ジャーナリングファイルシステムが保護する「情報」:Linuxファイルシステム技術解説(3)(2/2 ページ)
信頼性が高いとされるジャーナリングファイルシステムだが、ジャーナルによって何が保護されるのかを理解していないと、とんでもない落とし穴にはまってしまう。今回は、ジャーナリングファイルシステムの総論とそのほかの各種技術について解説する。(編集局)
ファイルシステムのさらなる効率化技術
エクステント(Extent)方式
エクステントは、「ブロックアルゴリズム」の間接参照に対してより効率的なデータのアドレッシングを提供する。旧Silicon Graphics(現SGI)の初期のファイルシステムに実装され、その後XFS(Extended File System)としてIRIXに取り込まれた。現在では、データ表現のスケーラビリティを高める方法としてJFSなどにも取り入れられているほか、データベースエンジンによっても使用されている。
エクステントは連続した論理セットで、「開始ブロック」「サイズ」「オフセット」を用いてデータを管理する。論理セットの内容を表1に示す。
| 開始ブロック | エクステントが開始されるブロックのアドレス |
|---|---|
| サイズ | ブロックの容量 |
| オフセット | ファイル中でエクステントが占める最初のbyte数 |
| 表1 エクステントの論理セット | |
図4は、エクステントの論理セットが実際にディスクブロックのアドレスをどのように保持しているのかを示している。最初のエクステントの論理セットは「15、30、1」、2番目は「200、210、16」の値を保持している。
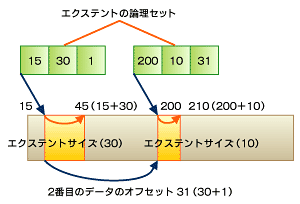
| 開始ブロックアドレス | 15 |
|---|---|
| エクステントサイズ | 30bytes(15-45) |
| オフセット | 最初なので1 |
| 最初のブロック | |
| 開始ブロックアドレス | 200 |
|---|---|
| エクステントサイズ | 10bytes(200-210) |
| オフセット | 最初のブロック(15)から数えて31番目 |
| 2番目のブロック | |
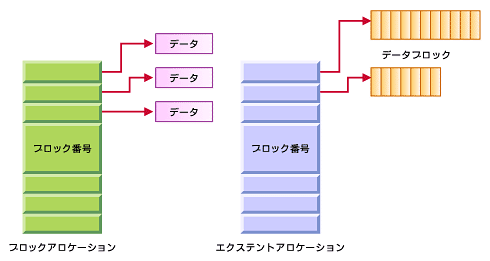
エクステント方式とブロックアルゴリズムには、主に次のような相違点がある。
- データ管理領域の節約
エクステントでは、ファイルサイズが大きくなっても基本的に3つの値でブロックのアドレスを特定できる。これは、ブロックアルゴリズムがファイルサイズの増加に伴なってブロックの参照データが増大するのとは対照的である。このように、エクステントではデータの管理領域を大幅に減らせることが分かる。エクステントのアドレス構成はB+-Treeをベースとしており、3つの値を持つブロックはiノード内に置かれ、ファイルのオフセット値によってキー値が作成される。 - メタ・データの領域節約
ファイルのメタ・データ(データ自体ではなく、データの管理情報)の書き込みはファイルが最初に作成されたときのみで、追加的なメタ・データは不要である。
例えば、エクステントでは図4にあるように最初のアロケーション(15)を行った後、それに続く読み書きも最初に割り当てられたエクステントブロック内で連続的に行われる。追加的なメタ・データの書き込みは、次のエクステント(200)の割り当てまで必要ない。ファイルサイズが増えた場合は、エクステント内の値を変更するだけなので、新たな領域も不要である。
ブロックアルゴリズムの場合、ブロックのアドレス番号は各データブロックについて必要である。その結果、ファイルが大きくなると1つのファイルに対して大量のメタ・データを必要とする。 - I/Oの効率化
エクステントでは3つの値だけでよいため、書き込み時のブロックをグループ化してより大きく確保することが可能となる。データをグループ化することで、複数にわたる二次記憶へのI/O処理を1つにまとめて効率化できるといったメリットもある。
図5は、アドレスの指定方法の違いを示している。エクステントベースの方が少ないアドレッシングで大きなデータを扱えることが分かる。
そのほかにも、エクステント内のブロックが連続していることにより、次のようなメリットがある。
- 動作時間の短縮
走査(スキャン)時間の低減につながり、記憶媒体の動作が少なくて済む。 - 外部フラグメンテーションの削減
より多くのブロックを連続して保持できるため、データ読み出し時のフラグメンテーションを軽減できる。 - 大量の連続した空き空間を組織化
効率的なディスクの使用、パフォーマンスの促進。 - マルチセクタ転送
ハードディスクのI/O処理の効率化。
スパースファイルサポート(Sparse files support)
