第4回 論理データベース操作の第一歩:初めてのSQL Server 2000(1/2 ページ)
RDBの中心は、データを格納するテーブルである。論理DB操作の手始めとして、今回は実際に手作業でテーブルを作成してみよう。

前回は、SQL Server 2000の物理データベース・アーキテクチャについて解説した。大量のデータを効率よく利用し、管理するために、OSのファイル・システムの機能をそのまま使うのではなく、データベース・システム側でデータ管理にさまざまな工夫を加えていることが分かった。
しかしデータベースを操作するアプリケーション・プログラムは、データが物理的にどのように格納されているかを意識しない。テーブルやビュー(仮想テーブル)などといった、論理的なオブジェクトの集合体としてデータベースを操作する。
今回は、論理データベースの基礎について、簡単なサンプル・データとSQL Server Enterprise Manager(管理ツール)での実行例などを紹介しながら解説していこう。
リレーショナル・データベース基礎の基礎
データベースは、データ・モデルに従ってデータを管理するシステムである。データ・モデルとは、データの型や、データとデータとの関係を管理する概念だ。
SQL Serverを始め、現在、データベースといえば、リレーショナル・データ・モデルに基づくリレーショナル・データベースが主流だが、このほかにも階層型データ・モデル(メインフレーム環境などで使われていた)やネットワーク型データ・モデル(かつてはよくCOBOLプログラムで使われていた)などがあり、特定用途では現在でも使われている。ただしほとんどのプログラマや管理者は、リレーショナル・データベース以外に触れる機会は少ないだろう。
リレーショナル・データ・モデルでは、すべてのデータを2次元の表(テーブル)で表す。例えば次のようなものだ。
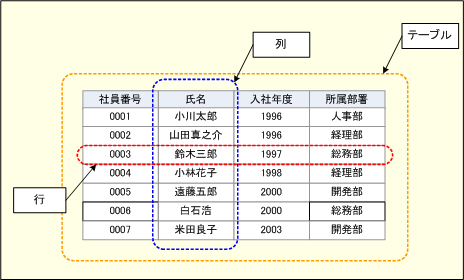
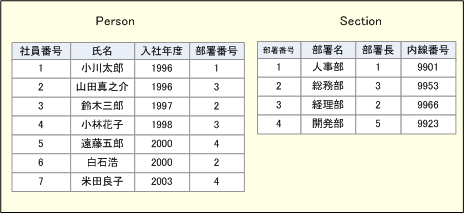
テーブルの例(人事データ)
リレーショナル・データ・モデルでは、すべてのデータをこのような2次元の表として扱う。このような表データから、条件を満たす行や列を取り出して(選択して)操作したり、別の表と組み合わせて(結合して)操作したりする。
リレーショナル・データ・モデルでは、このような表データから、条件に合致する行だけを取り出して操作したり(入社年度が2000年の社員だけ、など)、別の表と組み合わせて(結合して)仮想的な表を作って操作したりできる。データ・モデルを理解しやすく、柔軟性が高いのがリレーショナル・データベースの特長である。
図に示したとおり、1つのテーブルは、そこに含まれる複数の列で構成される。この例では、社員番号、氏名、入社年度、所属部署が列である。このようにテーブルは、どのような列で構成されるかによって構造が決定される。テーブル構造は、リレーション・スキーマと呼ばれることもある。スキーマ(schema)は「概要」「略図」の意味だ。データベースの論理データ構造を設計することを「スキーマ設計」という。
テーブルの縦方向は「列」(「カラム」)、横方向は「行」(「レコード」)と呼ぶ。この人事テーブルの例では、社員1人分のデータが1つの行に対応している。一連のリレーション・スキーマの列に従って格納された1つの行データを指して「レコード・オカレンス」と呼ぶこともある。オカレンス(occurrence)は「存在」という意味だ。
