ファイルアップロード/ダウンロードに潜むわな− 大容量、高負荷時の注意点 −:事例に学ぶWebシステム開発のワンポイント(13)
本連載では、現場でのエンジニアの経験から得られた、アプリケーション・サーバをベースとしたWebシステム開発における注意点やヒントについて解説する。巷のドキュメントではなかなか得られない貴重なノウハウが散りばめられている。読者の問題解決や今後システムを開発する際の参考として大いに活用していただきたい。(編集局)
今回のワンポイント
Webシステムにファイルアップロードやダウンロード処理を取り入れているケースは多い。また、世の中にも、いくつかのサンプルソースや参考文献が出回っており、開発も行いやすいといえる。しかし、利用する場合には、アプリケーションサーバ全体の性能劣化やタイムアウトといったいくつかの問題を考慮することが重要だ。実際に発生したトラブル事例を交え、その問題点や注意事項について解説する。
ファイルアップロード/ダウンロード処理に潜むわなとは?
ファイルアップロードやダウンロードといっても、小さなファイルを扱っている場合は問題になる可能性は低い。しかし巨大なファイルを扱う場合や、通信回線の品質が悪く、ファイルアップロードやダウンロードにかかる時間が長い場合には、注意が必要である。
このような場合、以下の問題が発生する可能性がある。
- サーバリソースの問題
- 無応答問題
- タイムアウト問題
以降で、それぞれについて事例を交え説明する。
サーバリソースには注意せよ
簡易なメールシステムをWebアプリケーションとして構築し、ファイルのアップロードやダウンロードを行っていた。しかしテスト段階で、1Gbytesのファイルをアップロードしてみたところ、java.lang.OutOfMemoryErrorが発生してしまった。
さらにこのケースでは、予想もしない長大なファイルが次々とアップロードされた場合、サーバ側のリソースを圧迫してしまうことになり、甚大な被害が想定されるという、アップロードの本質的な問題も抱えていた。
■問題発生の理由は?
OutOfMemoryErrorの原因を突き止めるため、アップロード処理のソースを調査した。すると、クライアントからの入力をjavax.servlet.ServletInputStreamから受け取り、java.io.ByteArrayOutputStreamを使ってI/O処理していたことが判明した。ByteArrayOutputStreamは、通常のファイルI/Oを行うようなインターフェイスと同様に利用できるが、その際にメモリ上にすべてのデータを保持しておく仕組みを提供する点で異なる。余分なファイルI/Oを避けるためにと、メモリ上に一時的にすべてのアップロードデータを格納してから、ファイルとして吐き出していたことになる。このため、アプリケーションサーバ起動時のJavaのヒープサイズ(このケースでは640Mbytesを指定)を超えてしまい、OutOfMemoryErrorとなったのである。これは、ByteArrayOutputStreamを使用した例であるが、このように一度メモリに保持する方式を採用しているケースも意外と多い。
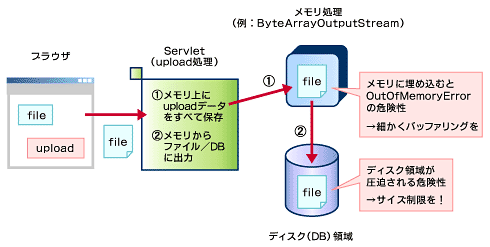 図1 問題となった事例
図1 問題となった事例■対策と注意事項
(1)メモリは無限ではない
ポイントは、ストリーム処理を行い、メモリに保持するデータを小さくすることである。このケースでは、ByteArrayOutputStreamではなく、java.io.FileOutputStreamを使用する対策を取った。FileOutputStreamは、基本的にバッファ単位でファイルとして吐き出すことができる。ただし、バッファリングする単位をあまりにも大きく取ってしまっては意味がない。また、バッファをむやみに大きくするとGCなどの性能にも影響を与えることは、本連載の中でも紹介した。java.io.BufferedOutputStreamを使ってFileOutputStreamをラッピングしても結果は同様である(第7回「低負荷なのにCPU使用率が100%?」参照)。
しかし、このケースのように単純にFileOutputStreamを使えない場合もあるだろう。例えば、ファイルに出力するのではなく、データベースに格納する場合である。この場合、いったんファイルに吐き出してから、後でデータベースに挿入する方法や、JDBCで提供されるストリームであるBlobやClobに直接吐き出す方法などがある。場合によりけりだが、最適な方法を考える必要がある。
(2)サイズ制限も考慮すべし
長大ファイルのアップロードに関しては、悪意がある場合はまさにWebサーバへの攻撃ともなる。この問題に対処するために、このケースではアプリケーションレベルでサイズ制限をする対策を講じた。
これには、HTTPヘッダに含まれるContent-Lengthを用いて送信時のデータ長を取得し制限する方法がある(Content-Lengthはファイルサイズを示すものではないので注意)。また、ServletInputStreamからの入力処理時に、データサイズをカウントしていくという方法もあるだろう。ポイントは、いずれの場合も制限を超えた時点でメモリに保持せず、データを吐き捨てることである。
無応答問題に対処する
アップロードやダウンロードにより無応答問題が発生する可能性がある。例えば、処理に時間がかかるような、長大なファイルを数百人が一斉にダウンロード(アップロード)した場合を想像すれば分かる。このような場合、ダウンロードしている端末が遅いのは仕方ないが、新しくトップページ(単なる軽いHTML)を開こうとしても、まったく応答が返ってこなくなる。
■問題発生の理由は?
