キャッシュが性能劣化をもたらす“なぞ”を解く― データのキャッシュとコネクションプール ―:事例に学ぶWebシステム開発のワンポイント(2)
本連載では、現場でのエンジニアの経験から得られた、アプリケーション・サーバをベースとしたWebシステム開発における注意点やヒントについて解説する。巷のドキュメントではなかなか得られない貴重なノウハウが散りばめられている。読者の問題解決や今後システムを開発する際の参考として大いに活用していただきたい。(編集局)
今回のワンポイント
データベースアクセスを減少させるために、アクセスが頻発する参照データをキャッシュに入れた。しかし、期待とは異なり性能が落ちてしまった。メモリをキャッシュのために使いすぎる弊害と、コネクションプールの有効な使い方を学ぶ。
キャッシュを使っているのにパフォーマンスが落ちる
あるシステムでは、データベースアクセスを少なくしようと、参照するデータをアプリケーション・サーバの起動時にデータベースから取得しメモリ上に保持していた。これは、別に悪い考え方ではない。データベースへのアクセス回数の削減は、性能向上につながるからである。しかし、このシステムではそうならなかった。ガーベジコレクション(GC)が頻発し、OutOfMemoryErrorまで発生してしまった。性能向上どころか、むしろ問題を増やしてしまったのである。アプリケーションでデータをキャッシュする場合、メモリ容量の見積もりが重要であることを痛感したケースである。
Webシステム開発において考えることは数多くあるが、データベースは依然として最も重要な要素の1つである。今回は、データベースの利用に当たっての注意点を紹介したい。
データキャッシュの落とし穴
(1)そもそもキャッシュする必要はあるのか
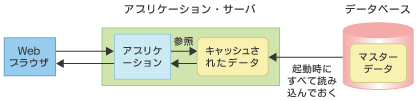
データベースアクセスを嫌う人は多い。そんな人は次のように考える。せっかくデータベースから読み込んできたデータなのだから、2回目以降はデータベースにアクセスしなくてもいいように変数に保持しておこう。いっそのこと、サーバ起動時に参照データは全部読み込んで、メモリに置いてしまおう。確かに、ディスクから読むよりメモリから読み込んだ方が速そうだ。
しかし、ちょっと待ってほしい。大切なのは、キャッシュを使用することで、データベースに対する負荷をどの程度軽減できるかということではないだろうか。このため、参照される頻度が重要になる。あまり参照されないデータをアプリケーションでキャッシュしても、無駄なだけであるからである。参照頻度の高い(加えてあまり更新されない)データをキャッシュすべきであろう。
(2)メモリは有限、JVMのヒープサイズはもっと有限
キャッシュすることが、むしろ「有害」な場合もある。冒頭で述べたシステムでは、参照が主となるマスターデータを、アプリケーション・サーバの起動時にすべてデータベースから取得してメモリ上に保持していた。当初はそれでよかったものの、マスターデータの数が増えて、とうとうOutOfMemoryErrorが発生するようになってしまった。
急きょメモリを増設し、Java仮想マシン(JVM)で指定しているヒープサイズを拡大し、何とか問題を解決したものの、ヒープサイズの限界が思ったよりも小さかったことはショックであった。メモリも安くなり、1Gbytesや2GBytesのメモリなど、むしろ小さいといった昨今であるが、例えばHPのJVM 1.3.0ではヒープサイズに指定できるサイズは1.8Gbytesであった。メモリをたくさん積めば解決するという問題ではないのである。メモリの使いすぎには注意したい。
(3)キャッシュの更新
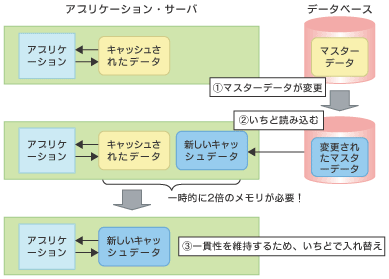
併せて注意しなくてはならないのがキャッシュの更新である。例に挙げたシステムは、24時間稼働のためサーバ再起動のチャンスがめったにない。しかし、マスターデータの更新が必要になる場合があるため、一貫性を損なわないように、現在のキャッシュデータのほかに新しいキャッシュデータを用意し、ある契機で入れ替えるようにしていた。そうしたところ、一時的に2倍のメモリが必要となり、さらにメモリ不足に拍車をかけることになったのである。キャッシュを行うかどうかは、更新のメカニズムまで含めて考えるべきであった。
コネクションプールをうまく使うには
以上、データキャッシュの落とし穴について述べたが、これらはどのアプリケーション・サーバでも起きる問題である。一方、データベースのコネクションプールは、アプリケーション・サーバが持つ当たり前の機能としてすっかり定着したが、うまく使うにはアプリケーション・サーバごとのノウハウが必要となる。ここでは、WebLogic Server 5.1を対象に、コネクションプール利用時の注意点を説明したい。
(1) 初期サイズと最大サイズは同じにせよ
