
バックアップを効率化する重複排除テクノロジ(3)
高度な重複排除の実装例と最先端の技術
株式会社シマンテック
プロダクトマーケティング部 プロダクトマーケティングマネージャ
浅野 百絵果
2010/9/14
 (2)ネットワーク帯域の削減
(2)ネットワーク帯域の削減
重複排除は、バックアップ先のディスクやバックアップサーバで実現する方法もある、と前回解説したが、一般的に最も効果が発揮しやすいのはデータの発生源、つまりアプリケーションに近いところで重複排除を行い転送データ量の削減、そしてネットワーク帯域の削減を行うバックアップクライアントでの重複排除だ。
LAN経由でのバックアップでも効果が発揮されるし、各拠点に分散されたデータのWAN超えのバックアップへ適用して、管理コストを削減するバックアップ統合への第一歩を踏み出すことも可能だ。
バックアップサーバ側で管理されるバックアップデータを見ても、重複排除されたバックアップデータは、従来に比べ非常にコンパクトになるのが一般的だ。例えば、同じOSの10台のサーバをバックアップしているとする。通常世代管理を含め複数のバックアップセットを管理しているが、OSの同じ部分については、最初の一台目以外バックアップサーバに転送されないのでネットワーク転送量も1/10の容量で済むことになる。
DR対策の必要性から、テープに書き込み物理的な別サイトへの保管をネットワークで転送して自動化したくても回線コストにあきらめたシステムもまだ多いのが実情だ。こういうシステムへも重複排除の技術を導入することで、コスト効果の高いDRシステムの構築も可能となる。また、ネットワークに流れるデータは、ファイル単位ではなく、重複排除処理によって小さなブロックに分割されたものが転送されるためセキュリティの観点からも安全性が高いといえる。
重複排除は、DR対策の敷居も下げる事が可能なのだ。
(3)運用効率の向上
重複排除は、従来のバックアップ運用と比較するとパックアップパフォーマンスの改善やバックアップディスクの削減、ネットワークの帯域削減とさまざまなメリットがあり、今後ますます導入されるシステムが増えてくるだろう。
さて、重複排除は、既存のバックアップにおける課題をすべて解決してくれる魔法の技術なのだろうか?答えは、Noである。バックアップ運用における、企業全体での最適化を忘れてはならない。例えば、一般的な企業において、営業部門、経理部門、開発部門それぞれ別のシステムを運用しているとしよう。同じ会社内なので、部署間のやりとりに使われるデータもあり、別々のファイルサーバに保存しているのでは重複したデータが多数存在することになる。これらを別々のバックアップサーバで運用していると、当然バックアップ先のストレージにも複数の重複したデータをバックアップしていることになり、ストレージの非効率が生じている。小規模な部門プロジェクトとしてではなく、部門間での重複も含めて排除することで効果は最大化する。つまりスケールメリットが出やすい。重複排除を部門システムでまずは始めてみる、という選択肢は当然あるが、より大規模に展開することによってその効果は高くなる。
バックアップインフラの統合はストレージやバックアップサーバ、ネットワークも含めた全体的なコスト効率や運用効率の向上にもつながるが、正常稼働中のインフラに対して大規模な改変を加えることは実際には難しい。重複排除の採用は、部門間のバックアップインフラの統合化プロジェクトに着手する良いきっかけになるのではないだろうか。
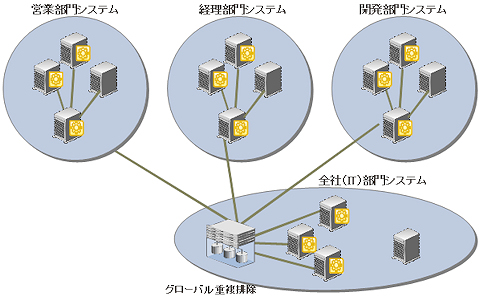 |
| 図1 バックアップを統合してディスク効率を向上 |
(4)アーカイビング技術を取り入れる
重複排除が、バックアップディスクや設置スペースの削減をもたらすことに異論はないだろう。重複排除は多くのメリットとその可能性によって支持を広げている。とはいえ、バックアップはシステムの特性から、ITシステムに直接影響して生産性を向上するものではない。例えば、今回のテーマである重複排除は、同じデータが分散している複数のサーバ、世代のデータに対して、バックアッププロセスの中で合理化するのがゴールである。
では、稼働中のITシステム自体の効率化を考えてみよう。同じデータが複数に分散していることについて、改善の余地はないのだろうか?