これは、アプリケーションサーバの構造的な問題に依存する。通常のアプリケーションサーバでは、1つのリクエストは、1つのスレッドによって実行される。よって、上記のように長大なファイルダウンロードのアクセスが集中した場合、その処理だけでアプリケーションサーバの実行スレッドがすべて占有されてしまう。しかし、長大なデータであるため処理に時間がかかり、新しいリクエストを受け付けるための空きスレッドがなかなかできなくなる。空きスレッドができたとしても、キューイングされたリクエストが再びダウンロード処理に使われてしまえば、トップページのような軽いページを表示するだけでも、そう簡単には処理をしてくれない。つまり、これが無応答状態である。
この問題の本質は、処理の占有時間が長いことである。よって、同じようなことは、回線品質が悪い場合や、ダウンロードやアップロード以外のケースでも遭遇することになるであろう。しかし、長大なファイルを扱うダウンロードやアップロードで発生しやすいのは間違いない。
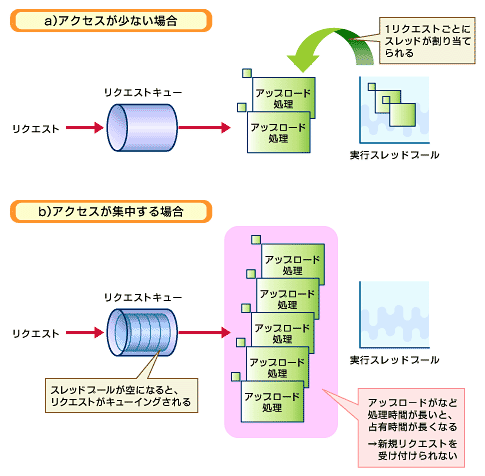 図2 問題発生の原因
図2 問題発生の原因■対策と注意事項
(1)スレッドを増やすのはよいのか?
単純に思いつくのは、実行スレッドを増やすという方法がある。確かにスレッドを増やすことにより、より多くの処理を同時にこなすことができる。しかし、増やし過ぎれば当然サーバへの負担が多くなり、結果としてサーバ全体がスローダウンすることになりかねない。よって、負荷試験を行い、ある程度の数値まで増やすことはよいと考える。
(2)コネクション数を制限しよう
FTPサーバなどでは、一定以上の負荷が掛からないよう、コネクション数を制限していることがある。これと同じように、ダウンロードなど問題となる処理に対する要求数を制限すればよい。
アプリケーションレベルでの実現方法では、実装方法に工夫が必要である。特定のURLへのリクエストをフィルタリングするようなサーブレット(JSP/Servlet Filter)を作成することで実現可能である。具体的には、コネクション数をServletコンテキストなどの領域に保持しておき、リクエストが来た都度コネクション数の制限チェック、コネクション数の更新を行えばよい。なお制限値を超えた場合は、即座にアクセス拒否のページを出力する。
BEA社のWebLogic Serverのように、アプリケーションサーバ製品の中には、Servlet/JSPごとに実行スレッド群を分ける機能がある。この機能を用い、対象となるServletだけ別のスレッドグループとして登録し、現実的なスレッド数を割り当てる。これにより、ほかの処理に影響を与えることなく、特定の処理だけスレッドを制限することができる。
また負荷分散装置によっては、URLごとにコネクション数を制限し、一定のコネクション数を超えた場合、自動的に別のサーバ/ページ(Sorryサーバ)に振ることができる機能も備える。方式はいくつか考えられるが、システム構成や要件などに合わせ、実現するとよい。
(3)ファイルの分割アップロード/ダウンロード
ファイル分割により解決したケースもある。これは、次のような実現方式である(ダウンロードの例)。
- クライアント側は、1リクエストを複数のリクエストに分割
実現方法には、HTTPのRangeヘッダを用いるとよい。開始バイトや、要求バイト数を細かく制限できるため、1つのファイルであっても分割して取得することができる。 - サーバ側は、ファイルの一部を取り出しクライアント側に送信
使用しているダウンロードServlet(ファイルServlet)がRangeヘッダに対応していれば、そのまま使用できる。また、独自に作成したダウンロードServletでもRangeヘッダを解釈するようにすれば実現は難しくない。 - クライアント側でダウンロードした分割ファイルを結合
以上の方式では、リクエストごとに処理するサイズが小さくなるため、占有時間が短くなる。つまり、スレッドの解放が行われる頻度が上がることによって、無応答状態が改善することになる。
しかし、ファイル分割の制御は、クライアント側はアプレットやブラウザのプラグイン、独自アプリケーションで実現される必要がある。要件によっては簡単には使えないだろうが、1つの方法として覚えておくとよい。
(4)アプリケーションサーバのアーキテクチャを変える!?
