NagiosでWebサーバを頑丈にする方法:特集:システム管理の鉄則(後編)(1/2 ページ)
今回は前回「Webサーバ周辺、これだけおさえれば、落ちても大丈夫?」解説した、監視設計のポイントをサンプルとなるモデルシステムに適用し、フリーの監視ツールNagiosを使った具体的な監視設定を行っていきたいと思います。
モデルシステムについて
ここではインターネット向けの顧客向けWebアプリケーションを提供するシステムを、Nagiosという監視ツール上で監視を行うというモデルを通して監視システムの設計例を示していきます。
まず、モデルとなるシステムですが、以下のような構成とします。
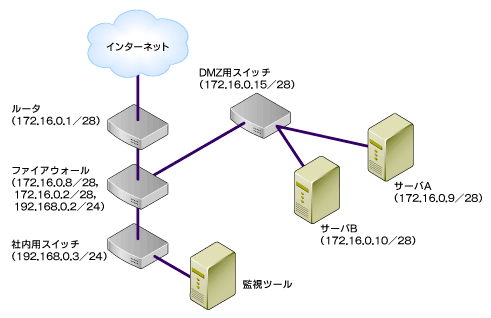 図2-1 モデルシステム図
図2-1 モデルシステム図| システム機器 | LANでの位置づけ | |
|---|---|---|
| サーバA (172.16.0.9/28) | システム中核。Linuxマシンで動作するWebサーバ | |
| サーバB (172.16.0.10/28) | メールサーバ(SMTP、 POP)、DNSサーバがもう1台のLinuxマシンで動作している | |
| ファイアウォール(172.16.0.8/28、 172.16.0.2/28、 192.168.0.2/24) | サーバA、 B、 Cを収容するDMZ、インターネット、社内の3つのセグメ ントを管理する | |
| ルータ (172.16.0.1/28) | ISPへの接続に利用 | |
| DMZ用スイッチ (172.16.0.15/28) | サーバA、 B、 Cを収容 | |
| 社内用スイッチ (192.168.0.3/24) | サーバA、 B、 Cを収容 | |
なお、本来であればグローバルなIPアドレスが振られてしかるべき、DMZ、グローバルのセグメントにあるサーバ、ネットワーク機器のIP アドレスがプライベートになっていますが、これはあくまでモデルシステムであるということでご了承ください。
このシステムはインターネットから顧客によるアクセスと、社内からのメンテナンス用のアクセスがあるものとします。
監視ツールについて
次に監視ツールのNagiosですが、Nagios はフリーの監視ツールの中でも実績があり、日本でのユーザーも多いため、比較的情報を入手しやすいのが特徴です。
この記事では2004年2月2日にリリースされたバージョン1.2を利用します。
Nagiosのインストール自体は、「連載:24×365のシステム管理」の「第5回 Webサーバの監視?その2 URL監視用のツールをインストールする?」で1.0b6のインストールが解説されています。
また、設定についても同連載に解説されています。特にこの記事では監視設定の中核である以下の2つの設定ファイルにのみ焦点を絞って解説します。
これら以外の設定ファイルについては皆さんの環境に従って、適宜設定をしてください。
どこから外形監視をするのか?
