文字判定処理の詳細
S1sTokenizerクラスではトークン化について責務を持たせるため、次の文字が何か、現在読み込んでいる文字の位置はどこか、空白文字の読み飛ばしといった処理についてはScannerLineクラスを用意して、このクラスが行うようにしました。
このクラスには、1行の文字列をフィールドline、現在読み込んでいる文字をフィールドcurrent、文字列の長さをフィールドmaxIndexに保持します。nextメソッドでは、次の文字を読み込み、currentを1つ進めます。peekメソッドでは、次の文字を読みますが、currentを進めません。読み込める文字がない場合は-1を返します。hasNextメソッドは、lineがnullではなく、かつ、currentがmaxIndexではないときにtrueを返します。cutWhitespaceメソッドは空白文字を読み飛ばします。
public class ScannerLine {
private String line;
private int current;
private int maxIndex;
public ScannerLine(String s) {
line = s;
current = 0;
if (line != null) maxIndex = line.length();
}
public char next() {
if (!hasNext()) { return (char)-1; }
return line.charAt(current++);
}
public char peek() {
if (!hasNext()) { return (char)-1; }
return line.charAt(current);
}
public int getIndex() {
return current;
}
public boolean hasNext() {
return (line != null) && (maxIndex != current);
}
public void cutWhitespace() {
char ch = peek();
while (Character.isWhitespace(ch)) {
next();
ch = peek();
}
}
}
S1sTokenizerクラスでは、ScannerLine型のフィールドslineを用意します。hasNextメソッドではslineを使って空白文字を読み飛ばしたうえでslineのhasNextメソッドで判定をしています。
public boolean hasNext() {
sline.cutWhitespace();
return sline.hasNext();
}
nextメソッドでは、処理内でTokenクラスのオブジェクトを生成するので、次に読み込む文字chを使って、どんなトークンが次に来るのかを推測して処理をします。chが数値であれば、数値のトークン化をしますし、文字であれば、識別子か予約語が続いているとして処理をします。"{"や演算子の場合には、それらをトークン化しています。
また、index変数へトークンが開始する位置を記憶させ、トークン化が終わってからtokenへsetIndexNumberメソッドを使って設定しています。
public Token next() {
Token token = null;;
int index = sline.getIndex();
char ch = sline.peek();
if (Character.isDigit(ch)) {
(略)// 数値のトークン化
} else if (Character.isLetter(ch)) {
(略)// 識別子、予約語のトークン化
} else {
switch (ch) {
case '{':
token = new Token(TokenUtil.L_BRACE, sline.next());
break;
(略)
case '*':
case '/':
token = new Token(TokenUtil.OPE_MD, sline.next());
break;
default:
token = new Token(TokenUtil.ERROR, sline.next());
}
}
token.setIndexNumber(index);
return token;
}
(略)
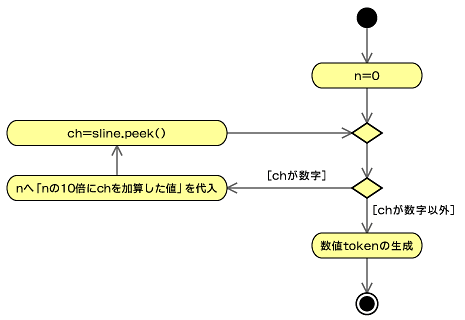
数字から数値へのトークン化
数字から数値へのトークン化について見てみます。理論として理解をするには、有限オートマトンというものを導入するとよいのですが、ここでは実践的に理解をするということで、実際の処理を行うプログラムを見てみましょう。それほど難しいものではないので、すぐに理解できるはずです。
最初にnへ0を代入しておき、数字が続く限り、nを10倍にして読み込んだ数字を加算するという処理をしているだけです。peekメソッドを使って次の文字を取得し、それが例えば"+"であれば、Character.isDigit(ch)がfalseとなり、while文が終了します。最後に、計算したnをトークン化します。数値の範囲についてはここではチェックしていませんが、本来はTokenで保持できないような値の場合はエラーとするべきです。
double n = 0;
while (sline.hasNext() && Character.isDigit(ch)) {
n = n * 10
+ Double.parseDouble(Character.toString(sline.next()));
ch = sline.peek();
}
token = new Token(TokenUtil.NUMBER, n);
予約語と識別子のトークン化
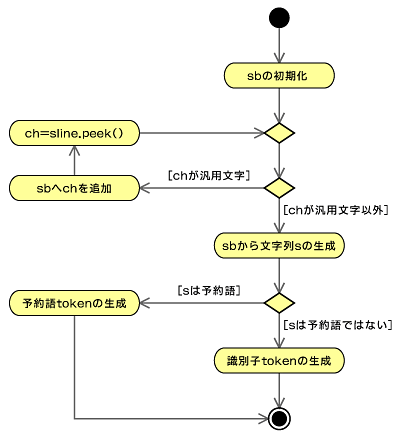
同様にして、予約語や識別子については、汎用文字が続く間は文字列を連結することにより、字句解析を進めています。今回は"main"だけしか予約語がありませんし、識別子は定義していないので、単純に読み込んでいって"main"とならない汎用文字列についてはエラーとしてもよいのですが、S1sを拡張したときに簡単に対応できるよう、このように実装をしています。
なお、"value1"のようなLetter(文字)で始まり英数字が続く識別子を許す場合には、改良が必要です。
StringBuilder sb = new StringBuilder();
while (sline.hasNext() && Character.isLetter(ch)) {
ch = sline.next();
sb.append(ch);
ch = sline.peek();
}
String s = sb.toString();
if (TokenUtil.isKeyword(s)) {
token = new Token(TokenUtil.KEYWORD, s);
} else {
token = new Token(TokenUtil.IDENTIFIER, s);
}
字句解析プログラムを実行しよう!
S1sTokenizerクラスを使用するScannerTestクラス(別途掲載)を用意して実行すると、「main { 0 }」というS1sプログラムが記述されたソースファイル01.s1sからは、下記のようなトークンリストが生成できます。各トークンについて開始位置を示すindexが正しく表示されていることが分かるはずです。
> java ScannerTest 01.s1s
--------
line :1
index:0
type :8
value:main
--------
line :1
index:5
type :6
value:{
--------
line :1
index:7
type :1
value:0.0
--------
line :1
index:9
type :7
value:}
以上のように、字句解析をすることにより、トークンリストを取得できるようになります。
次回は「構文解析」を行って、バイナリコードを生成
字句解析にも、いろいろな実装方法があることを紹介しましたが、どのレベルまで要求されているのかによって、選択肢は変わってきます。トークンクラスの設計についても、もっと簡単に済ませることもできますし、もっと情報を追加することもできます。作成するプログラミング言語に合わせて一番良いと考えられるものにしていけばよいのです。
さて、ここまで来ると、あともう少しでコンパイラに最低限必要な機能の実装が終わります。次回は、この字句の並びが構文として問題がないかをチェックする「構文解析」について、どのように作成すればよいかの説明をします。また、実際にS1sからSvm1のバイナリコードを生成する方法についても解説をします。お楽しみに。
今回作成したソースはここからダウンロードできます。
筆者紹介
小山博史(こやま ひろし)
Webシステムの運用と開発、コンピュータと教育の研究に従事する傍ら、オープンソースソフトウェア、Java技術の普及のための活動を行っている。Ja-Jakartaプロジェクトへ参加し、コミッタの一員として活動を支えている。また、長野県の地域コミュニティである、SSS(G)やbugs(J)の活動へも参加している。
Copyright © ITmedia, Inc. All Rights Reserved.