全文検索エンジン「Lucene.Net」を使う:連載:VBで実践! 外部コンポーネント活用術(1/3 ページ)
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。

powered by Insider.NET
2010/09/06 更新
「Lucene.Net」は.NET Framework上で利用できる「全文検索エンジン」です。例えば、ASP.NETを使ってWebサイトを作成する際に、サイト内のコンテンツを検索する検索ページを作成したいという場合や、Windowsアプリケーションで全文検索機能を利用したい場合にLucene.Netが利用できます。
Lucene.NetはApache Software Foundationが開発しているプロジェクトの1つで、オープンソースで開発されています。Java言語で記述された「Lucene」がそのオリジナルであり、これは、Wikipediaをはじめ多くのWebサイトで現在利用されています(Lucene-java WikiのPowerdBy)
Luceneの.NET版であるLucene.NETは、Java版と同様Apache Software Foundationの「Lucene.Netプロジェクト」で提供されています。今回は、このLucene.Netを紹介します。Lucene.Netを利用することにより、Webサイトで独自の全文検索機能を実現できるようになります。
Lucene.Netの概要
全文検索とは、簡単にいうと「複数のテキストから特定の文字列を検索する」機能です。検索処理は、その方法から「逐次処理型」と「インデックス型」に大別されます。
「逐次検索型」は、UNIXのgrepコマンドのように、実行するたびにテキストをすべて走査して検索を行うものです。これに対し「インデックス型」は、対象となるテキストから事前に単語(「トークン」と呼ばれます)を取り出し、検索語の候補となるトークンの情報(インデックス)を作成しておき、検索の際にはインデックスを参照して検索処理を行うという方法です。
Lucene.NETはインデックス型で、事前にテキストからトークンを切り出しておき、インデックスを作成したうえで検索処理を実行します。
■日本語の処理に必要なツール
全文検索を行うLucene.NET本体に加えて、日本語の環境では、テキストからトークンを切り出すための独自の処理が必要となります。この処理は一般的に「形態素解析」と呼ばれるもので、日本語による全文検索を行う際に重要な役目を果たします。
英文では単語ごとにスペースで区切られて文章が記述されているため、文章を解析するための処理はそれほど複雑ではありませんが、単語の区切りが明確でない日本語の文章を解析するには、独自の高度な形態素解析処理が必要となります。本稿では形態素解析については触れませんが、日本語の文章をトークンに分解するために必要なツールとだけ考えていただければよいでしょう。
オリジナルであるJava版のLuceneを含め、Apache Software Foundationで配布されているLuceneには、日本語に対応したトークンを取り出す機能(=日本語アナライザ)が付属していません。ただし日本語形態素解析ツールである「MeCab」をJavaに移植した「Sen」を提供する「Sen Project」が、Luceneで利用できる日本語アナライザ(詳細後述)を配布しています。
Lucene.Netに関しては、原稿執筆時点では、同様の日本語に対応するツールが見当たりませんでしたので、本稿ではSen Projectが提供するJava版の日本語アナライザをベースに、筆者が.NET環境に移植したものを使用します。
Lucene.Netによる全文検索処理
Lucene.Netでは、主に次の2つの処理を行います。
(1)インデックス作成処理
(2)検索処理
(1)では、対象となるテキスト・ファイルを読み込んでトークンを取り出し、後述するインデックスを作成します。インデックスには、走査したファイルの情報と、そのファイルに含まれるトークンの情報が格納されます。Lucene.Netでは、インデックスの格納先としてフォルダを指定します。このフォルダには、インデックス情報が格納された独自のファイルが生成されます。
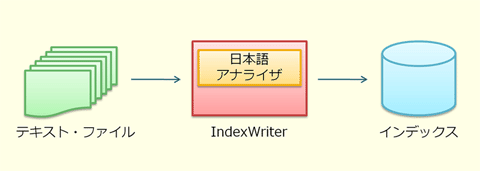
インデックスを作成すれば、検索処理が利用可能となります。検索処理は、事前に作成済みのインデックスを参照して、検索語として入力されたテキストを検索する処理です。この検索により得られた結果を画面に表示したり、Webブラウザに返したりすることで、検索結果を確認できるようになります。
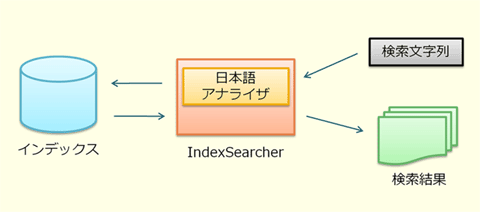
■インデックスの中身
Lucene.NETでのインデックスは、リレーショナル・データベースのテーブルのようなものと考えることができます。検索の単位となる1つのテキストは、検索情報が格納されたDocumentクラスのオブジェクトとして表され、これはデータベースのレコードに相当します。
インデックスには、このDocumentオブジェクトが検索対象のテキストと同じ個数だけ格納されます。また、データベースでは1つのレコードが複数のカラムを持つように、Documentオブジェクトには複数のField(フィールド)を作成できます。
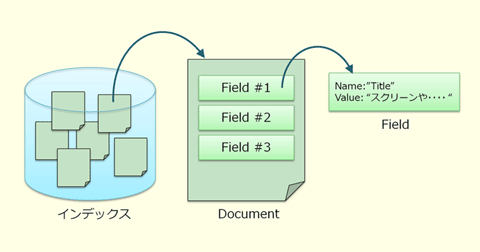
