Œ»ژہ‚جXML•¶ڈ‘‚ًŒ©‚éپFXML‚ًٹw‚ع‚¤پi3پj
چ،‰ٌ‚حژہچغ‚ة‚³‚ـ‚´‚ـ‚بXML•¶ڈ‘‚ًŒ©‚ؤ‚¢‚½‚¾‚±‚¤پBƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ئXML‚إ‚ح‚ا‚ج‚و‚¤‚ةˆل‚¤‚ج‚©پACSVŒ`ژ®‚جƒfپ[ƒ^‚ًXML‚إ•\‚·‚ئ‚ا‚ج‚و‚¤‚ة•\Œ»‚إ‚«‚é‚ج‚©پB‹ï‘ج“I‚ب—ل‚ًŒ©‚ؤ‚¢‚½‚¾‚‚ئپAXML‚ة‘خ‚·‚éƒCƒپپ[ƒW‚ھ‚ي‚¢‚ؤ‚‚é‚ح‚¸‚¾پB
ژہچغ‚جXML•¶ڈ‘‚ًŒ©•·‚«‚µ‚و‚¤
پ@XML‚حپA–{ژ؟‚ھƒپƒ^Œ¾Œê‚إ‚ ‚邽‚ك‚ةپu‚ ‚ê‚à‚إ‚«‚ـ‚·پA‚±‚ê‚à‚إ‚«‚ـ‚·پv‚ئ‚¢‚¤کb‚ة—¬‚ê‚â‚·‚¢پB‚»‚ج‚½‚كپAڈ‰گSژز‚ھXML‚ةگG‚ꂽ‚ئ‚«پA‰_‚ً‚آ‚©‚ق‚و‚¤‚بکb‚ب‚ء‚ؤ‚µ‚ـ‚¢پA‹ï‘ج“I‚بƒCƒپپ[ƒW‚ھ•`‚¯‚ب‚¢‚±‚ئ‚à‘½‚¢‚¾‚낤پB
پ@‚»‚±‚إپAچ،‰ٌ‚حپA‚¢‚‚آ‚©‚جژہچغ‚ة‘¶چف‚·‚éXML•¶ڈ‘‚ًŒ©‚邱‚ئ‚إپA‹ï‘ج“I‚بƒCƒپپ[ƒW‚ً‚آ‚©‚قژèڈ•‚¯‚ئ‚µ‚ؤ‚ف‚½‚¢پB
پ،ƒnƒچپ[ƒڈپ[ƒ‹ƒhپI
پ@ƒvƒچƒOƒ‰ƒ€Œ¾Œê‚جگ¢ٹE‚إ‚حپAچإڈ‰‚ةپgHello World!پh‚ئ‚¢‚¤•¶ژڑ—ٌ‚ًڈo—ح‚·‚é•û–@‚ً‰ًگà‚·‚邱‚ئ‚ھ‘½‚¢پB
پ@‚±‚ê‚ة‚ب‚ç‚ء‚ؤپAXML‚إپgHello World!پh‚ئ‚¢‚¤•¶ژڑ—ٌ‚ً‹Lڈq‚·‚é•û–@‚ً‚±‚جکAچع‚ج‘و1‰ٌ–ع‚إگà–¾‚µ‚½پB‚»‚جƒRپ[ƒh‚ج‚ف‚ًˆب‰؛‚ةچؤŒf‚·‚éپi‚±‚êˆبŒمپAƒٹƒXƒg‚جچs“ھ‚جگ”ژڑ‚ئƒRƒچƒ“‹Lچ†پi:پj‚حگà–¾‚ج•ض‹Xڈم•t‚¯‚ؤ‚¢‚éچs”شچ†‚إپAƒRپ[ƒh‚جˆê•”‚إ‚ح‚ب‚¢پjپB
1:پ@<?xml version='1.0' encoding='UTF-8'?> 2:پ@<doc><p>Hello! World!</p></doc>
پ@‚±‚جXML•¶ڈ‘‚ح”ٌڈي‚ةƒVƒ“ƒvƒ‹‚إپAچإڈ¬Œہ“x‚جXML•¶ڈ‘‚ھ‚ا‚±‚ـ‚إڈ¬‚³‚‚ب‚ê‚é‚©‚ة‚آ‚¢‚ؤپA‹ï‘ج“I‚بƒCƒپپ[ƒW‚ً—^‚¦‚ؤ‚‚ê‚éپBچ\‘¢‚ئŒ¾‚¦‚é‚ظ‚ا‚جچ\‘¢‚à‚ب‚پAˆê–ع—ؤ‘R‚إ‚ ‚éپB‚½‚¾•¶ڈ‘‘S‘ج‚ً•ï‚فچ‚قƒ‹پ[ƒg—v‘f‚ئ‚µ‚ؤ‚ج<doc>—v‘f‚ئپA’i—ژ‚ًژ¦‚·<p>—v‘f‚ھ‚ ‚邾‚¯‚إ‚ ‚éپB<doc>—v‘f‚جژq‚ئ‚µ‚ؤ<p>—v‘f‚ھ‚ ‚èپA‚»‚جژq‚ئ‚µ‚ؤHello! World!‚ئ‚¢‚¤•¶ژڑ—ٌ‚ھ‚ ‚éپA‚ئ‚¢‚¤ƒVƒ“ƒvƒ‹‚بٹK‘wچ\‘¢‚ھ‚ ‚邾‚¯‚إ‚ ‚éپB‚µ‚©‚µپAژہچغ‚ةگ¢‚ج’†‚إژg—p‚³‚ê‚éXML•¶ڈ‘‚حپA‚±‚ê‚ظ‚ا’Z‚‚à‚ب‚¢‚µپAƒVƒ“ƒvƒ‹‚إ‚à‚ب‚¢پB
پ،چإڈ¬‚جXML•¶ڈ‘
پ@‚؟‚ب‚ف‚ةپA—]’k‚إ‚ح‚ ‚é‚ھپA‚¬‚肬‚è‚ـ‚إڈ¬‚³‚‚µ‚½گ¢ٹEچإڈ¬‚جXML•¶ڈ‘‚حپA‚¨‚»‚ç‚پAˆب‰؛‚ج‚و‚¤‚بƒRپ[ƒh‚¾‚낤پB‚ب‚¨پA—v‘f–¼‚جa‚ح—v‘f–¼‚ةژg‚¦‚镶ژڑ‚ب‚ç‚ا‚ٌ‚ب•¶ژڑ‚إ‚àچ\‚ي‚ب‚¢پB
1:پ@<a/>
پ@‚آ‚ـ‚èپAXML‚ة‚¨‚¢‚ؤڈب—ھ‚·‚邱‚ئ‚ھگâ‘خ‚ة‹–‚³‚ê‚ب‚¢‚à‚ج‚حپAƒ‹پ[ƒg—v‘f‚¾‚¯‚إ‚ ‚èپAƒ‹پ[ƒg—v‘f‚ج“à—e‚ھ‹َ‚إ‚ ‚é‚ب‚ç‚خپA<a></a>‚ئ<a/>‚ح“™‰؟‚إ‚ ‚邽‚كپA‚½‚¾<a/>‚ئڈ‘‚‚¾‚¯‚إپAXML•¶ڈ‘‚ئ‚µ‚ؤگ¬—§‚·‚éپB
ƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ًXML‚إ‹Lڈq‚·‚é