外形監視の「可能な限りユーザーの利用イメージに近い監視方法を採用する」というポリシーからすると、実際のユーザーと同じ環境、つまりこのモデルシステムでいうとインターネット側からの監視が最も好ましい監視環境といえましょう。
しかし、インターネット側からの監視となると、症状監視でシステムの細かい情報を監視するためには、それらの監視対象にインターネットからのアクセスを許可する必要が発生し、セキュリティ上好ましいことではありません。
このため、インターネット側からの監視はあきらめるのが一般的ですが、この問題の比較的現実的な解決策としては次の2つがあり得ます。
- 外形監視だけ外部の監視サービスを利用する。
- ADSLや光接続サービスを利用し監視専用回線を利用する。
監視を専業とするMSPだけではなく、監視サービスを提供するASPや、ISP自体が監視サービスを提供している場合もあり、これらのサービスを利用して、外形監視だけを外部の監視サービスを利用するのも1つのアイデアです。この方法であれば、インターネット側からの監視が好ましい外形監視と、内部からの監視が好ましい症状監視を比較的安価に両立することができます。
しかし、これらのサービスを利用した場合、提供するサービスの仕様によって監視方法が限定されてしまうのが難点です。筆者の知る限り、安価な監視ASPサービスはpingを打つだけの例が多く、これでは外形監視としては適当ではありません。このため、この方法を使う場合は、コストと監視方法の適正なバランスを取って導入する必要があります。
2番目のADSLや光接続サービスを利用して監視専用回線を用意し、ここから監視を行う方法ですが、最近のブロードバンドの一般への普及で、これらのインターネット接続はかなり安価に利用できるので、コスト的にもあながちむちゃな選択肢ではないと思われます。この方法だと、先に挙げた監視ASPサービスを利用する場合と異なり、サービスの仕様に制限されない自由な監視設定も可能ですし、また、監視回線をメンテナンス用に利用したり、メインのインターネット接続に障害があったときの非常回線としても利用可能になるのでお勧めの方法といえます。
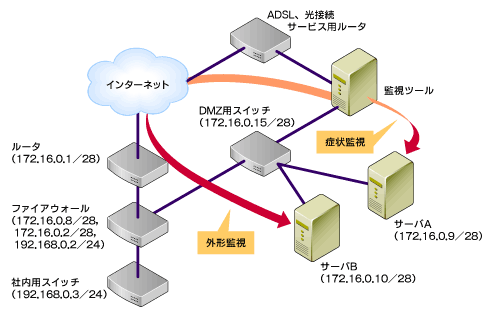 図2‐3 ADSLや光接続サービスを利用した監視モデル
図2‐3 ADSLや光接続サービスを利用した監視モデル筆者としてはこの方法での監視を前提に進めていきたいところではありますが、監視ごときでいまさらそんなコストは掛けられないという方のために、今回の記事では、監視ツールが稼働するマシンが社内セグメントにあるという前提で解説を進めてゆきます。
前回お話しした監視設計のポイントは以下のとおりでした。
(1) システム全体、もしくはシステムを構成するモジュールが提供するサービスに対して監視方法を決める。――「外形監視」
(2) システムの構成するモジュールをさらに細かいコンポーネントに分け、このコンポーネントごとに監視方法を決める。――「症状監視」
(3) 監視するポイントは必要最小限に。
外形監視の設計
まずは(1)の外形監視ですが、このシステムで外形監視の対象となりそうなものは、
- サーバAのWebサーバ
- サーバBのメールサーバ
- サーバCのDNSサーバ
の3点だと考えられます。従ってこれらに対して「可能な限りユーザーの利用イメージに近い監視方法」を採用し外形監視を実施します。
最初に、サーバAのWebサーバですが、NagiosではHTTPによるサービス稼働監視を提供しているのでこれを使います。Nagiosではサービス稼働監視を行うURIが指定可能になっているので、CGIなどを使って動的にコンテンツを生成するサービスを提供している場合には、実際に動的に生成される URI を監視対象のURIとして指定してください。
次に、サーバBのメールサーバですが、このサーバではSMTPとPOPのサービスが行われています。NagiosではSMTPのサービス稼働監視は用意されていますが、残念ながらPOPに対するサービス稼働監視は用意されてないため、SMTPに対してはサービス稼働監視を、POPについてはポート監視を実施します。
最後に、DNSサーバですが、Nagios ではDNSに対するサービス稼働監視も提供しているので、サーバBへの監視にDNSによる監視も設定します。
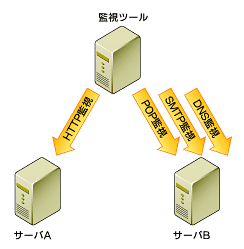 図2‐4 外形監視
図2‐4 外形監視以上、3つの監視項目を外形監視することで、システムのサービス提供状況を監視することができます。前にもお話ししたとおり、単純にシステムの稼働だけをチェックするのであれば、この4つの監視項目だけでも監視として機能するとは思いますが、障害発生時のもう少し具体的な状態を把握するため、症状監視の設定をしてゆきます。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。