余談であるが、アプリケーションサーバの方式についても考察してみよう。一般のOSには、selectやpollというシステムコールがあり、1スレッド(1プロセス)内で処理を多重化(マルチプレキシング)して実行することができる(JavaではJDK 1.4から提供されるNIOパッケージで実現可能となった)。つまり、1つのスレッドで複数のダウンロード処理が可能となる。しかし、select/pollというシステムコールは、I/O処理(ファイルディスクリプタが必要)が前提であり、ダウンロードやアップロードのような処理を実行するにはよいが、ビジネスロジックなどの処理ではそうはいかない。WebLogic ServerのnativeI/Oというモジュールは、リクエストのselect/pollとヘッダ部の解析をネイティブコードで実装し、少数のスレッドで複数のリクエストの受け付けができるよう多重化されているが、ダウンロード処理自体の多重化はされない。
また、1つの処理でも小さな処理単位に分割して、スレッドを切り替えていく方式も考えられる。しかし、処理を細かく分割していくには何らかの制御が必要となり、コンテナ側で管理するのは非常に難しい。
つまり、方式はいくつか考えられるが、アプリケーションサーバ=汎用的なコンテナとしては実装が難しいのだろう。
タイムアウトも忘れるべからず
処理時間が長い場合は、タイムアウトも問題となるケースがある。
このケースでは、javax.servlet.http.HttpSessionBindingListenerを用い、セッション終了時にログインデータなどを掃除するという処理を実装していた。通常のファイルでは問題なかったが、テスト段階で大きなファイルをダウンロードしたところ、なんと処理中にセッションタイムアウト処理が呼ばれるという事象が起こった。ここでの問題の本質は、セッションタイムアウト処理が呼ばれたことでなく、セッションがタイムアウトしたことである。
■問題発生の理由は?
直接原因となったのは、セッションタイムアウトの設定である。このケースでは、 セッションタイムアウトを20分として設定していたが、ダウンロード時間に20分以上要していたのである。ポイントはセッションタイムアウトのタイマーの契機である。セッションタイマーは、一般にセッションに対してのアクセスが行われたときに発動される(このケースでは、「HttpServletRequest#getSession()」メソッドを発行したタイミング)。Servlet側の処理ではログインチェックなどを行うため、最初にセッションから必要な情報を取得し、その後ダウンロード自体の処理を行っていた。よって、ダウンロード処理がセッションタイムアウトの20分をオーバーしたため、タイムアウト処理が実行されたのである。
無応答問題と同じように、本質的には処理時間が長いことが問題である。よって同じようなことは、回線品質が悪い場合や、ダウンロードやアップロード以外のケースでも遭遇することになるだろう。
■対策と注意事項
このケースでは、セッションタイムアウトを長くすることで対策を行った。特に、ダウンロード処理ということもあり、ファイルサイズがある程度特定できたため、負荷を予測して現実的なセッションタイムアウトを導き出し設定した。
しかし、この方法はアップロードなどでは使用できない。よって、メモリ問題で示したファイルサイズの制限対策や、無応答問題の対策で示した分割ファイル送信が有効である。
著者プロフィール
田中秀彦(たなか ひでひこ)
現在、株式会社NTTデータ ビジネス開発事業本部に所属。 技術支援グループとして、J2EEをベースにしたWebシステム開発プロジェクトを対象に、技術サポートを行っている。特に、性能・信頼性といった方式技術を中心に活動中。
- ファイルアップロード/ダウンロードに潜むわな− 大容量、高負荷時の注意点 −
- ブラウザキャッシュでパフォーマンス向上―負荷分散装置の落とし穴に注意−
- JDBC接続を高速化する− PreparedStatementキャッシュの威力−
- レスポンスキャッシュでパフォーマンス向上―アプリケーションを変更せず性能UPする魔法のつえ―
- メモリは足りているのに“OutOfMemory”
- 文字化け“???”の法則とその防止策
- 低負荷なのにCPU使用率が100%?
- APサーバからの応答がなくなった、なぜ?―GCをチューニングしよう―
- サービス中にアプリケーションを入れ替える―クラスタ機能を活用しよう―
- マルチスレッドのいたずらに注意―あなたのJSPやServletは大丈夫?―
- クラスタは何台までOK?―性能から見たWebLogicクラスタの適正台数―
- キャッシュが性能劣化をもたらす“なぞ”を解く― データのキャッシュとコネクションプール ―
- クラスタ化すると遅くなる?― HttpSessionへの積み過ぎに注意 ―
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。