پ@•Mژز‚ھچىگ¬‚µ‚½txt2xml‚ئ‚¢‚¤ƒcپ[ƒ‹‚ھ‚ ‚éپB‚±‚ê‚حپAƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ًXML•¶ڈ‘‚ة•دٹ·‚·‚éƒcپ[ƒ‹‚إ‚ ‚éپB‚±‚ê‚حپAƒRƒ}ƒ“ƒhƒvƒچƒ“ƒvƒg‚إژہچs‚·‚éƒcپ[ƒ‹‚إپAڈ‰گSژز‚ھٹب’P‚ةژg‚¦‚é‚à‚ج‚إ‚ح‚ب‚¢‚ج‚إپA‚±‚جƒcپ[ƒ‹‚»‚ج‚à‚ج‚ًژg‚¤‚±‚ئ‚ح‚¨ٹ©‚ك‚µ‚ب‚¢پB‚±‚±‚إ‚حپA‚±‚جƒcپ[ƒ‹‚ھپAƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ة‚ا‚ج‚و‚¤‚بچ\‘¢‚ً—^‚¦‚ؤ‚¢‚é‚©‚ًŒ©‚邱‚ئ‚إپAXML•¶ڈ‘‚ئ‚¢‚¤‚à‚ج‚جگ«ٹi‚جˆê’[‚ً‚آ‚©‚قژèڈ•‚¯‚ئ‚µ‚ؤ‚¢‚½‚¾‚«‚½‚¢پB
پ،DTD•t‚«‚جXML•¶ڈ‘
پ@‚ـ‚¸پAˆب‰؛‚ج‚و‚¤‚ب3چs‚جƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ھ‚ ‚ء‚½‚ئ‚µ‚و‚¤پB
1:پ@چ،“ْ‚àFF‚ً‚â‚ء‚½پB 2:پ@‚إ‚àپA‚»‚ë‚»‚ëگQ‚و‚¤‚ئژv‚ء‚½ژ‚ةŒہ‚ء‚ؤپAƒ‚پ[ƒOƒٹ‚ھڈo‚ؤ‚±‚ب‚¢‚ج‚ح‚ب‚؛‚¾‚낤پB 3:پ@1“ْ’†ژdژ–‚ً–Y‚ê‚ؤFF‚ة‚ذ‚½‚ء‚ؤ‚¢‚ç‚ê‚ê‚خچK‚¹‚ب‚ج‚ة‚ثپB
پ@‚±‚ê‚ًپAtxt2xml (-pƒ‚پ[ƒhژg—p) ‚إXML•¶ڈ‘‚ة•دٹ·‚µ‚½Œ‹‰ت‚ھˆب‰؛‚ج’ت‚è‚ة‚ب‚éپBŒ©‚ؤ‚¨•ھ‚©‚è‚ج’ت‚èپA”ڑ”“I‚ةڈî•ٌ—ت‚ھ‘‚¦‚ؤ‚¢‚éپB
1:پ@<?xml version='1.0'?> 2:پ@<!DOCTYPE document [ 3:پ@<!ENTITY lt "<"> 4:پ@<!ENTITY gt ">"> 5:پ@<!ENTITY amp "&"> 6:پ@<!ENTITY apos "'"> 7:پ@<!ENTITY quot """> 8:پ@<!ELEMENT fileName (#PCDATA)> 9:پ@<!ELEMENT timeLastAccess (#PCDATA)> 10:پ@<!ELEMENT timeCreation (#PCDATA)> 11:پ@<!ELEMENT timeModify (#PCDATA)> 12:پ@<!ELEMENT fileSize (#PCDATA)> 13:پ@<!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14:پ@<!ELEMENT p (#PCDATA)> 15:پ@<!ELEMENT document (head,(p*))> 16:پ@]> 17:پ@<document> 18:پ@<head> 19:پ@<fileName>delme.txt</fileName> 20:پ@<timeLastAccess>Sun Jul 16 16:50:05 2000</timeLastAccess> 21:پ@<timeCreation>Wed Apr 05 17:12:46 2000</timeCreation> 22:پ@<timeModify>Sun Jul 16 16:48:56 2000</timeModify> 23:پ@<fileSize>170</fileSize> 24:پ@</head> 25:پ@<p>پ@چ،“ْ‚àFF‚ً‚â‚ء‚½پB</p> 26:پ@<p>پ@‚إ‚àپA‚»‚ë‚»‚ëگQ‚و‚¤‚ئژv‚ء‚½ژ‚ةŒہ‚ء‚ؤپAƒ‚پ[ƒOƒٹ‚ھڈo‚ؤ‚±‚ب‚¢‚ج‚ح‚ب‚؛‚¾‚낤پB</p> 27:پ@<p>پ@1“ْ’†ژdژ–‚ً–Y‚ê‚ؤFF‚ةگZ‚ء‚ؤ‚¢‚ç‚ê‚ê‚خچK‚¹‚ب‚ج‚ة‚ثپB</p> 28:پ@</document>
پ@‚±‚ê‚ة‚آ‚¢‚ؤ‰ًگà‚·‚éپB‚ـ‚¸1چs–ع‚حپA‚¨“éگُ‚ف‚جXMLگ錾‚إ‚ ‚éپB
پ@2پ`16چs–ع‚حپADTDپiDocument Type Definitionپj‚ھ–„‚كچ‚ـ‚ê‚ؤ‚¢‚éپB‚±‚ê‚حپA‚±‚ج•¶ڈ‘‚ةٹـ‚ـ‚ê‚éڈî•ٌ–{‘ج‚ج‹–‚³‚ê‚éڈ‘ژ®‚ً–¾ژ¦“I‚ةڈ‘‚¢‚½‚à‚ج‚إ‚ ‚éپBXML•¶ڈ‘‚جٹO‘¤‚ة’u‚¢‚ؤژQڈئ‚·‚邱‚ئ‚ھ‘½‚¢‚ھپA‚±‚ج—ل‚إ‚ح“à•”‚ة–„‚كچ‚قŒ`‚ً‘I‘ً‚µ‚ؤ‚¢‚éپB2چs–ع‚ج<!DOCTYPE ... [ ‚ھDTD‚جگ錾‚جٹJژn‚ًژ¦‚µ‚ؤ‚¢‚éپB‚»‚µ‚ؤپA16چs–ع‚ج ]>‚ھDTD‚جڈI‚ي‚è‚ًژ¦‚µ‚ؤ‚¢‚éپB
