
9月版 帰ってきたCon Kolivas、大論争を呼ぶの巻
小崎資広
2009/10/14
SDスケジューラの作者として、また派手な大ゲンカの末Linuxコミュニティから去った人物として名高いCon Kolivasが、新しいスケジューラをひっさげて帰ってきました。8月の終わりに彼が自身のWebサイトにてパッチとFAQを掲載すると、たちまちさまざまな技術系ニュースサイトで報道され、大きな話題となりました。
では、このBFSスケジューラとはどのようなスケジューラなのでしょうか? このスケジューラがLinuxスケジューラに与えた影響について見ていきましょう。
| 関連記事: | |
| Linux Kernel Watch 2007年9月版 ユーザー空間でのデバイスドライバ作成に道開ける | |
| デスクトップLinuxを巡る7つの話題(@ITNews) | |
 What's BFS?
What's BFS?
BFSとは「the Brain Fuck Scheduler」の略(注1)で、大規模ハードウェアでのスケーラビリティよりもむしろローエンドのハードウェアでの動作改善を視野に入れています。ローエンドの機器でもきびきび動作し、デスクトップで高負荷を与えたときに生じるマウスカーソルスキップなどのインタラクティブタスクへの影響を最小限にすることを優先する思想で設計されています。
また、大きな特徴の1つとして、SCHED_ISOという新しいスケジューラクラスを追加します。ISOは「Isochronous」(アイソクロナス)の略で、CPU時間を全体の70%(注2)までしか使えない代わりに、リアルタイムクラスのように通常のプロセスより高い優先度で実行が行えるという、root権限が不要な特殊なリアルタイムクラスです。
| 注1:……ということになっていますが、どう見てもCFSのパロディです。商業誌に載せるのをためらうようなけんのんな名前を付けるのはやめていただきたいものです。まったく。 注2:チューニング・パラメータで変更可能。 |
| ■コラム 消えない、1行 | |
|
面白いことに、SCHED_ISOはSDスケジューラで一度実装され、その後CFSで廃止された経緯があるため、ディストリビューションによく付属しているschedtoolではすでに対応が完了しています。またCFSスケジューラにも、
なんていう、お茶目な行が残っていたりします。 |
BFSは、ioperm(2)およびiopl(2)システムコールが事実上Xからしか呼ばれていないことに着目して、ioperm(2)やiopl(2)を使用したプロセスを強制的にSCHED_ISOに変更しています。これにより、ユーザー空間に変更を加えることなしにXのインタラクティビティを上げており、マウスカーソルラグの少なさで賞賛を浴びました。
また、彼のFAQにはとても興味深い記述がありました。BFSではmakeのparallel make機能がよりうまく扱えるというのです。従来、parallel makeを行うときは、クアッドコアのマシンでは6〜8並列ぐらいでコンパイルを実行することが普通でした。I/O待ちがあるために、4並列ではCPUが無駄になると信じられてきたのです。しかし、ConはBFSで4並列(=CPU個数)で最高性能が出ることを示し、ネックがI/Oではなくスケジューラであることを示しました。
しかしBFSは、
- 作者にはLKMLで活動するつもりがない
- cgroup対応がない
- ランキューサーチがO(n)
- SCHED_ISOのタスク数がCPU数を超えると、面白いように性能が劣化する
- 大規模マシンにはスケールしない
- いくつかのドライバ(NFS、i915 Graphics、ATI Drivers、ReiserFS 3.6など)との組み合わせでハングする