では、どうすれば良いのか。エンドユーザーへの透過的なアクセスを提供しながら、バックエンドのシステムを効率化すればよいのではないだろうか。アーカイブ技術を取り入れると、アクセス頻度の少ない、一定期間経過した古いデータを階層ストレージに自動的に移行することができる。アーカイブは、アプリケーションが使用しているデータ領域の削減、これに伴うパフォーマンスの向上というプラスの生産性ももたらす。また使用中のデータが最適化され、バックアップ対象のデータ量が少なくなるため、バックアップに要する時間も短くなる。
アーカイビングは効率的な長期保全を目的とするもので、リカバリが目的のバックアップとは厳密には異なるが、全体的なデータの効率化の目的では一連の仕組みとみなすことができる。
短期的なリストアに備えたバックアップでは、重複排除の適用によるコストの削減やパフォーマンスの向上、そして長期保存のためのアーカイビングの併用など、柔軟にテクノロジを使い分けることで、さらなる効率化が実現される。
|
バックアップ
オリジナルのデータロストやアクセス不能になった場合のリカバリに備え、データを非揮発性のストレージメディアに収集すること
|
アーカイビング
データの保存期間の管理、長期間の保全を目的として、データ、および関連情報をストレージシステムへ収集すること
*SNIAによる定義
|
重複排除の今後
データの爆発的な増加は以前から想定されていたことだが、ベンダによる重複排除技術の開発が並行して行われていたことに加え、経済状況の悪化に伴うコスト削減の必要性が重なったことが重複排除の普及を後押ししたともいえる。また、重複しているデータが多い特性を持つサーバ仮想化の普及も重複排除を導入する要因の1つとなったといえるだろう。
従来であれば新技術の導入よりも、とにかく実績のある手法でインフラの増強が行われたかもしれないが、国内でもコスト削減に向けた投資の変化がみられる中、重複排除の導入が加速し、アーカイブとの併用やインフラの統合など最適化へ目が向けられている。
また、重複排除という技術は、回線コストとのバランスによりなかなか実現できていなかったDRへの用途と進化していくことが予想される。とかくポイントソリューションや新技術が注目されることも少なくないが、重複排除技術はシステム全体の最適化へ向けて進歩しており、データ保護における標準的な技術として広く採用されるようになる日もそう遠くはないだろう。
2/2 |
| Index | |
| 高度な重複排除の実装例と最先端の技術 | |
| Page1 重複排除がもたらすメリット (1)パフォーマンスの向上 |
|
| Page2 (2)ネットワーク帯域の削減 (3)運用効率の向上 (4)アーカイブ技術を取り入れる 重複排除の今後 |
|
- Windows 10の導入、それはWindows as a Serviceの始まり (2017/7/27)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者向けに、移行計画、展開、管理、企業向けの注目の機能について解説していきます。今回は、「サービスとしてのWindows(Windows as a Service:WaaS)」の理解を深めましょう - Windows 10への移行計画を早急に進めるべき理由 (2017/7/21)
本連載では、これからWindows 10への移行を本格的に進めようとしている企業/IT管理者に向け、移行計画、展開、管理、企業向けの注目の機能を解説していきます。第1回目は、「Windows 10に移行すべき理由」を説明します - Azure仮想マシンの最新v3シリーズは、Broadwell世代でHyper-Vのネストにも対応 (2017/7/20)
AzureのIaaSで、Azure仮想マシンの第三世代となるDv3およびEv3シリーズが利用可能になりました。また、新たにWindows Server 2016仮想マシンでは「入れ子構造の仮想化」がサポートされ、Hyper-V仮想マシンやHyper-Vコンテナの実行が可能になります - 【 New-ADUser 】コマンドレット――Active Directoryのユーザーアカウントを作成する (2017/7/19)
本連載は、Windows PowerShellコマンドレットについて、基本書式からオプション、具体的な実行例までを紹介していきます。今回は、「New-ADUser」コマンドレットです
|
|
注目のテーマ





