
今さら人に聞けない
「JavaとXMLのあたりまえの関係」
JavaとXMLはなぜ仲良し?
米持幸寿
日本アイ・ビー・エム
2001/1/11
| JavaによるXML文書の処理 |
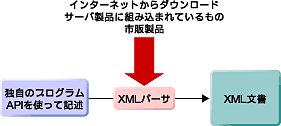
XMLパーサ
タグの分解とスキーマの検査がXML処理の中心である。タグは小なり「<」と大なり「>」で囲まれた文字列である。例えば、文書の中に氏名が含まれている場合、文書の一部分、すなわち氏名の部分に「氏名」と標識をつけたい。このとき、
<氏名>米持 幸寿</氏名>
とタグで囲むことにより、識別をつける。
これらの文字を検索して読み取ればXML文書をタグごとに分解する処理が実装できる。このような処理を「パース」という。しかし、タグづけの形式はXMLの規約によって厳密に規定されており、このような同じ処理をみんなで実装する必要はない。どこかにモジュールとして提供されている方が楽であるし安心して使える。
そこで、XMLを処理するには、そのためのプログラム・モジュールが存在し、それらを利用してプログラム開発を行うのが一般的である。このようなプログラム・モジュールを「XMLプロセッサ」という。しかし、XMLプロセッサの処理のほとんどはタグの読み取りと分解、つまりパースであるため、多くのものが「XMLパーサ」と呼ばれている。
XMLパーサには非常に多くのものが存在している。XMLパーサには、無料ダウンロードのもの、サーバ製品などに組み込まれているもの、商用に市販されているものなど各種ある。
 |
今回はJavaとXMLに関する話題であるので、当然のことながらJavaのパーサを紹介しよう。
日本で最初に実装され、当時存在した中でまともに日本語が扱える唯一のJava版XMLパーサと呼ばれたのが IBM の alphaWorks
(http://alphaworks.ibm.com/jp/
)が提供していた「XML Parser for Java V1.0」である。クラス・ライブラリが「xml4j.jar」であったため、XML4Jとも呼ばれている。現在ではオープンソースを推進する団体apache(http://www.apache.org/)にてソースコードが公開され、Xerces(ザーセスとか、ザーシーズと読む)という名前になって機能強化が行われている。Xercesの最新バージョンは1.2.3であり、2.0がアルファ版として作業中である。今ではXML4JもXercesベースとなり、バージョン3.0が最新版だ。XercesもXML4Jも無料でダウンロードできるツールであり、商用ではないがいわゆるデファクト・スタンダードといってよいだろう。
最近では商用パーサも続々登場しており、パフォーマンスや有償サポートなどにより差別化を図っている。モバイル機器用に自作の超軽量パーサを実装しているメーカーもある。
Java版XMLパーサは、ほとんどの場合DOMとSAXのインターフェイスを持っており、目的に合わせて使い分けることになる。これらのAPIに不足分を補ってXML文書の書き出し機能などをJava標準に取り入れたJAXP(Java
API for XML Parsing / http://java.sun.com/xml/
)や、SAX、DOMと互換性はないが、Javaプログラマーにとって非常に使いやすく軽量を誇るJDOM(
http://jdom.org/ )などが最近注目を集めている。今回の記事では、非常に多く出まわっている「IBM XML Parser
for Java V3.0」を使った実装を例にとって紹介する。
DOM-API
DOM(Document Object Model)は、ドキュメント(文書)をオブジェクト・ツリーというモデルにあてはめて処理する方式である。DOMは、W3Cによって正式に勧告されたオープンな規約である(http://www.w3.org/TR/REC-DOM-Level-1)。
DOM仕様は年々改定され続けており、現在はNamespaceに対応したDOMレベル2(http://www.w3.org/TR/2000/REC-DOM-Level-2-Core-20001113/)が正式な最新版、DOMレベル3がワーキング・ドラフトという状況である。DOMは、読み込んだXML文書をDOMツリーというオブジェクト・ツリーに展開してメモリ上に維持する方式である。当然のことながらメモリを大量に消費する。しかし、ドキュメントの構造全体を一度に使いたい場合、構造に変更を加える場合やランダムにアクセスする必要のある場合には有効な方法だ。
今回は、既知のDOMレベル1を使ってJava言語からXML文書を処理する例をご覧いただこう。
DOMによるXMLの読み取りプログラミングは、次のような流れで行われる。
- パーサ・インスタンスを生成する
- ドキュメントを指定する
- パース処理を呼び出す
- ドキュメントルート(DOMツリー)を取得する
- DOMツリーを処理する
パーサ・インスタンスの生成は利用するパーサによって違う。今回は、Xercesを使うが、次のようなコードでパーサ・インスタンスを生成し、ドキュメントオブジェクトを取り出すことができる。
static public Document getDocument(String
xmlFile) { |
このコードをメソッドとして定義しているのには理由がある。このコードはパーサに依存したコードである。キャスト部分を見ていただければ分かるようにこのコードを実行するには「com.ibm.xml.parsers」パッケージが必要である。この事情はどのパーサでもほぼあてはまると考えてよいだろう。JAXPやjavax.xmlによって解消されるという説もあるが、既存のものがデファクトになってしまっている現在すぐには解消されない。そういった場合、DOMを取り出すためのユーティリティクラスを1つ作っておくことでポータブルなコードが作れるので、このような工夫は有効である。
「XMLパーサは選択したものを1つ使えばよいのではないのか」と思われる方もいるだろうが、現実にはXMLパーサを切り替える必要に迫られることがある。あるXMLパーサで作ったコードをアプリケーションサーバなどで稼働させるとき、サーバが必要とするXMLパーサが違うものであることがある。このようなとき、ユーティリティクラス1つだけを修正すればよい。
さて、このメソッドにファイル名を渡せば、DOMツリーが戻される。今は読み取りをする処理をするのだが、ここでは単純にすべてのノードを読み取るコードをご紹介しよう。
まず、DOMツリーからルートノードを取り出し、別の再帰呼び出しを行うメソッドに渡す。