- なぜ既存コードを全部消す必要があるのか、全然理解できない
- iopermにフックを入れるのは汚過ぎるだろう、常識的に考えて
といった理由から、筆者的にはまったくマージの可能性がなく、すぐ話題から消えていくのかな……と思っていたのですが、予想は大ハズレ。その後約1カ月間、LKMLはBFSvsCFSのベンチマーク合戦で大いに盛り上がりました。
メンテナからの回答は「CFS有利」
9月7日に現在のスケジューラメンテナ、Ingo Molnarが、BFSとCFSに対する自身のベンチマーク結果を投稿しました。ちょっと長いですが、グラフと彼の性能分析を引用します。
なお測定は、16CPU(4core×2thread×2socket)のマシンで行ったとのこと。このマシンが個人で購入可能な上限なので、Conが主張する「light NUMA」でのスケーラビリティ測定が可能だと考えたからだとか。
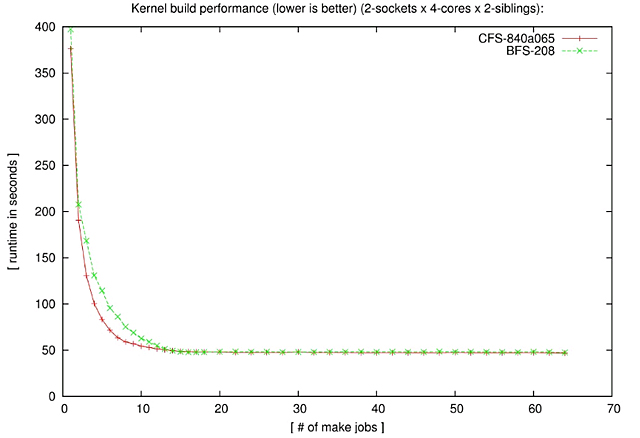
・Kernel build performance
kbuild(linux kernel build)テストでは、並列数が16未満ではBFSが際立って遅い。8並列では27.6%も遅い。16並列ではBFSの方が若干速いが、その差は1.5%である。最高性能でいうと、CFSは64並列時に46.65秒であり、BFSの同じく64並列時の47.38秒より1.5%よい。 ・Pipe performance
Pipe performanceは非常に単純なテストで、2つのタスクがお互いにパイプでメッセージを100万個ずつ送り合うようなプログラムを並列実行する。 <<ソースコード>>
<<実行方法>>
このテストは2つの事柄を測定している。1つはスケジューラの基本性能、もう1つはスケジューラの公平さである(もし、ある特定のタスクだけがアンフェアに遅延させられたら、全体の終了時間も遅くなるだろう)。 この点においてBFSは非常に悪い結果を示す。CFSが3.8秒で終わらせることができる8ペアの測定で45.42秒もかかった。また、それ以上並列数を上げるとスケジューラ・ラグにより以下のI/Oタイムアウトが発生してしまい、測定を完了させることができなかった。
また、このテストを実施中に以下のコマンドによりインタラクティビティを計測したところ、/bin/trueが終了するまでに2分以上かかった。
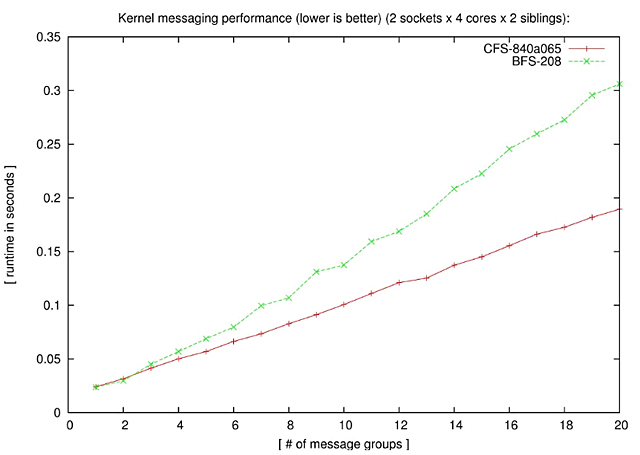
・Messaging performance
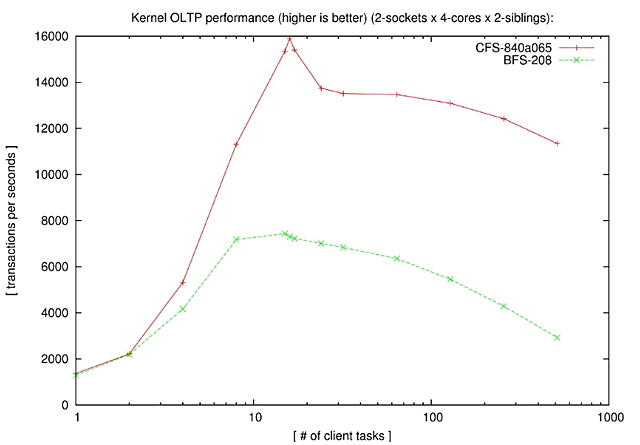
Hackbenchは両方のスケジューラでよく動作する。しかし、CFSの方が常に性能がよく、20group(800プロセス)では61.5%高速である。 ・OLTP performance
sysbench OLTP性能でもCFSスケジューラは常にBFSを上回る。
|

という具合に、これを見ると全項目でCFSが勝っており、BFSにいいところがありません。
ちゃんと確認できていないのですが、このテストで「CFS有利」という結果が得られたのには、以下の2つの理由がありそうです。
1. 測定をmainlineではなくsched-develで行った
sched-develには、この測定の数日前に「sched: Turn on SD_BALANCE_NEWIDLE」というcommitがされており、タスクのsleep時にCPU間の負荷バランス処理を実行するパラメータがONになっています。これは、Ingoが半年ほど前に、データベースのベンチマークを上げるためにOFFにしていたパラメータでした。タスクのCPUマイグレーションが頻繁になると、レイテンシは短くなりますが、スループットには悪影響が出るケースが多いので、関係がありそうです。