پ@‚³‚ç‚ةDTD‚ًگ[‚Œ©‚ؤ‚¢‚‚ئپA3پ`7چs–ع‚حپAXML•¶ڈ‘‚ج‚¨–ٌ‘©‚ج’è‹`‚ئ‚ب‚ء‚ؤ‚¢‚éپB‚±‚ê‚حپAXML‚جƒ}پ[ƒNƒAƒbƒv‚إ“ءژê‚بˆس–،‚ًژ‚آ‹Lچ†‚ئ“™‰؟‚جژہ‘ج‚ج’è‹`‚إ‚ ‚éپB‚±‚ج’è‹`‚ة‚و‚ء‚ؤپA<‹Lچ†‚ً‹Lڈq‚·‚éچغ‚ةپA<‚ئ‹Lڈq‚إ‚«‚é‚و‚¤‚ة‚ب‚é‚ج‚إ‚ ‚éپi‚½‚¾‚µپADTD‚ج‚ب‚¢گ®Œ`ژ®‚جXML•¶ڈ‘‚à‚ ‚肦‚é‚ج‚إپA‚±‚ج’è‹`‚ح‚ب‚‚ؤ‚àپA‹@”\‚ح—LŒّ‚إ‚ ‚éپjپB
پ@8پ`15چs–ع‚حپA—v‘f‚ج•ہ‚رڈ‡‚ًگ§–ٌ‚·‚邽‚ك‚ة‹Lڈq‚³‚ê‚ؤ‚¢‚é‚à‚ج‚إ‚ ‚éپB‚±‚ê‚ة‚و‚ء‚ؤپA’è‹`‚³‚ê‚ؤ‚¢‚ب‚¢—v‘f–¼‚ًڈ‘‚¢‚½‚èپA‹–‚³‚ê‚ب‚¢ڈ‡”ش‚إ—v‘f‚ً‹Lڈq‚µ‚½‚ئ‚«‚ةپA‚»‚ê‚ًƒGƒ‰پ[‚ئ‚µ‚ؤ”»’è‚·‚邱‚ئ‚ھ‰آ”\‚ئ‚ب‚éپB
پ@‚±‚جXML•¶ڈ‘‚ةDTD‚ھ–„‚كچ‚ـ‚ê‚ؤ‚¢‚é‚ج‚حپA“`‘—‚ج“r’†‚إ‰»‚¯‚½‚è‰َ‚ꂽ‚肵‚½ڈêچ‡پA‚»‚ê‚ً‚ ‚é’ِ“xژ©“®“I‚ةŒںڈo‚·‚邽‚ك‚إ‚ ‚éپB‚آ‚ـ‚èپA•¶ڈ‘–{‘ج‚ًDTD‚ًƒڈƒ“ƒZƒbƒg‚جƒtƒ@ƒCƒ‹‚ةژû‚ك‚邱‚ئ‚إپA–{—ˆ‚ح—¼ژز‚ھ–³–µڈ‚‚إ‚ ‚é‚ئچl‚¦‚ç‚ê‚éپB‚»‚ê‚ھپA’تگM‚جŒ‹‰ت‚جژَژو‘¤‚إƒ`ƒFƒbƒN‚µ‚½‚ئ‚«‚ةƒGƒ‰پ[‚ھڈo‚é‚و‚¤‚إ‚ ‚ê‚خپA“`‘—‚ج“r’†‚إ‰َ‚ꂽ‚ئچl‚¦‚ç‚ê‚é‚ي‚¯‚إ‚ ‚éپB
پ@‚³‚ؤپA‚»‚جژں‚ج17چs–عˆبچ~‚ھپA•¶ڈ‘‚ج–{‘ج‚إ‚ ‚éپB<document>—v‘f‚ھپA‚±‚ج•¶ڈ‘‚جƒ‹پ[ƒg—v‘f‚إ‚ ‚éپB‚»‚جژں‚ة‚·‚®•¶ڈ‘–{‘ج‚ھژn‚ـ‚é‚ئژv‚¢‚«‚âپAژں‚ة‚حŒ³‚جƒtƒ@ƒCƒ‹‚ة‚ح‚ب‚¢ڈî•ٌ‚ھ‚آ‚¬‚آ‚¬‚ئ–„‚كچ‚ـ‚ê‚ؤ‚¢‚éپB<head>—v‘f‚حپA•¶ڈ‘‚جƒwƒbƒ_پ[ڈî•ٌ‚ً•t‰ء‚·‚邽‚ك‚ة—pˆس‚³‚ê‚ؤ‚¢‚éپB‚±‚ج’†‚ة‚حپAŒ³ƒtƒ@ƒCƒ‹‚جƒtƒ@ƒCƒ‹–¼‚âƒ^ƒCƒ€ƒXƒ^ƒ“ƒv‚ب‚ا‚جڈî•ٌ‚ھ•غ‘¶‚³‚ê‚ؤ‚¢‚éپB‚±‚ج‚و‚¤‚بڈî•ٌ‚ھ‚ي‚´‚ي‚´•غ‘¶‚³‚ê‚ؤ‚¢‚é‚ج‚حپAƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ًXML‚ة•دٹ·‚µ‚ؤ‰½‚©‚جڈˆ—‚ًچs‚ء‚ؤ‚©‚çپA‚ـ‚½ƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ة–ك‚·‚±‚ئ‚ً”z—¶‚µ‚ؤ‚¢‚邽‚ك‚إ‚ ‚éپB
پ@‚±‚±‚إ‚حپAŒ³ƒtƒ@ƒCƒ‹‚جƒtƒ@ƒCƒ‹–¼‚ئ‚µ‚ؤ<fileName>—v‘fپAچإڈIƒAƒNƒZƒX‚ج“ْ•tژچڈ‚ئ‚µ‚ؤ<timeLastAccess>—v‘fپAƒtƒ@ƒCƒ‹‚جچىگ¬“ْ•tژچڈ‚ئ‚µ‚ؤ<timeCreation>—v‘fپAچإŒم‚ة•دچX‚³‚ꂽ“ْ•tژچڈ‚ئ‚µ‚ؤ<timeModify>—v‘fپAŒ³ƒtƒ@ƒCƒ‹‚جƒtƒ@ƒCƒ‹ƒTƒCƒY‚ئ‚µ‚ؤ<fileSize>—v‘f‚ھ‹Lڈq‚³‚ê‚ؤ‚¢‚éپB‚±‚ê‚ç‚جڈî•ٌ‚حپA‚ ‚ê‚خ•ض—ک‚ئ‚¢‚¤‚±‚ئ‚إٹـ‚ـ‚ê‚ؤ‚¢‚é‚à‚ج‚إپA•K‚¸‚±‚ê‚ًژg‚ء‚ؤڈˆ—‚µ‚ب‚¯‚ê‚خ‚ب‚ç‚ب‚¢‚ئ‚¢‚¤‚à‚ج‚إ‚ح‚ب‚¢پB