テーブルの列のうち、特別な意味を持つものはキー(key)と呼ばれ、特に、その列の値が、全行のオカレンスに対して異なる値を持つものを主キー(primary key)と呼ぶ。つまり、ある行データの主キーの値は、テーブルの中でその行データを唯一特定できる値である。前出の例なら、「社員番号」が主キーになる。社員番号が決まれば、社員(行データ)を一意に特定できる。
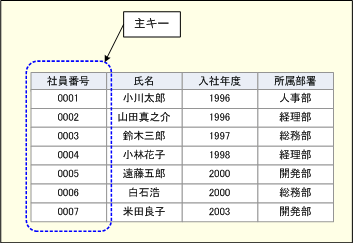
主キー(primary key)
テーブルの列のうち、全行のオカレンスに対して、その列の値が異なるもの(ユニークなもの)を主キーと呼ぶ。社員テーブルでは、社員番号を主キーにできる。同じ社員番号を持つ社員は2人といないからだ。
主キーとなっている列を利用すれば、テーブルから重複せずに1つの行を特定できるようになる。これは、あるテーブルから別のテーブルを参照する際に重要な意味を持つ。
データベースを利用するアプリケーションは、必要なデータの検索や更新、削除をデータベースに対して実行する。これらデータベースに対する操作全般は「データ操作(data manipulation)」と呼ばれる。特にアプリケーションからデータベースへのデータ検索依頼は、「問い合わせ」という意味のクエリ(query)という用語を使う。SQL Serverでは、データベースへの問い合わせ用コードをGUIで作成できるツールが用意されている。これについては、後で具体的な例とともにご紹介しよう。
Enterprise Managerでテーブルを新規作成する
ここからは、実際にSQL Serverでごく簡単なテーブルを作成しながら話を進めよう。
マニュアルでテーブルを作成するには、連載第2回でご紹介したSQL Server Enterprise Manager(以下Enterprise Manager)を利用する。
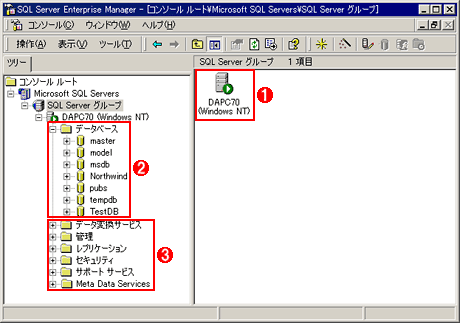
SQL Server Enterprise Manager
Enterprise ManagerはMMC(Microsoft Management Console)ベースのGUIアプリケーションで、テーブルの作成からバックアップなどのデータベースの管理まで、SQL Serverデータベースに関するさまざまな作業ができる。
(1)SQL Serverグループ。自分のコンピュータにSQL Serverをインストールしたときには、自分のコンピュータだけがここに表示される。ネットワーク内にSQL Serverをインストールした別のコンピュータがあるなら、それをSQL Serverグループに追加して、リモート管理することも可能。
(2)このコンピュータのSQL Serverによって管理されているデータベース。SQL Serverのインストール直後でも、各種システム・データベースが一覧される。
(3)そのほかのサービス・グループ。今回は述べないが、データ変換サービスやレプリケーション(複製)など、データベースに対するさまざまな作業をここから実行できることが分かる。
現在のデータベース一覧は、SQL Serverグループの「データベース」に表示される。小文字で始まるデータベース(master、modelなど)は、SQL Serverシステムが使うシステム・データベース、それ以外がユーザー・データベースである(Northwindはチュートリアル用として提供されているもの)。
新規データベースを作成するには、左側のペインにある[データベース]フォルダを右クリックし、表示されるメニューの[新規データベース]を実行する。
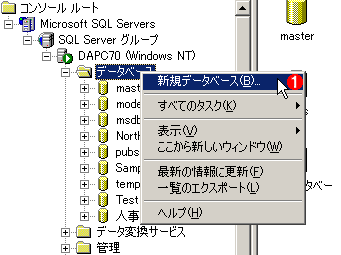
こうして表示されるダイアログの[名前]部分にデータベースの名前を指定する。任意でよいが、ここでは仮に「人事データベース」とした。