2.x86_64の中ではハイエンドに位置付けられる16CPUのマシンで測定を行った
これにより、結果的にデスクトップマシンでの測定ではなく、スケーラビリティテストになってしまっている、ということです。もっとも、これはズルではなく、Ingoによれば「もしスケジューラに変更を加えた場合、ディストリに変更が入るのは1〜2年後なので、そのころには標準デスクトップの構成がまた変わってしまう。だから、ちょっとハイエンドの機器でテストしないと、変更する意味がない」という意図だそうです。
| 8月版へ |
1/3 |
|
|
||||||
|
||||||
| 連載 Linux Kernel Watch |
| Linux Squareフォーラム Linuxカーネル関連記事 |
| 連載:Linux Kernel Watch(連載中) Linuxカーネル開発の現場ではさまざまな提案や議論が交わされています。その中からいくつかのトピックをピックアップしてお伝えします |
|
| 連載:Linuxファイルシステム技術解説 ファイルシステムにはそれぞれ特性がある。本連載では、基礎技術から各ファイルシステムの特徴、パフォーマンスを検証する |
|
| 特集:全貌を現したLinuxカーネル2.6[第1章] エンタープライズ向けに刷新されたカーネル・コア ついに全貌が明らかになったカーネル2.6。6月に正式リリースされる予定の次期安定版カーネルの改良点や新機能を詳しく解説する |
|
| 特集:/procによるLinuxチューニング[前編] /procで理解するOSの状態 Linuxの状態確認や挙動の変更で重要なのが/procファイルシステムである。/procの概念や/procを利用したOSの状態確認方法を解説する |
|
| 特集:仮想OS「User
Mode Linux」活用法 Linux上で仮想的なLinuxを動かすUMLの仕組みからインストール/管理方法やIPv6などに対応させるカーネル構築までを徹底解説 |
|
| Linuxのカーネルメンテナは柔軟なシステム カーネルメンテナが語るコミュニティとIA-64 Linux IA-64 LinuxのカーネルメンテナであるBjorn Helgaas氏。同氏にLinuxカーネルの開発体制などについて伺った |
|
|
- 【 pidof 】コマンド――コマンド名からプロセスIDを探す (2017/7/27)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、コマンド名からプロセスIDを探す「pidof」コマンドです。 - Linuxの「ジョブコントロール」をマスターしよう (2017/7/21)
今回は、コマンドライン環境でのジョブコントロールを試してみましょう。X環境を持たないサーバ管理やリモート接続時に役立つ操作です - 【 pidstat 】コマンド――プロセスのリソース使用量を表示する (2017/7/21)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、プロセスごとのCPUの使用率やI/Oデバイスの使用状況を表示する「pidstat」コマンドです。 - 【 iostat 】コマンド――I/Oデバイスの使用状況を表示する (2017/7/20)
本連載は、Linuxのコマンドについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、I/Oデバイスの使用状況を表示する「iostat」コマンドです。
|
|