پ@‚³‚ؤپA34چs–ع‚ة<head>‚ج•آ‚¶ƒ^ƒO‚ھڈoŒ»‚µپA‚â‚ء‚ئƒwƒbƒ_پ[‚ھڈI‚ي‚éپB‚»‚µ‚ؤپA35پ`37چs–ع‚ھپA‚à‚ئ‚à‚ئ‚جƒvƒŒپ[ƒ“ƒeƒLƒXƒg‚ةٹـ‚ـ‚ê‚ؤ‚¢‚½ڈî•ٌ‚ھڈoŒ»‚·‚éپBŒ³ƒfپ[ƒ^‚ج1چs‚ح1’i—ژ‚ئŒ©‚ب‚³‚êپA<p>—v‘f‚ة‚و‚ء‚ؤƒ}پ[ƒNƒAƒbƒv‚³‚ê‚ؤ‚¢‚éپB
پ@‚±‚جXML•¶ڈ‘‚حپA‚ ‚éژي‚جXML‚炵‚³‚ً’¼گع“I‚ة•\Œ»‚µ‚ؤ‚¢‚éپBŒ©‚ؤ•ھ‚©‚é’ت‚èپA‚±‚جXML•¶ڈ‘‚ة‚حˆب‰؛‚ج‚و‚¤‚ب“ء’¥‚ھ‚ ‚éپB
- –{•¶‚ج‚ظ‚©‚ة‚³‚ـ‚´‚ـ‚بڈî•ٌ‚ھ‚آ‚¢‚ؤ‚¢‚é
- DTD‚ح‚«‚؟‚ٌ‚ئڈ‘‚‚ئ‚¯‚ء‚±‚¤•،ژG‚إ’·‚‚ب‚éپB‚ـ‚½•\‹L‚à’¼گع“I‚إ‚ح‚ب‚•ھ‚©‚è‚ة‚‚¢
- DTDˆبٹO‚ة‚àپA–{•¶ˆبٹO‚جڈî•ٌ‚ھ‘½‚•t‰ء‚³‚ê‚ؤ‚¢‚éپiژه—v‚بڈî•ٌ‚إ‚ح‚ب‚پA‚»‚جڈî•ٌ‚جژü•س‚ج•âڈ•“I‚بڈî•ٌ‚ًƒپƒ^ƒfپ[ƒ^‚ئŒؤ‚شپj
- ˆظ‚ب‚é–ع“I‚جڈî•ٌ‚ھ1Œآ‚جXML•¶ڈ‘‚ة‹¤‘¶‚µ‚ؤ‚¢‚é
پ@‚±‚ê‚ç‚حپA•K‚¸XML•¶ڈ‘‚ةŒ©‚ç‚ê‚é‚ي‚¯‚إ‚ح‚ب‚¢‚ھپA”ٌڈي‚ة‚µ‚خ‚µ‚خ–ع‚ة‚·‚éڈَ‹µ‚إ‚ ‚éپB“TŒ^“I‚بXML•¶ڈ‘‚جژg‚¢•û‚جƒpƒ^پ[ƒ“‚ئŒ¾‚ء‚ؤ‚و‚¢‚¾‚낤پB
CSVƒtƒ@ƒCƒ‹‚ًXML‚إ‹Lڈq‚·‚é
پ@•¶ڈ‘“I‚بƒTƒ“ƒvƒ‹‚جژں‚حپAڈƒگˆ‚ةƒfپ[ƒ^گ«‚ج‹‚¢XML•¶ڈ‘‚ًƒTƒ“ƒvƒ‹‚ئ‚µ‚ؤژو‚èڈم‚°‚ؤ‚ف‚و‚¤پB‘O‚ج—ل‚إژg‚ء‚½txt2xml‚حپACSVƒtƒ@ƒCƒ‹‚ًXML‚ة•دٹ·‚·‚é‹@”\‚àژ‚ء‚ؤ‚¢‚éپB‚»‚±‚إپAExcel‚إ•\‚ًچى‚èپA‚±‚ê‚ًCSVŒ`ژ®‚إ•غ‘¶‚µپAXML‚ة•دٹ·‚µ‚ؤ‚ف‚و‚¤پiCSVŒ`ژ®‚ئ‚حپAƒfپ[ƒ^‚ھƒJƒ“ƒ}پi,پj‚إ‹وگط‚ç‚ꂽƒVƒ“ƒvƒ‹‚بƒfپ[ƒ^Œ`ژ®پjپB
پ،HTML‚ةژ—‚¹‚½•دٹ·—ل
پ@Œ³ƒfپ[ƒ^‚حˆب‰؛‚ج“à—e‚إ‚ ‚é‚ئ‚·‚éپB
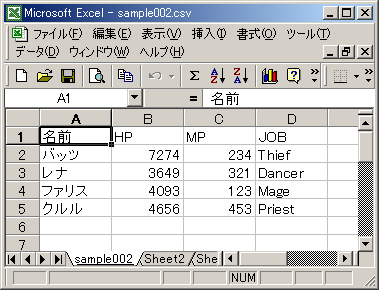
پ@‚±‚ê‚ً•غ‘¶‚µ‚½CSVƒtƒ@ƒCƒ‹‚ج“à—e‚حˆب‰؛‚ج‚و‚¤‚ة‚ب‚éپB
1:پ@–¼‘O,HP,MP,JOB 2:پ@ƒoƒbƒc,7274,234,Thief 3:پ@ƒŒƒi,3649,321,Dancer 4:پ@ƒtƒ@ƒٹƒX,4093,123,Mage 5:پ@ƒNƒ‹ƒ‹,4656,453,Priest
پ@‚±‚جƒtƒ@ƒCƒ‹‚ًپAtxt2xmlپi-csvƒ‚پ[ƒhپj‚إXML•¶ڈ‘‚ة•دٹ·‚µ‚½Œ‹‰ت‚حپAˆب‰؛‚ج‚و‚¤‚ة‚ب‚éپB
1:پ@<?xml version='1.0'?> 2:پ@<!DOCTYPE table [ 3:پ@<!ENTITY lt "<"> 4:پ@<!ENTITY gt ">"> 5:پ@<!ENTITY amp "&"> 6:پ@<!ENTITY apos "'"> 7:پ@<!ENTITY quot """> 8:پ@<!ELEMENT fileName (#PCDATA)> 9:پ@<!ELEMENT timeLastAccess (#PCDATA)> 10:پ@<!ELEMENT timeCreation (#PCDATA)> 11:پ@<!ELEMENT timeModify (#PCDATA)> 12:پ@<!ELEMENT fileSize (#PCDATA)> 13:پ@<!