全文検索エンジン「Lucene.Net」を使う:連載:VBで実践! 外部コンポーネント活用術(2/3 ページ)
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。
分解されたトークンを確認してみる
まず簡単なプログラムを作成して、日本語の文字列がどのようにトークンに分解されるか確認しておきましょう。
日本語アナライザによるトークンの解析処理が確認できると、検索処理を実装したものの期待する検索結果が得られない場合の対策(アナライザに問題があるのか、辞書に単語を追加するのがよいか、あるいは日本語アナライザが参照する構成ファイルの内容を変更した方がよいのかなど)が容易になります。
ここでは、Visual StudioでWindowsフォーム・アプリケーションのプロジェクトを新規作成します。プロジェクトにはLucene.Net.dllとJapaneseAnalyzer.dllへの参照を追加します。また、mecablib.dllと、日本語アナライザの構成ファイルであるanalyzer-mecab.xmlを、出力先のフォルダ(Bin\Debug)にコピーしておきます。

フォームには、文字列を入力するためのテキストボックスと、解析を開始するボタン、結果を表示するテキストボックスを配置しておきます。次の画面は完成時の画面です。
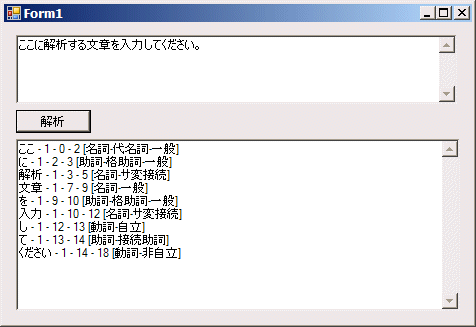
解析結果確認用アプリケーション
日本語アナライザによる解析結果を確認するためのツール。テキストがどのような品詞で分解されているかが表示される。なお、元のテキストに含まれる「する」が表示されていないのは、ストップワードとして「する」が登録されており、解析時に除外されたため。
[解析]ボタンがクリックされたら、JapaneseAnalyzerクラスのオブジェクトを作成し、テキストボックスに入力された内容を、TokenStreamメソッドで解析します。解析した結果は、複数のトークンが格納されたオブジェクトとして返されますので、これに含まれるトークンを順番に表示することで、解析の様子が確認できます。コードは次のようになります。
Imports System.Text
Imports System.IO
Imports Lucene.Net.Index
Imports Lucene.Net.Documents
Imports Lucene.Net.Analysis
Imports Lucene.Net.Analysis.Standard
Imports Lucene.Net.Search
Imports Lucene.Net.QueryParsers
Public Class Form1
Private Sub Form1_Load(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles MyBase.Load
Me.TextBox1.Text = "ここに解析する文章を入力してください。"
End Sub
Private Sub Button1_Click(ByVal sender As System.Object, ByVal e As System.EventArgs) Handles Button1.Click
Dim an As Analyzer
an = New Ja.JapaneseAnalyzer("analyzer-mecab.xml")
Dim reader As New StringReader(Me.TextBox1.Text)
Dim stm As TokenStream = an.TokenStream("", reader)
displayTokens(stm)
End Sub
'解析されたトークンを表示する
Private Sub displayTokens(ByVal stream As TokenStream)
Dim tkn As Lucene.Net.Analysis.Token
Dim s As String = ""
Do
tkn = stream.Next()
If tkn Is Nothing Then
Exit Do
End If
Dim text As String = tkn.TermText()
Dim pos As Integer = tkn.GetPositionIncrement()
Dim start As Integer = tkn.StartOffset()
Dim send As Integer = tkn.EndOffset()
Dim type As String = tkn.Type()
' pos : 直前のトークン位置からの増分(通常は常に1)
' start: トークンの開始位置
' send: トークンの終了位置
' type: 品詞情報
s = s + String.Format("{0} - {1} - {2} - {3} [{4}]", _
text, pos, start, send, type) + vbCrLf
Loop
Me.TextBox2.Text = s
End Sub
End Class
JapaneseAnalyzerクラスは、形態素解析エンジンの辞書を使って解析を行いますので、辞書に登録されていない単語については、意図しない分解が行われる場合があります。
例えばインストール時の辞書では、「定額給付金」と入力した場合は「定額」+「給付」+「金」と分解されます。これは間違った解析ではありませんが、「定額給付金」を1つの単語として扱いたい場合は、あらかじめ形態素解析エンジンが参照する辞書に「定額給付金」を登録しておくことで、意図しないトークンの分解を防ぐことができます。