スパース(Sparse)ファイルとは、データとデータの間に書き込みのないスペースが存在するファイルである。データベースなど、ランダムアクセスが発生するアプリケーションは、データ領域を論理領域として確保する場合があるため、こうしたファイルを生成する。ファイルシステムによっては、空白のブロック部分をディスクに保存せず、データが存在する部分のみを書き込むなどの方法で、こうしたファイルを効率的に管理している。
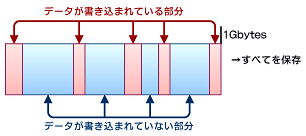

エクステントは、実際のデータ部分を「サイズ」で指定できるため、スパースファイルを効率的に管理できる。ファイルシステムは「開始位置」から「サイズ分」をディスクに保存すればよいので、それ以外のスペースをディスクに保存する必要はない。
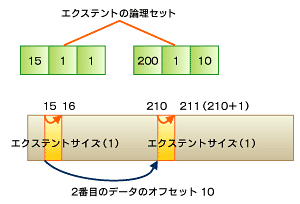
図8は、開始アドレスが15、サイズが1なので、15から16までが最初のデータブロックとなる。最初のデータなので、オフセットは1である。
2番目に確保されたデータブロックは開始アドレスが210、サイズが1なので、210から211までの大きさである。本来であれば「1+1」が2番目のデータのオフセットとなるが、ここではオフセットは10となっている。これは、1番目のデータと2番目のデータの間に「10−2=8」のギャップが存在しているためである。実際に使用されているデータは、開始位置から2bytesしかない。
このギャップは、最初のエクステントデータに書き込みが行われて値が修正されない限り、ほかのプログラムが使用することはできないようになっている。このように、エクステントではスパースに対応したギャップを置くことで、ほかのデータが途中に書き込まれることによるフラグメンテーションを防いでいる。
動的iノード (Dynamic i-node allocation)
ブロックアルゴリズムによるファイルシステムの主な問題点の1つが、「iノードが固定的に割り当てられること」である。iノードはiノードテーブルの順番に従って、連続的に割り当てられる。iノードはオブジェクトの情報を保持しているため、ファイルシステム内に確保できるオブジェクトの上限を制限することを意味している。この制約を克服するために、「動的iノード」方式が提示された。iノード番号を動的に割り当てることによって、iノードの上限値を事実上意識しない方式である。
技術的な実現方法はアルゴリズムに依存するが、この方法を導入するにはiノードのロジカルブロックのマッピング構造やiノードのトラッキング構造など、ファイルシステム全体の見直しが必要となる。JFSなど、動的iノードを導入したファイルシステムでは、ファイルシステムのiノードの配置を組織化するためにB+-Treeの見直しなども行われている。特に、JFSではB+-Treeの葉のノードを形成し、32のiノードを一緒に保持する「iノードエクステント」を使用している。これは、iノードをほかのファイルシステムオブジェクトの近くに配置するものである。
動的iノードは固定的なiノードの制約を解決するものとして期待されるが、いまのところ仕組みが複雑で時間的コストが高いという面もある。
次回は、ここで示した技術が実際に使用されている各ローカルファイルシステムについて紹介する。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
- 連載:Linux Kernel Watch(連載中)
Linuxカーネル開発の現場ではさまざまな提案や議論が交わされています。その中からいくつかのトピックをピックアップしてお伝えします - 連載:Linuxファイルシステム技術解説
ファイルシステムにはそれぞれ特性がある。本連載では、基礎技術から各ファイルシステムの特徴、パフォーマンスを検証する - 特集:全貌を現したLinuxカーネル2.6[第1章] エンタープライズ向けに刷新されたカーネル・コア
ついに全貌が明らかになったカーネル2.6。6月に正式リリースされる予定の次期安定版カーネルの改良点や新機能を詳しく解説する - 特集:/procによるLinuxチューニング[前編] /procで理解するOSの状態
Linuxの状態確認や挙動の変更で重要なのが/procファイルシステムである。/procの概念や/procを利用したOSの状態確認方法を解説する - 特集:仮想OS「User Mode Linux」活用法
Linux上で仮想的なLinuxを動かすUMLの仕組みからインストール/管理方法やIPv6などに対応させるカーネル構築までを徹底解説 - Linuxのカーネルメンテナは柔軟なシステム カーネルメンテナが語るコミュニティとIA-64 Linux
IA-64 LinuxのカーネルメンテナであるBjorn Helgaas氏。同氏にLinuxカーネルの開発体制などについて伺った