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14:پ@<!ELEMENT td (#PCDATA)> 15:پ@<!ELEMENT tr (td)*> 16:پ@<!ELEMENT table (head,tr*)> 17:پ@]> 18:پ@<table> 19:پ@<head> 20:پ@<fileName>delme.csv</fileName> 21:پ@<timeLastAccess>Sun Jul 16 16:42:18 2000</timeLastAccess> 22:پ@<timeCreation>Sat Jul 15 21:18:44 2000</timeCreation> 23:پ@<timeModify>Sat Jul 15 21:18:44 2000</timeModify> 24:پ@<fileSize>192</fileSize> 25:پ@</head> 26:پ@<tr> 27:پ@<td>–¼‘O</td> 28:پ@<td>HP</td> 29:پ@<td>MP</td> 30:پ@<td>JOB</td> 31:پ@</tr> 32:پ@<tr> 33:پ@<td>ƒoƒbƒc</td> 34:پ@<td>7274</td> 35:پ@<td>234</td> 36:پ@<td>Thief</td> 37:پ@</tr> 38:پ@<tr> 39:پ@<td>ƒŒƒi</td> 40:پ@<td>3649</td> 41:پ@<td>321</td> 42:پ@<td>Dancer</td> 43:پ@</tr> 44:پ@<tr> 45:پ@<td>ƒtƒ@ƒٹƒX</td> 46:پ@<td>4093</td> 47:پ@<td>123</td> 48:پ@<td>Mage</td> 49:پ@</tr> 50:پ@<tr> 51:پ@<td>ƒNƒ‹ƒ‹</td> 52:پ@<td>4656</td> 53:پ@<td>453</td> 54:پ@<td>Priest</td> 55:پ@</tr> 56:پ@<tr> 57:پ@</tr> 58:پ@</table>
پ@1پ`17چs–ع‚ةٹض‚µ‚ؤ‚حپADTD‚ج’è‹`‚ج“à—e‚حˆل‚¤‚à‚ج‚جپAٹî–{“I‚ة‘O‚ج—ل‚ئ“¯‚¶‚ب‚ج‚إپAگà–¾‚حڈب‚پBtxt2xml‚جCSV•دٹ·‹@”\‚حپA‚¢‚؟‚اXML‚ة•دٹ·‚µ‚½ڈم‚إپAƒXƒ^ƒCƒ‹ƒVپ[ƒg•دٹ·Œ¾ŒêپiXSLTپj‚إHTML‚ة•دٹ·‚·‚邱‚ئ‚إپAژ©“®“I‚ةCSVڈî•ٌ‚ًŒِٹJ‚·‚éƒyپ[ƒW‚ًگ¶گ¬‚·‚邱‚ئ‚ًˆسگ}‚µ‚ؤچى‚ç‚ꂽ‚à‚ج‚إ‚ ‚éپB‚»‚ج‚½‚كپACSVڈî•ٌ‚ج’†‚جˆس–،‚ةٹض‚µ‚ؤ‚حپA‚¢‚ء‚³‚¢خژق‚µ‚ؤ‚¢‚ب‚¢پB‚»‚ê‚و‚è‚àپAHTML‚ض‚ج•دٹ·‚ً—eˆص‚ة‚·‚邽‚ك‚ةپAHTML‚جƒeپ[ƒuƒ‹ٹضŒW‚جڈ‘ژ®‚ةژ—‚½Œ`‚إپAƒfپ[ƒ^‚ًڈo—ح‚µ‚ؤ‚¢‚éپBژہچغپA‚±‚جƒfپ[ƒ^‚ًپAHTML‚ة•دٹ·‚·‚éXSLTƒXƒNƒٹƒvƒg‚ًڈ‘‚‚ج‚ح—eˆص‚إ‚ ‚éپiXSLT‚ةٹض‚µ‚ؤ‚ح•ت“r‰ü‚ك‚ؤژو‚èڈم‚°‚é—\’è‚إ‚ ‚éپjپB
پ@‚µ‚©‚µپA‚±‚جXML•¶ڈ‘‚حپA“à—e‚ًƒfپ[ƒ^‚ئ‚µ‚ؤڈˆ—‚·‚é‚ة‚ح‚ ‚ـ‚è“K‚µ‚ؤ‚¢‚ب‚¢پB—ل‚¦‚خپA‚±‚جƒfپ[ƒ^‚ًŒ³‚ةپAHP‚جگ”’l‚ھچإ‘ه‚ة‚ب‚郌ƒRپ[ƒh‚ج–¼‘O‚ًڈo—ح‚·‚éپA‚ئ‚¢‚ء‚½ڈˆ—‚ً‹Lڈq‚·‚é‚ج‚ح–ت“|‚إ•ھ‚©‚è‚ة‚‚¢‚à‚ج‚ة‚ب‚éپB‚ـ‚½پAگlٹش‚ھ‚±‚جXML•¶ڈ‘‚ًŒ©‚ؤ‚àپAˆسگ}‚·‚é“à—e‚ً”»’f‚·‚é‚ج‚ح—eˆص‚إ‚ح‚ب‚¢پB
پ،گlٹش‚ة•ھ‚©‚è‚â‚·‚‚µ‚ؤ‚ف‚é
پ@‚±‚ê‚ة‘خڈˆ‚·‚é‚ذ‚ئ‚آ‚جچl‚¦•û‚حپACSVƒtƒ@ƒCƒ‹‚جچإڈ‰‚ج1چs‚ًƒtƒBپ[ƒ‹ƒh–¼‚جƒٹƒXƒg‚ئŒ©‚ب‚µ‚ؤپA‚±‚ê‚ً—v‘f–¼‚ئ‚µ‚ؤXML•¶ڈ‘‚ًگ¶گ¬‚·‚é‚ئ‚¢‚¤‚à‚ج‚إ‚ ‚éپBtxt2xml‚ج-csv2ƒ‚پ[ƒh‚ح‚±‚ê‚ًˆسگ}‚µ‚ؤ‚¢‚éپB‚±‚ê‚ً—p‚¢‚ؤXML•¶ڈ‘‚ة•دٹ·‚µ‚½Œ‹‰ت‚حˆب‰؛‚ج‚و‚¤‚ة‚ب‚éپB
