NagiosでWebサーバを頑丈にする方法:特集:システム管理の鉄則(後編)(2/2 ページ)
今回は前回「Webサーバ周辺、これだけおさえれば、落ちても大丈夫?」解説した、監視設計のポイントをサンプルとなるモデルシステムに適用し、フリーの監視ツールNagiosを使った具体的な監視設定を行っていきたいと思います。
症状監視の設計
症状監視でまず考えるのはネットワークレベルでの到達性の監視です。このため、まずは以下に対してpingによる到達性の監視を行います。
- サーバA
- サーバB
- ファイアウォール
- ルータ
- DMZ用スイッチ
- 社内用スイッチ
ここで気を付けなければならないことは、監視ツールがDMZのセグメントに設置してあるため、ルータ、社内用スイッチはファイアウォール越しにpingによる到達性チェックをすることになります。従って、ファイアウォールの設定で、これらのパケットに対するフィルタを開けるようにしなければ正しく監視できないので注意してください。
もし、ファイアウォールの仕様上、どうしてもpingによる到達性チェックができない場合は、監視方法をSNMPによるポーリング監視に切り替えるなどの方法が考えられます。
Nagiosではホストに親子関係が指定でき、子のホストへの到達性がなくなった場合、親のホストへの到達性をチェックして、到達できない理由が、子のホストが停止したのか、それとも子のホストのあるネットワークへの到達性がなくなったのかを判断してくれます。
モデルシステムの場合、監視ツールは社内のセグメントに設置されているので、監視ツールが設置されているマシンから見て、ホストごとの依存関係は次のようなツリーになります。
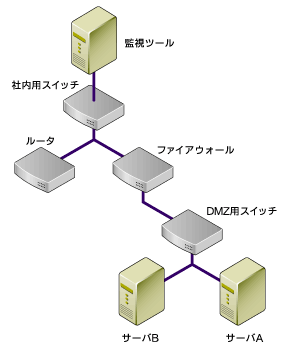
この設定を行うことで監視ツールから送信される障害の通知を劇的に減らすことができます。
例えばファイアウォールが落ちた場合、Nagiosからは以下のホストへの到達性が失われます。
- ルータ
- サーバA
- サーバB
- DMZ用スイッチ
この設定がない場合、管理者には上のすべてのホストに対する障害とファイアウォール自体の障害の検知が通知され、対応する管理者にとって「余計な」情報が伝達されることになり、障害対応の妨げになりかねません。
次にサーバA、サーバBに対しての症状監視ですが、これらのホストのリモートアクセス環境がSSHで提供されていることを前提に、SSHのサービス稼働監視を行います。
この設定には2つ意味があります。
- SSHの稼働監視と外形監視の監視の状況の組み合わせによって発生した障害 がプロセスレベルなのか、OSレベルなのか判断する。
- SSHの稼働監視をすることにより、障害対応にSSHによるリモートからのアクセスが可能かどうか障害発生時に知ることができる。
同一サーバ上の関連しない複数のプロセスを監視すれば、片方に障害が発生した場合は落ちたプロセスの障害であると判断できますし、両方に障害が発生した場合は、大抵の場合OS上の問題であると判断できます。
また、SSHは障害対応作業をするためのリモートアクセスを提供するサービスですから、これに障害が発生していた場合、OSが動いていてpingには反応したからといって、この時点でリモートからの障害対応が難しいことを意味することには変わりありません。
症状監視としてこれだけ監視しておけば、とりあえず、
- ネットワーク機器の障害を依存関係を踏まえて監視
- サーバの障害に対し、プロセス・OSレベルの切り分けが障害発生時にある程度可能
という監視ができますので、これらの設定をNagiosの設定ファイルに落としたものを例示します。
# テンプレート
define host{
name generic-host ; テンプレート名
notifications_enabled 1 ; 通知有
event_handler_enabled 1 ; イベントハンドラの有
process_perf_data 1 ; パフォーマンス情報を保存
retain_status_information 1 ; ステータス情報を保存
retain_nonstatus_information 1 ; ステータス情報以外を保存
max_check_attempts 20 ; ホストチェックの最大Retry回数
notification_interval 60 ; 障害発生から60分したら再通知
notification_period 24x7 ; 24x7で通知
notification_options d,r ; Down, Recover時に通知
register 0 ; この設定がテンプレートであることを指定
}
define host{
use generic-host
host_name router1
alias Router #1
address 172.16.0.1
parents firewall1
check_command check-host-alive
}
define host{
use generic-host
host_name serverA
alias Server A
address 172.16.0.9
parents switch1
check_command check-host-alive
}
define host{
use generic-host
host_name serverB
alias Server B
address 172.16.0.10
parents switch1
check_command check-host-alive
}
define host{
use generic-host
host_name switch1
alias Switch #1
address 172.16.0.15
check_command check-host-alive
}
define host{
use generic-host
host_name firewall1
alias Firewall #1
address 192.168.0.2
parents switch2
check_command check-host-alive
}
define host{
use generic-host
host_name switch2
alias Switch #2
address 192.168.0.3
check_command check-host-alive
}
define hostgroup{
hostgroup_name default
alias DefaultGroup
contact_groups admin-contactgroup
members router1,serverA,serverB,switch1,switch2,firewall1
}
define contact {
name generic-contact
service_notification_period 24x7
host_notification_period 24x7
service_notification_options w,u,c,r
host_notification_options d,r
service_notification_commands notify-by-email
