ジャーナリングファイルシステムが保護する「情報」:Linuxファイルシステム技術解説(3)(1/2 ページ)
信頼性が高いとされるジャーナリングファイルシステムだが、ジャーナルによって何が保護されるのかを理解していないと、とんでもない落とし穴にはまってしまう。今回は、ジャーナリングファイルシステムの総論とそのほかの各種技術について解説する。(編集局)
ジャーナリングファイルシステム
Linuxではカーネル2.4以降、ext3、ReiserFS、JFS、XFSなど複数の「ジャーナリングファイルシステム」がカーネルに追加された。Linuxでジャーナリングファイルシステムが必要とされている背景には、Linuxがエンタープライズを志向するに伴ない、大容量記憶装置の利用によるデータの安全性、起動時のfsck時間短縮などの要求が高くなってきたことが挙げられる。
ジャーナリングファイルシステムとは?
「ジャーナリング」は、ジャーナル(またはログ)と呼ばれるデータを定期的に記録する技術で、もともとはデータベースで用いられてきた。ジャーナリングファイルシステムはこの技術を応用したもので、ファイルシステムの更新内容をジャーナルログに記録する。システム障害などが生じた際に、ログに記録された内容を確認するだけでよいので起動が速くなり、かつその情報を基にした復旧が可能となる。
データベースで用いられるジャーナリングの目的がデータの保全であるのに対して、ジャーナリングファイルシステムの目的はデータそのものではなく、ファイルシステム全体を保護することにある。ファイルシステムの保護のためには、ファイルシステムを構成・管理する情報である「メタ・データ」(注)の整合性が必要である。つまり、ジャーナリングファイルシステムにとっては、メタ・データを適切に保持し、更新の処理を行うことが主な目的となる。
注:データとメタ・データ
データ:ファイルに実際に書き込まれているデータ
メタ・データ:スーパーブロック、グループディスクリプタ、iノードテーブルやそこからリンクされているデータなどの管理情報
ジャーナリングファイルシステムは、次のような処理を行う。
- ファイルシステムに対する書き込み
- iノード、データブロック、スーパーブロックの変更
- 変更がディスクに反映される(書き込まれる)
この一連の流れを図1に示す。
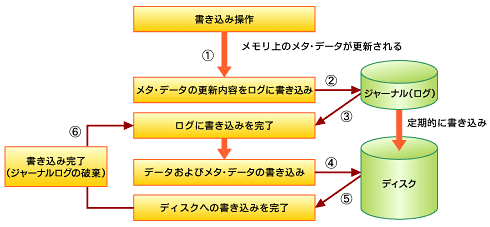
書き込み操作が行われると、メモリ上のメタ・データが変更される(1)。この変更はジャーナルログに書き込まれる(2)。完全に書き込まれたことが確認できたら(3)、次に実際のデータとメタ・データがディスクに書き込まれる(4)。ディスクと同期が取れたことを確認したら、ジャーナルログの部分は新しいログの書き込みのために解放される(5)。
システムにクラッシュなどの問題が生じた場合、ジャーナリングファイルシステムは「更新記録」であるジャーナルファイルを参照し、整合性が取れないファイルを破棄または復旧する。これにより、データの一貫性が保証される。
従来のext2などのファイルシステムでは、fsckなどにより再起動時にディスク上のすべてのメタ・データを1つずつ比較・確認することで、非一貫性を修復する作業を行っていた。
ジャーナリングファイルシステムでは、ジャーナルファイルの「変更記録」のみを確認すればよいので、数秒でファイルシステムの整合性を確認できるようになる。これにより、起動時のfsck(file system check)の高速化が実現し、数百Gbytesのファイルシステムのメタ・データでも、ほぼ瞬間的に整合性が取れた状態に復帰できるようになった。
トランザクション管理
メタ・データの整合性を取るには、「トランザクション」管理という考え方が使われる。トランザクションは一般に、データベース内のデータを更新するための一連の不可分な手続きを指す。
例えば、預金の際の「1金額を入力する」「2入力した金額を預金口座の金額に追加する」といった作業は、1つのトランザクションとして見なされる。トランザクションは不可分であり、3が失敗した場合は4もキャンセルしなくてはならない。つまり、すべて実行されるか、まったく実行されないかの二者択一で作業を行う必要がある。この処理を「アトミック処理」(注)と呼ぶ。
