
バックアップを効率化する重複排除テクノロジ(3)
高度な重複排除の実装例と最先端の技術
株式会社シマンテック
プロダクトマーケティング部 プロダクトマーケティングマネージャ
浅野 百絵果
2010/9/14
| 前回、前々回と重複排除の技術概要やバックアップシステムへの適用例について解説した。急激な増加の一途をたどるデータ量がインフラへの投資スピードを上回り、企業が求めるデータ保護に対するサービスレベル達成の実現が困難になりつつある中で、キラーソリューションともいえる重複排除は本格的な普及期を迎えつつある。最終回である今回は、重複排除技術によるメリットのおさらいと合わせて、高度な重複排除の実装例と最先端の技術、そして、その将来像について触れてみたい。 |
 重複排除がもたらすメリット
重複排除がもたらすメリット
重複排除は、“同一データをバックアップ処理から排除する”というシンプル、かつ合理的な考えのもと実装されている。このソリューションは、新しい技術としても注目を浴びたが、やはりそのコスト削減効果が、普及を後押しした大きな要因といえる。また、コスト削減だけでなく、同時に付帯的、複合的なメリットを享受できることが今日のトレンドへ押し上げた。以下の4項目は、重複排除による代表的なメリットである。
- (1)パフォーマンスの向上
- (2)ネットワーク帯域の削減
- (3)運用効率の向上
- (4)アーカイブ技術を取り入れる
以降、それぞれのメリットを補完する最先端の技術をご紹介しよう。
(1)パフォーマンスの向上
◆バックアップの速度向上
週末の48時間を使ってもフルバックアップが終わらない、というシステムも多くなってきている。従来のバックアップでは、バックアップデータをバックアップセットと呼ばれる大きな単一ファイルとしてバックアップ先で管理してきた。複数に渡る世代管理、フルバックアップに対する差分(増分)のバックアップを蓄積するため、バックアップ先のストレージの容量も増えてきたのが実情だ。一方、重複排除におけるバックアップ先のストレージの中身を見てみると、細かく分割されたユニークなデータブロックの複合体といえる。バックアップソフトウェアやストレージは、これらのデータブロックの関連性を管理している。このデータブロックが同じものは重複しているものとしてバックアップ対象から外され、バックアップのパフォーマンスが向上する。
さらに、バックアップクライアントでの重複排除であれば、毎回フルバックアップであっても、変更されたユニークなブロックだけがバックアップデータとしてバックアップ先媒体に転送される。初回のフルバックアップでさえ、同一のブロックが複数存在している場合は重複となり、1度しか転送されない。2回目以降は、変更のないブロックはチェックだけしか行われず、変更されたブロックだけがバックアップされるので、バックアップ時間が大幅に短縮される。
◆リストアの速度向上
従来のバックアップ手法では、フルバックアップと差分(あるいは増分)バックアップの組み合わせでリストアに備えてきたのが一般的だ。毎回、フルバックアップを取得すれば、リストアを容易かつ短時間で行えるが、そのために毎回フルバックアップは行えない、という場合も多いからだ。
この従来の手法では、リストアが必要になった場合、まずフルバックアップをリストアし、その後、差分あるいは増分といったサブセットのリストアを複数回行い、全体のリストアを行う。これではリストアに要する時間も手間もかかってしまうのが課題とされてきた。
重複排除によるバックアップであれば、そもそも毎回ユニークなデータブロックだけを処理するので、フルバックアップや差分バックアップの定義が必要なくなる。リストアの観点では、毎回のバックアップがフルバックアップとなり、一度のリストアで完了する。重複排除は、リストアも高速に、そしてシンプル化できる。バックアップはリストアの準備作業にすぎないのだ。バックアップシステムに要求される一番重要なことは、リストア(リカバリ)にかかっているといっても過言ではい。
◆さらに進んだ技術
メディアサーバまたはストレージでの重複排除では、バックアップクライアントのデータが転送されてから重複排除の処理が実行されるので、劇的な時間短縮にはならない。しかし、バックアップ対象クライアント側とストレージ側での重複排除機能を組み合わせて、時間の短縮を図る「仮想合成バックアップ」と呼ばれる手法も登場している。
シマンテックを例にとるとOpenStorage Technology(OST)というフレームワーク(=API)の上にシマンテックの重複排除ソフトウェア、あるいはストレージベンダが連携モジュールを提供し、統合された管理体系を提供している。ストレージ側での重複排除では、どのデータが重複しているのか判断するための機構がストレージに搭載されている。これを利用して、あらゆるバックアップデータからフルバックアップの再構築を可能にするものである。仮想合成バックアップを使用すると、差分バックアップからフルバックアップが内部のポインタの変更だけで高速に生成できる。初回の1回を除き、フルバックアップの実行が実質的に必要なくなる。またリストア時にはストレージ側の機能を使ってフルバックアップが再構築されているため、従来のようにフルバックアップに差分バックアップを組み合わせる必要がなくなる。バックアップとリストアの両方において、処理の負荷や時間の短縮ができるのだ。
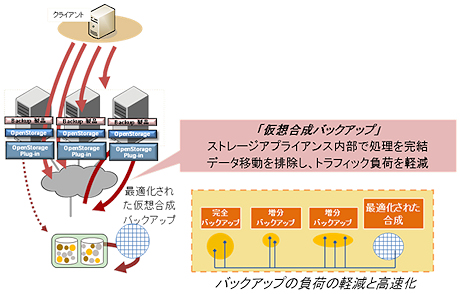 |
| 図1 クライアント側とストレージ側の重複排除機能を組み合わせる仮想合成バックアップを使えば、大幅な時間短縮が期待できる |
1/2 |
| Index | |
| 高度な重複排除の実装例と最先端の技術 | |
| Page1 重複排除がもたらすメリット (1)パフォーマンスの向上 |
|
| Page2 (2)ネットワーク帯域の削減 (3)運用効率の向上 (4)アーカイブ技術を取り入れる 重複排除の今後 |
|
- Windows 10の導入、それはWindows as a Serviceの始まり (2017/7/27)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者向けに、移行計画、展開、管理、企業向けの注目の機能について解説していきます。今回は、「サービスとしてのWindows(Windows as a Service:WaaS)」の理解を深めましょう - Windows 10への移行計画を早急に進めるべき理由 (2017/7/21)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者に向け、移行計画、展開、管理、企業向けの注目の機能を解説していきます。第1回目は、「Windows 10に移行すべき理由」を説明します - Azure仮想マシンの最新v3シリーズは、Broadwell世代でHyper-Vのネストにも対応 (2017/7/20)
AzureのIaaSで、Azure仮想マシンの第三世代となるDv3およびEv3シリーズが利用可能になりました。また、新たにWindows Server 2016仮想マシンでは「入れ子構造の仮想化」がサポートされ、Hyper-V仮想マシンやHyper-Vコンテナの実行が可能になります - 【 New-ADUser 】コマンドレット――Active Directoryのユーザーアカウントを作成する (2017/7/19)
本連載は、Windows PowerShellコマンドレットについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、「New-ADUser」コマンドレットです
|
|
注目のテーマ