1:پ@<?xml version='1.0'?> 2:پ@<!DOCTYPE table [ 3:پ@<!ENTITY lt "<"> 4:پ@<!ENTITY gt ">"> 5:پ@<!ENTITY amp "&"> 6:پ@<!ENTITY apos "'"> 7:پ@<!ENTITY quot """> 8:پ@<!ELEMENT fileName (#PCDATA)> 9:پ@<!ELEMENT timeLastAccess (#PCDATA)> 10:پ@<!ELEMENT timeCreation (#PCDATA)> 11:پ@<!ELEMENT timeModify (#PCDATA)> 12:پ@<!ELEMENT fileSize (#PCDATA)> 13:پ@<!ELEMENT head (fileName|timeLastAccess|timeCreation|timeModify|fileSize)*> 14:پ@<!ELEMENT –¼‘O (#PCDATA)> 15:پ@<!ELEMENT HP (#PCDATA)> 16:پ@<!ELEMENT MP (#PCDATA)> 17:پ@<!ELEMENT JOB (#PCDATA)> 18:پ@<!ELEMENT record (–¼‘O,HP,MP,JOB)> 19:پ@<!ELEMENT table (head,record*)>]> 20:پ@<table> 21:پ@<head> 22:پ@<fileName>delme.csv</fileName> 23:پ@<timeLastAccess>Sun Jul 16 16:52:21 2000</timeLastAccess> 24:پ@<timeCreation>Sat Jul 15 21:18:44 2000</timeCreation> 25:پ@<timeModify>Sat Jul 15 21:18:44 2000</timeModify> 26:پ@<fileSize>192</fileSize> 27:پ@</head> 28:پ@<record> 29:پ@<–¼‘O>ƒoƒbƒc</–¼‘O> 30:پ@<HP>7274</HP> 31:پ@<MP>234</MP> 32:پ@<JOB>Thief</JOB> 33:پ@</record> 34:پ@<record> 35:پ@<–¼‘O>ƒŒƒi</–¼‘O> 36:پ@<HP>3649</HP> 37:پ@<MP>321</MP> 38:پ@<JOB>Dancer</JOB> 39:پ@</record> 40:پ@<record> 41:پ@<–¼‘O>ƒtƒ@ƒٹƒX</–¼‘O> 42:پ@<HP>4093</HP> 43:پ@<MP>123</MP> 44:پ@<JOB>Mage</JOB> 45:پ@</record> 46:پ@<record> 47:پ@<–¼‘O>ƒNƒ‹ƒ‹</–¼‘O> 48:پ@<HP>4656</HP> 49:پ@<MP>453</MP> 50:پ@<JOB>Priest</JOB> 51:پ@</record> 52:پ@</table>
پ@‚±‚جƒٹƒXƒg‚إ‚حپA1چs•ھ‚جƒfپ[ƒ^‚ھ<record>—v‘f‚ة‚و‚ء‚ؤژ¦‚³‚ê‚ؤ‚¢‚éپB‚»‚µ‚ؤپAŒآپX‚جƒfپ[ƒ^‚حپA1چs–ع‚ة‹Lچع‚³‚ꂽ–¼‘O‚ھ—v‘f–¼‚إ‚ ‚é‚ئ‚µ‚ؤپAƒ^ƒO•t‚¯‚³‚ê‚ؤ‚¢‚éپB‚±‚ê‚ًŒ©‚ê‚خپA‚ا‚جگ”’l‚ھHP‚إ‚ ‚èپA‚»‚ê‚ة‘خ‰‚·‚é–¼‘O‚ھ‚ا‚ê‚إ‚ ‚é‚©‚ھˆê–ع—ؤ‘R‚ئ‚ب‚éپB
پ@—ل‚¦‚خپA7274‚ئ‚¢‚¤’l‚ھپA<HP>‚ئ‚¢‚¤—v‘f‚ج’l‚ئ‚ب‚邱‚ئ‚ة‚و‚ء‚ؤپAHP‚ئ‚¢‚¤ڈî•ٌ‚ئپA7274‚ئ‚¢‚¤’l‚ھŒف‚¢‚ةگ[‚ٹضکA‚µ‚ؤ‚¢‚邱‚ئ‚ھپAXMLƒfپ[ƒ^ڈم‚جچ\•¶‚ئ‚µ‚ؤژ¦‚³‚ê‚éپB‚ـ‚½پA‚±‚ê‚ç‚ج—v‘f‚جƒOƒ‹پ[ƒv‚ھپA<record>—v‘f‚ة‚و‚ء‚ؤƒOƒ‹پ[ƒv‰»‚³‚ê‚ؤ‚¢‚邽‚ك‚ةپA“¯‚¶<HP>‚ھ•،گ”‚ ‚ء‚ؤ‚àپA‚»‚ꂼ‚ê‚ھ‘¼‚ج‚ا‚جƒfپ[ƒ^‚ئƒOƒ‹پ[ƒv‚ًŒ`گ¬‚µ‚ؤ‚¢‚é‚©‚ھپA–¾—ؤ‚ة•ھ‚©‚éپB
پ@‚±‚ج‚و‚¤‚بŒ`‚إپA’P‚ةƒfپ[ƒ^‚ً—ٌ‹“‚·‚é‚ج‚إ‚ح‚ب‚پAŒآپX‚جƒfپ[ƒ^‚ة‘خ‚µ‚ؤ—v‘f‚â‘®گ«‚ً—p‚¢‚ؤˆس–،‚أ‚¯‚µ‚ؤ‚¢‚‚ج‚ھپAXML‚ة‚و‚éƒfپ[ƒ^ˆµ‚¢‚جٹî–{‚إ‚ ‚éپB
پ،—v‘f‚©‘®گ«‚©
پ@چ،‰ٌ‚ج—ل‚إ‚حپA—v‘f‚ج’l‚ًژg‚ء‚ؤƒfپ[ƒ^‚ً•\Œ»‚µ‚ؤ‚¢‚é‚ھپA‘®گ«‚ًژg‚¤‚â‚è•û‚à‚ ‚éپB—ل‚¦‚خپAڈم‚ج—ل‚إژ¦‚µ‚½1چsپA
<HP>7274</HP>
پ@‚±‚ê‚ًˆب‰؛‚ج‚و‚¤‚ة•\Œ»‚·‚é‚â‚è•û‚à‚ ‚éپB