注:不可分な操作のこと。銀行業務の例のように、トランザクションは常にアトミック処理が保証される必要がある。ファイルシステムの場合は、「iノードの追加や削除」といった操作が対象となる。Linuxではこのアトミック処理をインラインアセンブラで展開し、それを処理する間はほかの処理が割り込まないようにロックを掛けて防いでいる。
同様に、ジャーナリングファイルシステムはログに書き出すための不可分な一連の作業をトランザクションとして管理している。
データベースでのトランザクション管理
データベースにおけるトランザクション処理は、銀行口座や基幹業務など幅広い分野で、処理に矛盾が存在してはならない場合に用いられる。データベースはデータの更新に対して周期的にチェックポイント(監視記録)を設け、その時点でのログとデータ内容を保存する。トランザクションの途中で障害が生じた場合は、最近のチェックポイントに記録された情報を基にログとデータの整合性を確認し、ロールフォワード/ロールバック/クリーンアップなどの方法を選択する。
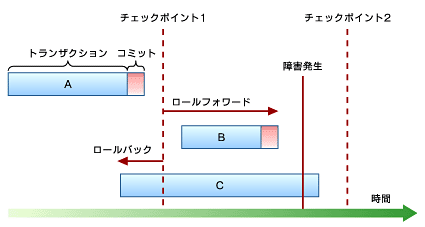
A、B、Cは、それぞれトランザクションを示している。終端のマークは、コミット処理(注)が完了していることを示している。つまり、AとBのトランザクションは障害発生時にすでにコミットが完了している。
注:データベースでは、書き込みデータをいったんバッファに保存した後でディスクに書き込む。このディスクへの書き込み処理(命令)を「コミット」という。ファイルシステムでは、ディスクへの書き込みは「フラッシュ」と呼ばれ、非同期に行われる。ジャーナルのコミット処理は、トランザクションのメタ・データがディスクに書き込まれた時点で完了する。
チェックポイント1における処理を見ると、 Aはチェックポイント時点でコミットが終了しているので、障害発生時はチェックポイントの記録およびジャーナルログの記録のいずれも問題ない。Bはチェックポイントに記録はないが、コミット処理のジャーナルログが残っているので、チェックポイントからログに記述された手順を時間順に追っていけば障害回復できる(ロールフォワード)。
Cの場合、障害発生時にコミットされていないので、ログには残っていない。しかし、チェックポイント1時点のログが残っているので、ログの時間軸を逆にたどってトランザクションCが実行される前の状態にいったん戻す(ロールバック)。その後、Cを再実行することでトランザクションを再現する。
クリーンアップは、チェックポイント以降にコミットされたログ以外の情報を破棄する。
ジャーナリングファイルシステムでの処理
ジャーナリングファイルシステムでは、メタ・データの更新までの作業がトランザクションに当たり、ディスクへのフラッシュがコミット処理に相当すると考えれば理解しやすい。
データベースと同様に、ロギングとチェックポイントの設定などを行うことで、一貫性が失われた状態をできるだけ修復する方法が取られる。
- 更新ログ領域のみを確認することで、リカバリ時に確認するディスク範囲を少なくする
- ジャーナリングのログ書き出しとは別に、チェックポイント時点における整合性が取れた状態を残し、その状態まで戻すことで修復する
- ログに記録された情報とチェックポイント以降に生じた操作を最大限回復する
これらの操作によって、一貫性を最大限保ち、かつ起動時間の短縮を実現している。
ジャーナリングファイルシステムの信頼性と性能
ジャーナリングファイルシステムの設計で得られる結果から、「信頼性」や「性能」について大まかに次のようなことがいえるだろう。
- 一貫性の保証はデータレベルではなく、ファイルシステムレベルで行われる
- データがすべて安全であると思ってはいけない
- ログの確認だけで済むので、起動時間はext2よりは速い
- ログを書く時間が二重に掛かるため、性能はやや劣る
- ファイルシステム(ext3、JFS、XFSなど)の設計によっては、信頼性、性能の強弱が異なるため一概にYES/NOでは語れない
●データの保全
ファイルシステムにおいては、データ自体よりもメタ・データ全体の構成が重要である。つまり、データ自体は保護の対象となっていないため、ファイルの書き込み中にシステムがダウンした場合、ファイルの中身が保証されるとは限らないのである。
