パーティショニングとデータ圧縮を併用するメリット:Oracleパーティショニング実践講座(5)(1/3 ページ)
本連載では、大規模データベースでのパフォーマンス・チューニングの手法として、Oracleパーティショニングを解説する。単なる機能説明にとどまらず、実機による検証結果を加えて、より実践的な内容をお届けする。(編集部)
前回の「パラレル処理の有効性と落とし穴を検証する」では、パーティショニングとパラレル処理を併用することの有効性と注意点について紹介しました。今回は「データ圧縮」とパーティショニングとの関係について解説します。
Oracleの表圧縮機能とは何か
大規模データを分割することでアクセスするデータを絞り込むパーティショニングや、大規模データへのアクセスを並行処理させるパラレル処理などは、アクセスする対象や処理の効率化を実現する機能でした。
それに対してデータ圧縮とは、表に格納されるデータを小さく保持するという考え方です。データそのものを小さくできるため、同量の非圧縮データよりも小さなディスク容量で格納でき、データにアクセスする場合のデータブロックも少なくて済むため、検索時間の短縮を期待できます。データウェアハウスのような大量データを格納している表や、過去の売上履歴などのように頻繁に更新されない情報への検索で利用するのが効果的だといわれています。
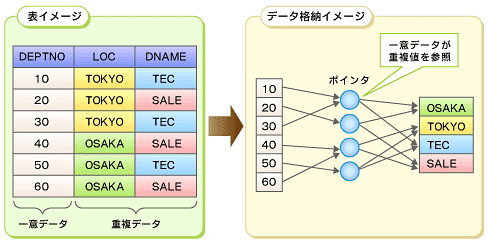
Oracleの表圧縮機能では、データブロック内の重複値を排除することでデータが圧縮されます。データブロックに格納された圧縮データは自己完結型であり、データブロック内の圧縮データを解凍するために必要な情報は、すべてそのデータブロック内に格納されています。図1のように、行ごとに重複値を指し示すポインタによって管理することでデータ圧縮を実現しているため、重複データのサイズと重複の度合いによって圧縮率は異なってきます。
データを圧縮する2つの方法
表データを圧縮するには「データのロード時に圧縮する」方法と、「既存の表データを圧縮する」方法が存在します。
データのロード時に圧縮する
データのロード時に圧縮するためには、COMPRESS属性を設定した表にバルクINSERTまたはバルク・ロードでデータを格納する必要があります。通常のINSERTやインポート処理(IMPORT)では、COMPRESS属性を設定した表であっても圧縮されません。
データのロード時に圧縮する処理
- SQL*Loaderのダイレクト・パス・モード
- ダイレクト・ロードINSERT
- パラレルINSERT
- CREATE TABLE COMPRESS AS SELECT …;
CREATE TABLE <table_name> ( 列定義 …) segment_attributes_clause COMPRESS;
パーティション表ではパーティションごとにCOMPRESS、NOCOMPRESSを指定できます。
既存の表データを圧縮する
ALTER TABLE文にて、すでに表に格納されているデータを圧縮できますが、圧縮している間、表セグメントには排他ロックが保持されます。
ALTER TABLE <table_name> MOVE COMPRESS;
Copyright © ITmedia, Inc. All Rights Reserved.