細かい設定はさておき、ここではデータベースの名前だけ指定して、[OK]ボタンをクリックする。これでユーザー・データベースが出来上がる。

作成されたデータベース
「ダイアグラム」や「テーブル」「ビュー」などはデータベースを構成するオブジェクトだ。「テーブル」を選択すると、何もしていないのに多数のテーブルが存在することが分かる。これらはSQL Serverシステムが使用するシステム・テーブルである(通常、アプリケーションからは直接アクセスしない)。
(1)今回作成したデータベース。
作成した「人事データベース」の中には、さまざまなデータベース・オブジェクトが作成されている。上の画面は、これらの中から[テーブル]オブジェクトを選択し、テーブル一覧を右ペインに表示したところ。これらはSQL Serverシステムが使用するテーブル群で、通常はアプリケーションから直接にはアクセスしない。
ここでは例として、ごく簡単な人事テーブルを作成する。作成するテーブルは以下のPersonとSectionの2つである。Personテーブルには各社員のデータを、Sectionテーブルには部署データをそれぞれ格納する。
テーブルを作成するには、Enterprise Managerのデータベースで[テーブル]を右クリックし、表示されるポップアップ・メニューの[新規テーブル]を実行する。そして次に表示されるダイアログでテーブルを構成する列の情報を定義する。
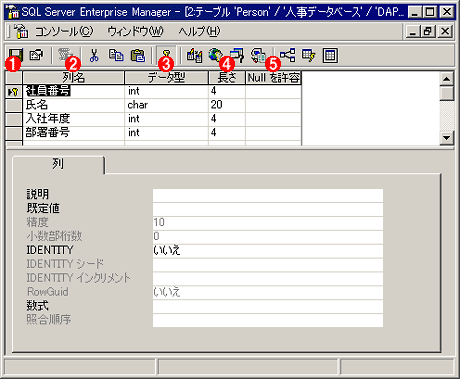
新規テーブルの作成
テーブルの作成では、各列の名前、データ型、長さ、Nullの許容可否を入力する。一番左にある小さな鍵のマークは、主キーであることを表す。
(1)主キーとなる列には小さな鍵マークのアイコンが表示される。主キーを設定するには、列を右クリックし、表示されるポップアップ・メニューの[主キーの設定]を選択する。
(2)列の名前。
(3)列のデータ型。数値型(intなど)か文字型(charなど)かなどを指定する。
(4)列の最大データ・サイズをバイト単位で指定する。
(5)この列のデータに対し、Null値を許容するかどうかを選択する。Null値を許容する場合は、この項目をクリックしてチェックマークを付ける。
主キーについては前述したとおりである。Enterprise Managerで特定の列を主キーに指定するには、その列を選択してマウスを右クリックし、表示されるポップアップ・メニューの[主キーの設定]を選択する。今回は、Personテーブルの社員番号、Sectionテーブルの部署番号をそれぞれ主キーにする。
Null値許容すると(Nullは「ヌル」や「ナル」と読む)、その列に関して、値を含まない行の存在を許すことになる(Nullは日本語では「空値」と呼ばれる)。Nullは数字のゼロや空文字列(“”)とは異なり、何の値も入っていないことを示す。逆にNull値を許容しない場合は、必ず何らかのデータをその列に入力しなければならなくなる。
例えば社員テーブルで、社員個人の携帯電話番号を格納する列があったとしよう。「Nullを許容」にしておけば、番号が不明な場合は何も入力しないでおくことができる(Nullを許容しなければ、この場合でも何らかのデータを入力しなければならない)。一般的に行のオカレンスによっては、列に入力すべきデータが存在しないとか、データを入力すべきでないといったケースがある。このような場合に「Nullを許容」を指定することになる。ただしあまり乱用すると、後のデータ操作で例外処理を設けるなど煩雑になるので指定は最低限にすべきである。
同様にしてSectionテーブルも作成する。
Copyright© Digital Advantage Corp. All Rights Reserved.