コネクションプールで作成するコネクションの数は、初期サイズと最大サイズ(initialCapacity、maxCapacity)を設定できる。初期サイズ分のコネクションを使い尽くして足らなくなった場合は、最大サイズまでコネクションを拡大するという発想であるが、通常、運用環境では動的に拡張するメリットはない。むしろ安定性を重視して、初期サイズと最大サイズを同数にし、動的にコネクション数を変化させない方がよい。
(2) コネクション数とスレッド数
しばしば悩むのが、コネクション数をいくつにするかである。当然ながら多ければ多いほどいいというものでもない。WebLogic Serverの実行スレッド数(ThreadCount)と同じ値にするのが基本であるが、アプリケーションの処理内容に依存する。データベースを使用しない処理が多い場合は、スレッド数をやや多めにした方がよいケースが多い。
(3) リフレッシュとコネクションのテスト
一定の間隔でコネクションプール中の未使用コネクションについて接続をテストするのが、リフレッシュ(refreshTestMinutes)である。無効なコネクションがあれば破棄し、コネクションを再作成する。システム稼働時の負荷を考慮し、あまり実行間隔を小さくしない方がよい。
一方、プールからコネクションを取得/解放する際に、有効なコネクションかどうかチェックするのがコネクションのテスト(testConnsOnReserve、testConnsOnRelease)である。コネクション利用のたびにチェックするため確実といえば確実であるが、若干ながら応答時間に遅延が生じることに注意する必要がある。
(4) データベースクラスタとの組み合わせには、コネクションプールの再作成が必要
多くのWebシステムでは、アプリケーション・サーバがクラスタ化されているだけでなく、データベース・サーバもクラスタ化されている場合が多い。現用系のデータベース・サーバに障害が発生すると、クラスタソフトは待機系のデータベース・サーバにフェイルオーバーし処理を継続させようとする。このとき、アプリケーション・サーバはコネクションプールの再作成を行わなければならない。
コネクションプールの再作成には、次の4つの方法がある。
- リフレッシュ機能を用いて、リフレッシュ時に再作成する
- コネクションテスト機能を用いて、コネクションの取得要求時に再作成する
- リセットコマンドを用いて、全コネクションを再作成する
- WebLogic Serverを再起動させる
ただし、リフレッシュによる方法では、リフレッシュを実行する時間間隔だけ待たされることになる。また、コネクションテストでは、通常時の応答時間の遅延が気になるところである。4番目のWebLogic Server再起動は、確かにコネクションプールは再作成されるものの、セッション情報が失われるのが致命的である。そのため、3番目のリセットコマンドを用いる方法をお勧めする。データベース・サーバのフェイルオーバーが完了した時点で、リセットコマンドを用いてコネクションプールを再作成する。これにより、フェイルオーバー後、迅速にサービスを再開することが可能になる。
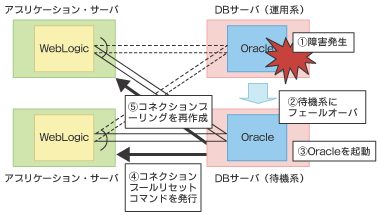
ただ、このコネクションプールのリセットについては、WebLogic Serverのサービスパックによっては機能しないケースがある。この場合はリセット以外の手段を検討する必要がある。十分な試験を実施することが大切である。
著者プロフィール
高橋 宏明(たかはし ひろあき)
現在、株式会社NTTデータ COEシステム本部に所属。 技術支援グループとして、J2EEをベースにしたWebシステム開発プロジェクトを対象に、技術サポートを行っている。特に、性能・信頼性といった方式技術を中心に活動中。
- ファイルアップロード/ダウンロードに潜むわな− 大容量、高負荷時の注意点 −
- ブラウザキャッシュでパフォーマンス向上―負荷分散装置の落とし穴に注意−
- JDBC接続を高速化する− PreparedStatementキャッシュの威力−
- レスポンスキャッシュでパフォーマンス向上―アプリケーションを変更せず性能UPする魔法のつえ―
- メモリは足りているのに“OutOfMemory”
- 文字化け“???”の法則とその防止策
- 低負荷なのにCPU使用率が100%?
- APサーバからの応答がなくなった、なぜ?―GCをチューニングしよう―
- サービス中にアプリケーションを入れ替える―クラスタ機能を活用しよう―
- マルチスレッドのいたずらに注意―あなたのJSPやServletは大丈夫?―
- クラスタは何台までOK?―性能から見たWebLogicクラスタの適正台数―
- キャッシュが性能劣化をもたらす“なぞ”を解く― データのキャッシュとコネクションプール ―
- クラスタ化すると遅くなる?― HttpSessionへの積み過ぎに注意 ―
Copyright © ITmedia, Inc. All Rights Reserved.