[コラム]辞書の再構成方法(MeCab)
ここではMeCabで使用する辞書を再構築する方法を簡単に紹介しておきます。MeCabをインストールしたフォルダには「bin\mecab-dict-index.exe」というプログラムがありますので、これを使って辞書を再構築できます。辞書に追加する単語は、同じくMeCabをインストールしたフォルダ内の「dic\ipadic」に、CSV形式のファイルを作成し、ここに単語の情報を記述します。その際のファイル名は何でもよく、拡張子が「.csv」であれば、自動的に辞書に追加されます。
例えば、上記の「定額給付金」を固有名詞として追加する場合は、以下のように記述します。
定額給付金,1288,1288,8010,名詞,固有名詞,一般,*,*,*,定額給付金,テイガクキュウフキン,テイガクキュウフキン
それぞれのフィールドに関する説明はここでは省略しますが、これらはMeCabのドキュメントに記述されていますので、詳細についてはそちらを参照してください。
以上で日本語のテキストがどのようにトークンに分解されるかが確認できましたので、次は実際にインデックスを作成してみます。
JapaneseAnalyzerを使ってインデックスを作成する
まずVisual Studioでコンソール・アプリケーションのプロジェクトを新規作成します。
ここでは本サイトの.NET TIPSのTIPS一覧を全文検索の対象として、インデックスを作成してみます*。ただし、サイト上のWebページのHTMLをそのまま処理するのは大変なので、ここではTIPSのタイトルとURLを含む次のようなXMLファイルをあらかじめ作成してあるものとします。
* 本来であれば.NET TIPSのすべての本文をインデックス作成の対象とすべきですが、この場合にはHTMLから記事の文章を抜き出す処理が必要となり、コードが複雑となるため、本稿の例では記事タイトルのみからインデックスを作成しています。
<?xml version="1.0" encoding="utf-8" ?>
<data>
<tip id="001" href="/fdotnet/dotnettips/001atoi/atoi.html">
文字列を数値に変換するには?
</tip>
<tip id="002" href="/fdotnet/dotnettips/002csc/csc.html">
C#のソース・コードを実行するには?
</tip>
<tip id="003" href="/fdotnet/dotnettips/003screen/screen.html">
ディスプレイの解像度を取得するには?
</tip>
…… 以下省略 ……
</data>
<tip>要素には、.NET TIPSの識別IDであるid属性と、ページのURLを示すhref属性、および記事タイトル名が含まれています。この記事タイトル名を検索するためのインデックスを作成します。
また、先ほどのトークンを確認するアプリケーションと同様、ここでもプロジェクトでLucene.Netを利用するために必要なライブラリへの参照を追加します。参照するDLLファイルはどこに置かれていても問題にはなりません。参照の追加機能でLucene.net.dllとJapaneseAnalyzer.dllへの参照を追加します。さらmecablib.dllとanalyzer-mecab.xmlを実行ファイルの出力先のフォルダにコピーしておきます。
■IndexWriterクラスとDocumentクラスでインデックスを作成
まずインデックスを格納するフォルダを決めます。インデックス・ファイルは単一のファイルではなく複数のファイルで構成されるので、インデックスの作成および参照する際にはフォルダを指定することになります。
インデックスの作成には、IndexWriterクラスを用います。IndexWriterオブジェクトを作成する際に、インデックスを格納するフォルダと、アナライザ(今回はJapaneseAnalyzer)を指定します。これにより、記事タイトルがJapaneseAnalyzerで処理されるようになります。
次にIndexWriterオブジェクトのAddDocumentメソッドを使って、インデックスにDocumentオブジェクトを順番に追加していきます。
Documentオブジェクトは上述したように、検索の単位となるものです。Documentオブジェクトには複数のFieldオブジェクトが追加できますが、ここでは、「title」「url」「tipid」の3つを追加します。検索はtitleフィールドに対してのみ行います。ほかの2つは検索の対象とならないようにします。これらは、Fieldオブジェクトの作成時に、コンストラクタの4つの引数で指定します。
第1引数(name)は、作成するFieldオブジェクトの名前を指定します。これはインデックスの作成後、検索結果からFieldオブジェクトを参照する際に利用します。第2引数(value)はFieldオブジェクトに格納する値です。
第3引数(store)はフィールドの値をインデックスに保持するかどうかを指定します。フィールドの値の保持とは、Fieldオブジェクトに格納する文字列を解析する際に、解析前の文字列をインデックス内に保持するかどうかを指定するものです。検索の対象とはするものの、元になった文字列を検索結果として表示しない場合は、「Field.Store.NO」を指定することでインデックスのサイズを抑えることができます。元の文字列を保持する場合は「Field.Store.YES」を指定します。