<HP value="7274"/>
پ@—v‘f‚ج’l‚ًژg‚¤•û–@‚ئپA‘®گ«‚ًژg‚¤•û–@‚حپA‚ا‚؟‚ç‚àˆê’·ˆê’Z‚ھ‚ ‚ء‚ؤپA‚ا‚؟‚ç‚ھگ³‚µ‚¢‚ئ‚¢‚¤‚à‚ج‚إ‚ح‚ب‚¢پBڈَ‹µ‚â–ع“I‚ة‚و‚ء‚ؤژg‚¢•ھ‚¯‚é‚à‚ج‚إ‚ ‚éپB—ل‚¦‚خپA—v‘f‚ج’l‚ًژg‚¤ڈêچ‡‚حپAچX‚ة—v‘f‚ًƒlƒXƒg‚µ‚ؤ‹Lڈq‚·‚邱‚ئ‚ھ‚إ‚«‚é‚ج‚إپA‚و‚è•،ژG‚بڈî•ٌ‚ً‹Lڈq‚·‚邱‚ئ‚ة“K‚·‚éپB‚»‚ê‚ة‘خ‚µ‚ؤپA‘®گ«‚ً—p‚¢‚é•û–@‚ح’l‚ة—v‘f‚ًٹـ‚ك‚邱‚ئ‚ح‚إ‚«‚ب‚¢‚ھپA•،گ”‚ج’l‚ً1‚آ‚ج—v‘f‚ةٹضکA‚أ‚¯‚é‚ج‚ھ—eˆص‚إ‚ ‚éپB
Œ»ژہ‚ةژg‚ي‚ê‚éژہ—ل
پ@‚³‚ؤپAژہچغ‚ةŒ»ڈê‚إژg‚ي‚ê‚ؤ‚¢‚é–{ٹi“I‚بXML•¶ڈ‘‚حپA‚ا‚ج‚و‚¤‚ب•µˆح‹C‚إ‹Lڈq‚³‚ê‚ؤ‚¢‚é‚ج‚¾‚낤‚©پB
پ@‚±‚±‚إ‚حپA“ْ–{“dژqڈo”إ‹¦‰ï(JEPA)‚ھ“dژqڈo”إ—p‚ج•Wڈ€Œ`ژ®‚ئ‚µ‚ؤٹJ”‚µ‚ؤ‚¢‚錾ŒêJepaX‚ً—ل‚ئ‚µ‚ؤŒ©‚ؤ‚ف‚و‚¤پBJepaX‚جژd—lڈ‘‚حپAJepaXژ©گg‚إ‹Lڈq‚³‚ê‚ؤ‚¢‚éپB‚»‚جJepaXژd—lڈ‘‚جˆê•””²گˆ‚ًŒ©‚ؤ‚ف‚و‚¤پB
1:پ@<bookinfo>
2:پ@<book-title reading="JepaX">JepaX</book-title>
3:پ@<book-subtitle>JEPA“dژqڈo”إŒًٹ·ƒtƒHپ[ƒ}ƒbƒg</book-subtitle>
4:پ@<edition>Draft: Version 0.9</edition>
5:پ@<book-author role="’ک" reading="ƒjƒzƒ“ƒfƒ“ƒVƒVƒ…ƒbƒpƒ“ƒLƒ‡ƒEƒJƒCپ@ƒVƒ…ƒbƒpƒ“ƒfپ[ƒ^ƒtƒHپ[ƒ}ƒbƒgƒqƒ‡ƒEƒWƒ…ƒ“ƒJƒCƒCƒ“ƒJƒC">“ْ–{“dژqڈo”إ‹¦‰ïپ@ڈo”إƒfپ[ƒ^ƒtƒHپ[ƒ}ƒbƒg•Wڈ€‰»Œ¤‹†ˆدˆُ‰ï</book-author>
6:پ@<pub-date>19990930</pub-date>
7:پ@<publisher>“ْ–{“dژqڈo”إ‹¦‰ï</publisher>
8:پ@</bookinfo>
پ@‚±‚ê‚ح“dژqڈ‘گذ‚ج–{•¶‚إ‚ح‚ب‚پA‰œ•t‚ب‚ا‚جڈî•ٌ‚ً“dژq“I‚بƒtƒHپ[ƒ}ƒbƒg‚إژ‚آڈ‘ژڈڈî•ٌ‚ً‹Lڈq‚µ‚½•”•ھ‚ج”²گˆ‚إ‚ ‚éپB‚±‚±‚إ‚حپA“ء‚ة5چs–ع‚ًŒ©‚ؤ‚¢‚½‚¾‚«‚½‚¢پB<book-author>—v‘f‚حپA’کژز‚ةٹض‚·‚éڈî•ٌ‚ً‹Lڈq‚·‚é—v‘f‚إ‚ ‚éپB‚»‚ج“à—e‚حپA“–‘R’کژز–¼‚إ‚ ‚éپB‚µ‚©‚µپA‚±‚ج—v‘f‚ة‚حپA“à—e‚ئ‚µ‚ؤ•¶ژڑ—ٌ‚ھڈ‘‚©‚ê‚ؤ‚¢‚é‚ظ‚©‚ةپA2‚آ‚ج‘®گ«‚ھ•t‚¢‚ؤ‚¢‚éپB
پ@1‚آ‚حrole‚ئ‚¢‚¤–¼‘O‚ج‘®گ«‚إپA‚±‚ê‚حپA’کژز‚ج–ًٹ„‚ًژ¦‚·ڈî•ٌ‚إ‚ ‚éپBپg’کپhپAپg–َپhپAپgٹؤڈCپhپAپg•زپhپAپg‰وپh‚ب‚ا‚ً‹Lڈq‚µ‚ؤژg‚¤پB‚¾‚ھ‚ب‚؛‘®گ«‚ب‚ج‚¾‚낤‚©پH ‚±‚ê‚à—v‘f‚ئ‚µ‚ؤ<book-author>—v‘f‚ئ•ہ—ٌ‚ة—ٌ‹L‚µ‚ؤ‚حƒ_ƒپ‚ب‚ج‚¾‚낤‚©پH ‚»‚ج‰ٌ“ڑ‚ح‚±‚¤‚¾پB’کژز‚ھ•،گ”‚¢‚éڈêچ‡‚حپA<book-author>—v‘f‚ً•،گ”—ٌ‹“‚·‚邱‚ئ‚ة‚ب‚éپB‚»‚±‚إپA<book-author>—v‘f‚ج‘®گ«‚ئ‚µ‚ؤپA–ًٹ„‚ھ‹Lڈq‚³‚ê‚éˆس–،‚ھگ¶‚¶‚éپB‚آ‚ـ‚èپA‚»‚ꂼ‚ê‚ج’کژز‚ة‘خ‚µ‚ؤپA–ًٹ„‚ھ‘®گ«‚ئ‚µ‚ؤ•t‚Œ`‚ة‚ب‚邽‚كپA‚ا‚ج–ًٹ„‚ھپA’N‚ة‘خ‰‚·‚é‚ج‚©‚ھ–¾—ؤ‚ة‚ب‚é‚ج‚إ‚ ‚éپB‚±‚ê‚ھ–¾ژ¦‚³‚ê‚邱‚ئ‚إپA“ء’è‚ج–¼‘O‚جگl‚ھ–َ‚µ‚½–{‚¾‚¯‚ًپiژ©•ھ‚إ’ک‚µ‚½–{‚حڈœ‚¢‚ؤپj’T‚·پA‚ئ‚¢‚¤Œںچُ‚à‰آ”\‚ة‚ب‚éپB
