XMLを操作する方法、「DOM」と「SAX」
実のところ、XMLをプログラムで処理する場合、その考え方は言語に関係なく共通しています。DOM(Document Object Model)とSAX(Simple API for XML)という、XMLプログラミングの標準モデルが定義されており、たいがいの言語では、このモデルを用いたプログラミングが可能になっているのです。
それぞれの特徴を以下に簡単にまとめてみましょう。
ツリー構造を操作するDOM
XMLのデータは、タグの階層構造により表現することができます。この階層構造をツリー(木)に見立てたものがDocument Object Modelです。例えばリスト1に示すようなXML文書があったとしましょう。これをDOMで表現すると図1のような形になります。
<?xml version="1.0" encoding="UTF-8"?>
<profile>
<name>
<firstname>Ichiro</firstname>
<surname>Ohta</surname>
</name>
<gender>male</gender>
<job>Engineer</job>
</profile>
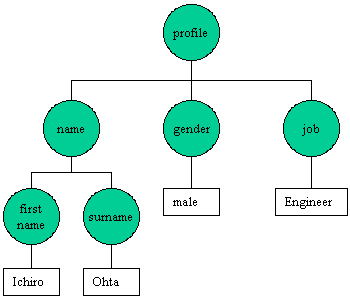
タグが木の節(「ノード」と呼びます)になっており、葉に当たる部分にはテキストデータが配置されています。このノードや葉を、1つ1つオブジェクトに見立てて操作するのがDOMの基本的な考え方です。
ノードや葉に当たるオブジェクトへのインターフェイスは、W3Cにより定義されています。このインターフェイスをJavaにバインドしたものがorg.w3c.domパッケージになります。
このインターフェイスの実装方式にはいろいろあります。XMLのデータを構文解析し、その解析の過程でメモリ上にDOMのオブジェクトツリーを構築するという実装が典型的なものといえるでしょう。
メモリ上のオブジェクトツリーをたどって処理するため、考え方としては非常に分かりやすいという利点があります。しかし、メモリ上にオブジェクトのツリーを構築する実装方式が多いため、実際の処理には大量のメモリを必要とする傾向があります(MonsterDOMと呼ばれる、2次記憶上にツリーを構築するものもあります。詳しくはhttp://www.ozone-db.org/を参照)。
DOMは当初、コアとなる基本機能のみを規定したDOM Level1という仕様としてリリースされました。現在では、XMLネームスペースなどさまざまな拡張を包含したDOM Level2という仕様としてリリースされています(一部の機能はまだ仕様策定中です)。本連載では、DOM Level 1の内容を中心に紹介していきます。
イベント通知型のSAX
DOMは処理中にメモリを消費するため、これをどうにかしたい、そういう要求に応える形で登場してきたのがSAXです。
SAXは、XMLのデータを構文解析する点はDOMと同じです。違うのは構文解析でタグを認識した場合の処理です。SAXの構文解析プログラム(パーサ)は、タグを認識した時点でオブジェクトを生成する代わりに、「タグが読み込まれました」というイベントを発生させます。このイベントのリスナーを実装することで、必要な処理、例えばタグの情報を読み取るといったようなことを記述するというのが、SAXの基本的な考え方になります。
DOMを生成せず、必要な情報をイベント通知の形で受け取ることができるため、必要以上にメモリを消費しないという利点があります。半面、イベントドリブンの処理形態になるため、ややもすると直感的に分かりにくくなるという傾向があります。お気付きのとおり、これらの特徴はまったくDOMの裏返しになっています。
最初のバージョンは1998年の5月にリリースされました。現在では、さまざまな機能拡張を施されたSAX2という新しいバージョンがリリースされています。
Copyright © ITmedia, Inc. All Rights Reserved.