さらに、現在はハードディスクの高速化のためのバッファも増えており、バッファ上のデータが書き込み前に消失することもあり得るため、完全にデータを保証するのはより難しくなっている。データを完全に保護するのであれば、トランザクションを完全に管理するためのデータベースソフトウェアを使用するか、システムの二重化といった方法を重ねて検討することが望ましい。
●性能面での改善
ジャーナリング機能は、ジャーナルファイルへの記録という作業が加わるので、通常のメタ・データの更新に比べてディスクアクセスは確実に増える。そのため、性能が低下することは避けられない。しかし、大抵のファイルシステムは大幅な性能低下が生じないように、ジャーナリングデータの更新とメタ・データの書き込みを非同期に行うなどの方法が取られている。具体的な性能については、連載後半で予定しているベンチマーク結果などで確認いただきたい。
●ファイルシステムごとの実装の違い
ここまでジャーナリングファイルシステムの一般的な特徴について説明したが、実際の性能やメタ・データの保存方法などは、ファイルシステムごとに異なる。例えば、ext3ではジャーナルファイルに更新記録を保存するのみで、それによってデータを制御する機能は持っていない。JFSなどは、書き込み時にディスクに二重にデータを保存する方法が取られている。具体的な方法は次回に述べるが、ファイルシステムごとにジャーナリング機能の実装内容が異なるため、信頼性や性能にも違いが生じる。
ログ構造ファイルシステム
Linuxでは何かとジャーナリングファイルシステムが脚光を浴びているが、信頼性や性能向上のための仕組みとしては、ジャーナリング以外にもさまざまな試みが行われている。主なものとしては、I/O命令をまとめてクラスタ化することで性能向上を目指す「クラスタリング」や、BSDで試みられている「Soft-Update」、データをログに追記する「ログ構造ファイルシステム」などがある。このうち、ジャーナリングと並んでファイルシステムの一貫性を保つための試みである「ログ構造ファイルシステム」を紹介する。
Log-Structured File Systemの仕組み
ジャーナリングファイルシステムは、一般的にメタ・データの更新を保存する。これに対して、LFS(Log-Structured File System)と呼ばれるログ構造ファイルシステムは、データとiノードの両方をトラッキングして変更、追加、削除など、すべての操作をファイルシステムのログ部分に記録する。
LFSには、Sprite-LFS、BSD-LFSなどがある。Linuxでは、このようなログ構造ファイルシステムとしてLFSプロジェクトやLinLogFS(以前はdtfs)などがある。
ロギングファイルシステムやログ構造ファイルシステムでは、ディスクの同じエリアにデータを追加することで、性能を著しく改善させている(図3)。同じエリアにデータを置くことでファイルシステムが起動時に変更ブロックを探す必要がなく、一度に参照できる。
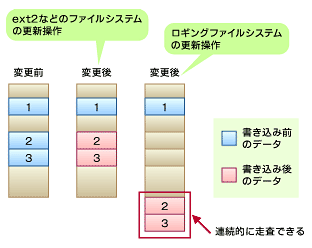
ファイルシステム構造が変更した内容はすべてログにあるため、ファイルシステムの一貫性を確認するために全ディスクを走査する必要はなくなる。例えば、マウント時にコミットの記録があって完了の記録がないデータについては、そのブロックをチェックして必要であれば修正するだけでよい。
また、LFSは書き込みの時系列に従ってデータを隣接して配置する。こうすることで、コミット時のI/O命令をまとめて行うため効率が良くなり、書き込みのスピードとリカバリ時間が大幅に改善されるなどのメリットがあるとされる。
しかし、ファイルの作成や削除が多いといった、メタ・データ操作が主な環境では比較的効果が発揮されるが、データの更新が多い場合は効果的なデータブロックの検索機構が必要である。またログ領域を逐次的に書き込んでいくため、ログ領域を空ける操作をしなくてはならない。そのためのガベージコレクションが必要であるが、いまのところその実装が完全でないなどの理由で、実用上のメリットはいまひとつ証明されていない。
とはいえ、いつかスーパーアーキテクトが改善点を示すことで、カーネルに取り込まれることがあるかもしれない。
Copyright © ITmedia, Inc. All Rights Reserved.