پ@‚à‚¤1‚آ‚جreading‘®گ«‚حپA“à—e‚ج•¶ژڑ—ٌ‚ج“ا‚ف‚ً–¾ژ¦“I‚ةژ¦‚·‚½‚ك‚ةژg—p‚³‚ê‚é‘®گ«‚إ‚ ‚éپB’کژز‚ج–¼‘O‚ج“ا‚ف•û‚ھ•ھ‚©‚ç‚ب‚¢‚ئ‚¢‚¤‚و‚¤‚بڈَ‹µ‚ح‚µ‚خ‚µ‚خ‹N‚«‚邱‚ئ‚¾‚ھپA‚¢‚؟‚¢‚؟ƒ‹ƒr‚ًگU‚é‚ج‚حٹ½Œ}‚³‚ê‚ب‚¢‚±‚ئ‚à‚ ‚éپB‚¾‚©‚çپA‚±‚ج‚و‚¤‚ب•\Œ»•û–@‚ةˆس–،‚ھ‚ ‚éپB‚آ‚ـ‚èپA“ا‚فڈî•ٌ‚حڈî•ٌ–{‘ج‚جˆê•”‚إ‚ح‚ب‚¢‚ھپA‚µ‚©‚µ•K—v‚بڈêچ‡‚à‚ ‚é‚ج‚إپAˆê•àˆّ‚¢‚½Œ`‚إ‹Lڈq‚·‚é•û–@‚ً—pˆس‚µ‚ؤ‚¨‚پB‚آ‚ـ‚è–{‘ج‚ح“à—e‚إپA•t‰ء“I‚بڈî•ٌ‚ح‘®گ«‚إپA‚ئ‚¢‚¤•\Œ»ƒXƒ^ƒCƒ‹‚ب‚ج‚إ‚ ‚éپB
“¯‚¶ڈî•ٌ‚ج•\Œ»‚ة‚à•،گ”‚ج•û–@‚ھ‚ ‚é
پ@ƒfپ[ƒ^‚ًXML•¶ڈ‘‚ئ‚µ‚ؤ•\Œ»‚·‚é•û–@‚ح‚¢‚ë‚¢‚ë‚ ‚éپB‚µ‚©‚µپAٹµڈK“I‚ة‚و‚ژg‚ي‚ê‚é’èگخ‚à‚ ‚éپBچ،‰ٌ‚حپA“TŒ^“I‚بƒpƒ^پ[ƒ“‚ً‚¢‚‚آ‚©ڈذ‰î‚µ‚½پB‚±‚ê‚ç‚جƒpƒ^پ[ƒ“‚حپAXML‚ًˆµ‚ء‚ؤ‚¢‚ê‚خپA‚µ‚خ‚µ‚خŒ©‚©‚¯‚邱‚ئ‚ة‚ب‚邾‚낤پB‹t‚ةپA‚±‚ê‚ھXML‚جژg‚¢•û‚ج‘S‚ؤ‚ئŒ¾‚¤‚ي‚¯‚إ‚ح‚ب‚¢پB
پ@چ،‰ٌ‚جگà–¾‚ة‘خ‚µ‚ؤ’چˆس‚·‚ׂ«‚±‚ئ‚حپA“¯‚¶ڈî•ٌ‚ً•\Œ»‚·‚é‚ة‚àپA•،گ”‚ج‚â‚è•û‚ھ‚ ‚é‚ئ‚¢‚¤‚±‚ئ‚¾پB—ل‚¦‚خپA“¯‚¶ڈî•ٌ‚ً—v‘f‚ج“à—e‚ئ‚µ‚ؤڈ‘‚‚±‚ئ‚àپA‘®گ«‚ئ‚µ‚ؤڈ‘‚‚±‚ئ‚à‚إ‚«‚éپA‚ئ‚¢‚¤‚ج‚حچإ‚à“TŒ^“I‚بˆê—ل‚إ‚ ‚éپB‚»‚µ‚ؤپA‚»‚ج‚ا‚ج‚â‚è•û‚ھ–{“–‚ةگ³‚µ‚—L‰v‚إ‚ ‚é‚©‚ج”»’f‚حپA‚½‚¢‚ض‚ٌ‚ة”÷–‚إ“‚¢پB‚ئ‚«‚ئ‚µ‚ؤپAڈيژ¯’ت‚è‚ج‹Lڈq‚ھ‚¤‚ـ‚‹@”\‚µ‚ب‚¢پA‚ئ‚¢‚¤‚±‚ئ‚·‚瑶چف‚·‚éپB‚±‚ê‚حپAŒأ‚‚ؤگV‚µ‚¢XMLƒ†پ[ƒUپ[‚ة‰غ‚¹‚ç‚ꂽ‰i‰“‚ج‰غ‘è‚إ‚ ‚éپB
پ@‚³‚ؤپAXML•¶ڈ‘‚ة‚ح‚¢‚ë‚¢‚ë‚ب•\Œ»•û–@‚ھ‚ ‚邱‚ئ‚ح•ھ‚©‚ء‚ؤ‚¢‚½‚¾‚¯‚½‚ئژv‚¤‚ھپAژہچغ‚ةƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ƒ\ƒtƒg‚إڈˆ—‚·‚éڈêچ‡‚ة‚حپA‚·‚ׂؤ‚ًژ©—R‚ةژg‚¤‚±‚ئ‚ح‚إ‚«‚¸پAƒAƒvƒٹƒPپ[ƒVƒ‡ƒ“ƒ\ƒtƒg‚ھ‘z’è‚·‚éژg‚¢•û‚ةگ§Œہ‚³‚ê‚éپB‚»‚جگ§Œہ‚ً‹Lڈq‚·‚邽‚ك‚ةپA‚¢‚ي‚ن‚éƒXƒLپ[ƒ}Œ¾Œê‚ھ‘¶چف‚·‚éپBƒXƒLپ[ƒ}Œ¾Œê‚ج’†‚إ‚àچإ‚àٹî–{‚ئ‚ب‚éDTD‚ً’ت‚µ‚ؤپAژں‰ٌ‚حپAچ\•¶‚جگ§Œہ‚ة‚آ‚¢‚ؤ‚ًچl‚¦‚ؤ‚ف‚و‚¤پB
پ@‚»‚ê‚إ‚حژں‰ٌپA‚ـ‚½‰ï‚¨‚¤پB
- XMLژd—lڈ‘‚جچ\‘¢‚ئ“ا‚ف•û
- ‘½Œ¾Œê‘خ‰‚ج–â‘è‚ئ‰ًŒˆ‚ًچl‚¦‚é
- —ژ‚ئ‚µŒٹ‚ة‚ب‚é‹َ”’•¶ژڑ‚ئ‰üچs•¶ژڑ
- Standalone‚ئ‹†‹ة‚جٹO•””ٌˆث‘¶•¶ڈ‘
- چؤ—ک—p‚إ‚«‚錾Œê‚ًXML‚إچى‚é
- ƒ{ƒLƒƒƒuƒ‰ƒٹ‚ًٹg‘ه‚·‚éپu–¼‘O‹َٹشپv
- Unicode‚إ‚à”گ¶‚·‚镶ژڑ‰»‚¯‚جٹë‹@‚ئ‰ٌ”ً
- DTD‚ً“ا‚ٌ‚إ‚ف‚و‚¤
- ƒXƒLپ[ƒ}Œ¾ŒêپuDTDپv‚ج‹@”\‚ئ–ًٹ„
- Œ»ژہ‚جXML•¶ڈ‘‚ًŒ©‚é
- XML‚جƒJƒ^ƒ`
- چإ’Z‚جXML“ü–ه‚ئƒپƒ^Œ¾Œê
Copyright © ITmedia, Inc. All Rights Reserved.