host_notification_commands host-notify-by-email
register 0
}
define contact {
use generic-contact
contact_name admin
alias Server Admin
email jji@atmarkit.co.jp
}
define contactgroup{
contactgroup_name admin-contactgroup
alias admin-contactgroup
members admin
}
define service{
name generic-service ; テンプレート名
notifications_enabled 1 ; 通知有
event_handler_enabled 1 ; イベントハンドラの有
process_perf_data 1 ; パフォーマンス情報を保存
retain_status_information 1 ; ステータス情報を保存
retain_nonstatus_information 1 ; ステータス情報以外を保存
is_volatile 0 ; 通常サービスチェック
max_check_attempts 3 ; リトライ回数
normal_check_interval 5 ; 5分間隔でチェック
retry_check_interval 1 ; リトライ間隔
check_period 24x7 ; 24x7でチェック
notification_interval 240 ; 障害発生から240分したら再通知
notification_period 24x7 ; 24x7で通知
notification_options w,c,r ; Warning, Critical, Recover時に通知
contact_groups admin-contactgroup
register 0 ; この設定がテンプレートであることを指定
}
# Service definition
define service{
use generic-service
host_name router1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{
use generic-service
host_name switch1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{
use generic-service
host_name switch2
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{ use generic-service
host_name firewall1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{
use generic-service
host_name serverA
service_description HTTP
check_command check_http
}
define service{
use generic-service
host_name serverA
service_description SSH
check_command check_ssh
}
define service{
use generic-service
host_name serverA
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{
use generic-service
host_name serverB
service_description POP
check_command check_pop
}
define service{
use generic-service
host_name serverB
service_description SMTP
check_command check_smtp
}
define service{
use generic-service
host_name serverB
service_description DNS
check_command check_dns
}
define service{
use generic-service
host_name serverB
service_description SSH
check_command check_ssh
}
define service{
use generic-service
host_name serverB
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
さらに詳細な監視と運用
また、実際に設定可能かどうかは皆さんのシステムに依存するため、ここではアイデアだけを提示しますが、Nagiosが提供するHTTPのサービス稼働監視では、オプションで監視の対象とするURIとサーバからの応答に、一定の文字列が含まれているかどうかをチェック可能なため、テスト用のCGIなどを用意するなどで、監視ツールの一般的な利用ではできないような特殊な監視も実装可能です。
例として、以下のPerlスクリプトによるCGIを挙げます。
#!/usr/bin/perl
#
# Disk test CGI Script
my $msg = "FAIL"
; my $test = "/var/log/test.txt";
if(open(TST, "> ${test}")){
for(my $i = 0;$i
print TST "1234567890123456789012345678901234567890\n";
}
$msg = "SUCC";
}
print "Content-type: text/plain\n\n";
print $msg . "\n";
このスクリプトは非常に単純ですが、サーバのファイルシステムへの書き込みのみを明示的に行っているため、このスクリプトへの監視を、その応答へのチェック付きで行うことにより、簡単なディスク監視を実装できます。
実はディスクへの監視は意外と難しく、通常はログ監視で、OSのエラーメッセージ中のディスクのエラーのパターンを検出するよう設定するのですが、ディスクのエラーはその性格上、一端で出すと大量にログを吐きます。このためログ監視で監視をすると大量に障害が検知してしまうため障害対応の妨げになりかねません。
もちろん上のスクリプト例は完全ではありませんし、ディスク監視に限らず、このような監視を実装するためにはある程度の開発が必要になるため、すべてのケースで有効だとは思えませんが、効率の良い症状監視の例として挙げてみました。
最後に、監視設計におけるもう1つの重要なポイントを挙げておきます。経験上どんなに詳細な監視を行ったとしても、監視では検知できない障害という最悪の状態は起こり得ます。このため、いったん監視ツールに設定を行った場合も、実際に起こった障害の経験や、システムへの変更などを踏まえて監視設計を再考して、より効率の良い監視運用に努めることが、当たり前の話ですがシステム監視の最も重要なポイントである点を忘れずに日々の運用に励んでください。
Copyright © ITmedia, Inc. All Rights Reserved.