例えば、Webサイトで全文検索を行う場合に、WebページのURLと、ページに含まれるコンテンツ(検索対象のテキスト)、さらに<title>タグの内容を格納する3つのフィールドを用意し、これらをDocumentオブジェクトに格納しておくと、検索にヒットしたWebページのURLを表示したり、検索結果を表示する際にWebページのタイトルを表示したりすることが可能になります。
準備(ツールのインストール)
ここから実際にインデックスを作成して、検索処理を実装する例を示します。その前に、Lucene.Netのインストールと、日本語アナライザに関連するツールのインストールについて説明しておきます。
■Lucene.Netのインストール
Lucene.NetはApache Software FoundationのLucene.NetプロジェクトのWebサイトからダウンロードできます。Subversionを使って最新のソース・コードを直接取得できますが、安定版がZIPファイル(Incubating-Apache-Lucene.Net-2.0-004-11Mar07.bin.zip)で提供されていますので、こちらをダウンロードするのが簡単です。
ダウンロードしたZIPファイルを適当なフォルダに展開すれば、インストールは完了です。展開した中に含まれる「src\Lucene.Net\bin\Release\Lucene.Net.dll」をアプリケーションで使用します。
■日本語アナライザの展開
筆者が作成した日本語アナライザをダウンロードします(JapaneseAnalyzer.zip)。ZIPファイルにはVisual Studioのプロジェクトが含まれていますので、適当なフォルダに展開します。これに含まれるJapaneseAnalyzer.dll、MecabDotNet.dll、analyzer-mecab.xmlなどのファイルを使用します。JapaneseAnalyzer.dllには、日本語の文字列をトークンに分解する日本語アナライザであるJapaneseAnalyzerクラスが含まれています。
■形態素解析ツール「MeCab」のインストール
日本語アナライザでは、日本語のテキスト処理にMeCabという形態素解析エンジンを使用します。MeCabのサイトから、「Binary package for MS-Windows」をダウンロードします(ファイルは「mecab-0.97.exe」)。
ダウンロードしたファイルを実行すると、インストーラが起動します。インストール時に指定する特殊な項目はありませんが、途中で辞書の作成をUTF-8で行うか、Shift-JISで行うか選択します。ここではShift-JISを選択します。なおインストール後に辞書を再構築することも可能です。
■MeCab.Net(参考)
なお、筆者が移植した日本語アナライザでは、MeCabの呼び出しに、「MeCab.NET」というライブラリを使用しています(MeCabのライブラリを参照するにはC/C++によるインターフェイスが必要なため、C#によるラッパー・クラスを通してMeCabにアクセスしています)。MeCab.NETのソース・コードなどは「MeCab.NET」からダウンロードできます。
[補足]日本語アナライザについて
日本語アナライザの本体であるJapaneseAnalyzerクラスを使用する際に必要な構成ファイルについて説明しておきます。
JapaneseAnalyzerクラスを使用する場合は、解析処理の設定を記述したXMLファイルをコンストラクタで指定します(analyzer-mecab.xml)。Java版でも同様のファイルが提供されているので、これをほぼそのまま使用しています。このXMLファイルには、形態素解析エンジンのクラス名(<tokenizerClass>要素)、ストップワード(<stop>要素)、品詞情報(<accept>要素)の3つの要素が記述されています。
<tokenizerClass>要素は、トークンの解析に使用する形態素解析エンジンのクラス名が記述されています。実際には、使用するクラス名があらかじめ決まっているのですが(MeCabを使用するかChaSenを使用するかのどちらか。ChaSen(茶筅)は別の形態素解析エンジン)、ベースにしたJavaによる実装を踏襲しています。
2つ目の<stop>要素は、トークンの解析時に無視する単語を指定します。主に英文の冠詞、代名詞などを指定します。日本語をここに指定してもよく、「いう」「する」などがあらかじめ設定されています。
最後の<accept>要素は、Sen Projectで作成された日本語アナライザ独自のものですが、形態素解析から得られた品詞(Part Of Speech)情報を参照して、全文検索の対象とする品詞を限定することで、無駄なトークンがインデックスに登録されないようにします。
品詞の記述はChaSenで用いられている形式で記述されているので、詳細についてはChaSenのドキュメントを参照してください。例えば人名を検索対象としない場合は、「<pos>名詞-固有名詞-人名</pos>」という<pos>要素をコメントアウトすると、人名はインデックスに追加されなくなり、結果的に人名は検索にヒットしなくなります。品詞名については次で紹介するトークンを確認するアプリケーションでも確認できます。
Copyright© Digital Advantage Corp. All Rights Reserved.