように、SQL Serverは主に3種類のロック(共有ロック、更新ロック、排他ロック)を利用する。これらのロックは以下のようなリソースに対して実施される。
-
クラスタ化インデックスのインデックスキー(=実際のレコードそのもの)
-
クラスタ化インデックスのリーフページ
-
非クラスタ化インデックスのインデックスキー
-
非クラスタ化インデックスのリーフページ
-
テーブル
一例として、authorsテーブルに対して以下のようなクエリを投げた場合に発生するロックを調べてみよう※9。まずデータベースに接続し、図2-9のようにクエリアナライザからリスト2-1のようなSQL文を実行する。そして、SEM上から発生しているロックを確認してみると※10、図2-10のようになる※11。
|
|
| リスト2-1 ロック対象のリソースを確認するためのサンプルクエリ |
 |
| 図2-9 クエリアナライザからのSQL文の発行 |
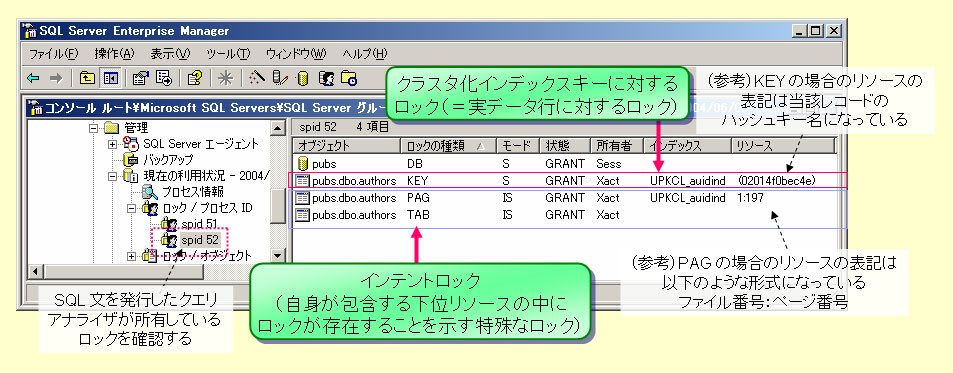 |
| 図2-10 リスト2-1によってSQL Serverが実施したロック |
| *9 ここではREPEATABLE READ分離レベルを利用しているが、分離レベルによるロックの挙動の違いについては後で詳細に解説する。 |
| *10 SEM上の[管理]−[現在の利用状況]−[ロック/ プロセスID]の項から調べることができる。なおこのロックの状態から確認できるデータは、ある瞬間のスナップショットとなる。このため、最新のデータを確認したい場合には、[現在の利用状況]の項を右クリックして、リフレッシュする必要がある。 |
| *11 確認作業が終わったら、後の演習のために、クエリアナライザ内のすべてのウィンドウを閉じて、トランザクションを解放しておいて頂きたい。 |
図2-8に示したように、UPKCL_auidindインデックスはクラスタ化インデックスであり、実データ行そのものを含む。このことから、図2-10のうち、最初に示されているUPKCL_auidindインデックスキーに対するモードSのロックは、テーブル上にある実データ行に対する共有ロック(SLock)であることが分かる。
しかしこのSQL処理では、さらにこのインデックスキーを含むページやテーブルに対しても、モードISのロックがかかっている。このロックはインテントロックと呼ばれる特殊なロックで、自分自身に含まれる下位リソースの中に、ロックされているものがあることを示すフラグになっている。
ページやテーブルに対してインテントロックと呼ばれる特殊なロックがかかるのは、以下のような理由による。
まず、SQL Serverでは行単位にロックをかけることが可能であるが、ページ単位、あるいはテーブル単位といった大きな単位でロックをかけることもできる※12。このように異なる粒度(細かさ)でのロックがサポートされている場合、データベースシステムは異なる粒度でのロックの衝突も発見する必要がある。この際、インテントロックがあると、例えばページやテーブル全体に対してかけられたロックと、個々のレコードにかけられたロックの衝突も容易に発見できるようになる。インテントロックは、SQL Serverのような異なる粒度でのロックが可能なデータベースシステムでよく利用されるものである。
| *12 例えば一括データ更新を行うような場合には、SQL文を調整してテーブル全体に対してまるごとロックをかけた方が性能的に有利になることも多い。このような場合にテーブル全体へのロックが使われる。通常、このようなテーブル全体のロック取得はロックヒントによる明示的な指定により行うが、ロックしなければならないレコード数があまりにも膨大になると、ページやテーブル全体に対して直接ロックをかけ、ロック処理のオーバヘッドを減らすように自動的に調整される場合がある。この挙動をロックエスカレーションと呼ぶ。ロックエスカレーションが発生する詳細な条件は、『アーキテクチャ徹底解説Microsoft SQL Server 2000』(日経BPソフトプレス)の「14.6.1 ロックのエスカレーション」を参照のこと。 |
本書では解説が複雑になることを避けるため、インテントロックに関するこれ以上の深入りは避ける。以降の解説で重要なのは、インテントロックではなく、実際の行データに対してかけられている共有ロック、更新ロック、排他ロックである。以降の演習において当該トランザクションが保有しているロックの状態を確認する際、このようなインテントロックに戸惑わないようにして作業を進めて頂きたい。
以上を理解しておくと、SEMを利用したロック情報の確認ができるようになる。今度は、分離レベルを変化させることによって、ロックの挙動がどのように変化するのかを確認してみよう。
| INDEX | ||
| .NETエンタープライズWebアプリケーション 開発技術大全 | ||
| SQL Serverのロック管理 | ||
| 1.SQL Serverのロックメカニズムの基礎 | ||
| 2.SQL Serverの内部構造とロック対象となるリソース | ||
| 3.分離レベルによるロック保持期間の変化 | ||
| 4.分離レベルによるインデックスキーに対するロックの種類の変化 | ||
| 「.NETエンタープライズWebアプリケーション開発技術大全」 |
- 第2回 簡潔なコーディングのために (2017/7/26)
ラムダ式で記述できるメンバの増加、throw式、out変数、タプルなど、C# 7には以前よりもコードを簡潔に記述できるような機能が導入されている - 第1回 Visual Studio Codeデバッグの基礎知識 (2017/7/21)
Node.jsプログラムをデバッグしながら、Visual Studio Codeに統合されているデバッグ機能の基本の「キ」をマスターしよう - 第1回 明瞭なコーディングのために (2017/7/19)
C# 7で追加された新機能の中から、「数値リテラル構文の改善」と「ローカル関数」を紹介する。これらは分かりやすいコードを記述するのに使える - Presentation Translator (2017/7/18)
Presentation TranslatorはPowerPoint用のアドイン。プレゼンテーション時の字幕の付加や、多言語での質疑応答、スライドの翻訳を行える
|
|