4番目のパラメータは、アナライザを使ってトークンに分解するかどうかを指定するものです。「Field.Index.TOKENIZED」を指定した場合は、フィールドの値としてセットした内容がアナライザ(この場合はJapaneseAnalyzer)で解析されます。今回の例では、urlは検索の対象としませんので、「Field.Index.UN_TOKENIZED」を指定します。そうしないと、urlもトークンに分解され「atmarkit」や「fdotnet」といったURLに含まれる文字列も検索されてしまいます。
次に示すインデックスの作成処理では、まずインデックスを格納するフォルダを生成しておき、その後XMLファイルの<tip>要素を順番に取り出しながら、その内容を、Documentクラスを使ってインデックス(IndexWriterオブジェクト)に追加しています。
Imports System.IO
Imports System.Xml
Imports Lucene.Net.Index
Imports Lucene.Net.Documents
Imports Lucene.Net.Analysis.Ja
Module Module1
Sub Main()
' Lucene.Netのインデックスを保存する場所
Dim indexPath As String = "c:\lucene-index"
Dim writer As IndexWriter = Nothing
Dim sBaseUrl As String = "http://www.atmarkit.co.jp"
' インデックスが存在するかどうか
Dim bExist As Boolean = IndexReader.IndexExists(indexPath)
If (bExist) Then
Directory.Delete(indexPath, True)
Directory.CreateDirectory(indexPath)
End If
writer = New IndexWriter(indexPath, _
New JapaneseAnalyzer("analyzer-mecab.xml"), True)
Try
Dim nodeList As XmlNodeList
Dim file As String = "sample.xml"
Dim xmlDoc As XmlDocument = New XmlDataDocument()
xmlDoc.Load(file)
nodeList = xmlDoc.SelectNodes("/data/tip")
Dim nd As XmlNode
' <tip>要素を処理する
For Each nd In nodeList
Dim href As String = nd.Attributes("href").Value
Dim title As String = nd.InnerText
Dim tipID As String = nd.Attributes("id").Value
Console.WriteLine("{0}:{1}", tipID, title)
' Documentオブジェクトの作成
Dim doc As New Document()
' Fieldオブジェクトの作成
Dim fldTitle As New Field("title", title,
Field.Store.YES, Field.Index.TOKENIZED)
Dim fldUrl As New Field("url", sBaseUrl + href,
Field.Store.YES,Field.Index.UN_TOKENIZED)
Dim fldTipID As New Field("tipid", tipID,
Field.Store.YES, Field.Index.UN_TOKENIZED)
' Documentオブジェクトにフィールドを追加
doc.Add(fldTitle)
doc.Add(fldUrl)
doc.Add(fldTipID)
'インデックスにDocumentオブジェクトを追加
writer.AddDocument(doc)
Next
writer.Optimize() ' インデックスを最適化する
Catch ex As Exception
Console.WriteLine(ex.ToString())
Finally
writer.Close()
End Try
End Sub
End Module
■Lukeを使ったインデックスの内容確認
作成したインデックスの確認には、Lukeというツールが利用できます。これはJavaで作成されたツールなので、Javaの実行環境が必要ですが、それ以外は特別な設定は必要ありません。Java版のLuceneで作成したインデックスと、Lucene.Netで作成したインデックスには、互換性があります。
Lukeを起動後、インデックスのあるフォルダを指定すると、インデックスの内容が表示されます。

ここで実際に検索語を入力して検索してみることもできますが、Lukeには日本語アナライザが含まれないので、日本語を検索語として入力した場合は、正しい検索結果が得られない場合があります。
例えば「クリップボード」という単語は、通常「クリップ」+「ボード」というトークンに分解されてインデックスに格納されます。しかしLukeで「クリップボード」と検索語を入力すると「クリップボード」のまま検索を行いますので正しい結果が得られません(正しく検索するには、検索語も日本語アナライザによりトークンに分解する必要があります)。
Copyright© Digital Advantage Corp. All Rights Reserved.