if (doc != null) { |
読み取りを行うメソッドでは、
public static void traverseDOMBranch(Node
node) { |
このように、再帰を行いながらすべてのノードを検索する。ここではNodeListを使って検索を行っているが、DOM-APIにはたくさんの便利なメソッドがあり、DOMツリー内を行ったり来たりすることができるので、調べて使ってみてほしい。また、再帰メソッドにしたのは単にサンプルとして分かりやすいからであり、都合に合わせて自由にしてよい。
このコードを見て、気付かれた方もおられると思うが、今処理をしようとしているデータを持っているノードと、それに付いている名前のノードは同じものではなく、親子関係にある。これは、DOMの考え方ではXMLタグが構成する単位はエレメントノード、内容(テキスト)が入る部分はテキストノードという関係を持っていることからきている。分かりにくい部分なので、最初に覚えてしまおう。
|
||||||

SAX-API
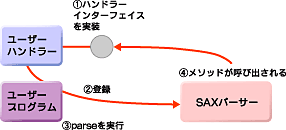
DOMがW3Cで規定されているAPI仕様であるのに対して、SAX(Simple API for XML)はプログラマーによって作られたAPI仕様である。SAXをDOMと比較したとき、最も違う部分は、ハンドラーとコールバック・メソッドという考え方である。SAXはイベント駆動型のAPIである。ウィンドウ・プログラミングをしたことのある人ならすぐ分かると思うが、ハンドラー・インターフェイスを実装したクラスを準備し、登録する。処理が始まると実装したメソッドが呼び出される。これがコールバック・メソッドである。
SAX-APIは、DOMと比較して軽いAPIである。XML文書を一度にメモリに読み込んで維持するようなことはないため、メモリの使用量も少ないし、エレメントやノードごとにいちいちオブジェクトを作成したりしないからである。
SAX-APIでは、まずDocumentHandlerインターフェイスを実装するクラスを準備することから始まる。もちろん、実行プログラムで自分自身に実装しても構わない。
DocumentHandlerで定義されているメソッドは次のものである。
startDocument()endDocument()startElement(java.lang.String name, AttributeList atts)endElement(java.lang.String name)characters(char[] ch, int start, int length)ignorableWhitespace(char[] ch, int start, int length)processingInstruction(java.lang.String target, java.lang.String data)setDocumentLocator(Locator locator)
各メソッドの意味は名前を見ていただければそれなりに分かるが、パーサに付属してくるAPIのリファレンスに載っている。
実は、最新のパーサではDocumentHandlerではなくContentHandlerを使うように勧めている。ここではとりあえず現在よく使われているDocumentHandlerを紹介する。
クラスを継承するので構わないのであれば、HandlerBaseクラスを継承することでもハンドラーとすることができる。この場合、すべてのメソッドを実装する必要はない。必要に応じて実装すればよい。
実行手順は次のようなものである。
- SAXパーサのインスタンスを作る
- ハンドラークラスを登録する
- parseメソッドを呼び出す
 |
具体的には次のようなコードを記述する。
| public static String parserName = "com.ibm.xml.parsers.SAXParser"; Parser parser = ParserFactory.makeParser(parserName); parser.setDocumentHandler(this); parser.parse(url); |
「えぇ? これだけ?」と思う方もおられるだろう。けっこう簡単である。もちろん、リテラル部分はパーサに依存したコードなのでDOMの場合と同様、気を付けよう。
実際に、メソッドを実装してSystem.outに受け取ったデータを書き出すようなプログラムを作って動作を確認してみてほしい。
21世紀の事始めに、JavaとXMLの関連性についてまとめてみた。来月からは、XMLフォーラムにおいて、SOAP、UDDI、WSDL、Web
Servicesといった「インターネットを巨大システムに変える」可能性を持ったテクノロジの解説を連載で解説していく予定である。Javaにも非常に関連性の強い話題であるので、ご期待いただきたい。
|
|
| Index | |
| JavaとXMLはなぜ仲良し? | |
| JavaとXML、それぞれが目指した世界 Javaが目指した世界 XMLが目指した世界 HTMLはなぜ普及したか? HTMLのジレンマ XMLによる情報の再利用 XMLの特徴 XMLの操作 |
|
| JavaによるXML文書の処理 XMLパーサ DOM-API SAX-API |
|
- 実運用の障害対応時間比較に見る、ログ管理基盤の効果 (2017/5/9)
ログ基盤の構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。今回は、実案件を事例とし、ログ管理基盤の有用性を、障害対応時間比較も交えて紹介 - Chatwork、LINE、Netflixが進めるリアクティブシステムとは何か (2017/4/27)
「リアクティブ」に関連する幾つかの用語について解説し、リアクティブシステムを実現するためのライブラリを紹介します - Fluentd+Elasticsearch+Kibanaで作るログ基盤の概要と構築方法 (2017/4/6)
ログ基盤を実現するFluentd+Elasticsearch+Kibanaについて、構築方法や利用方法、実際の案件で使ったときの事例などを紹介する連載。初回は、ログ基盤の構築、利用方法について - プログラミングとビルド、Androidアプリ開発、Javaの基礎知識 (2017/4/3)
初心者が、Java言語を使ったAndroidのスマホアプリ開発を通じてプログラミングとは何かを学ぶ連載。初回は、プログラミングとビルド、Androidアプリ開発、Javaに関する基礎知識を解説する。
|
|





