遅いところを直すだけでいいのですか?〜難しいチューニング個所の判断〜:性能エンジニアリング入門(3)(2/2 ページ)
ピーク時になると応答時間が急激に悪化したので、とりあえずCPUとメモリを倍増しておけば大丈夫かな……と勘に頼って対応し、ドツボにはまった経験、ありませんか? この連載では、インフラエンジニアなら最低限理解しておきたい性能問題の基礎を解説します。(編集部)
前提条件が異なると……?
次に、性能ボトルネックの改善が面倒な例を、同じ問題のまま条件を変えて考えてみましょう。前述の条件から変わったのは、APサーバの台数だけです(赤字で表示)。
(1)高負荷とはどの程度の負荷?
→100件/秒とする。
(2)サーバ構成は?
→APサーバ:4コアCPUを2個搭載したサーバを4台。全体で32コア。
DBサーバ:4コアCPUを4機搭載のサーバをHA構成。つまり稼働系は1台で、CPUは16コア。
(3)チューニングによる改善の期待度は?
→AP、DBどちらも50%。つまり、
APサーバ:0.5秒→0.25秒に。
DBサーバ:0.2秒→0.1秒に。
改善前
- APサーバの処理能力上限:(32÷0.5)×0.9≒58件/秒
- DBサーバの処理能力上限:(16÷0.2)×0.9=72件/秒
この条件ではAPサーバの方がボトルネックとなってしまいます。そこでボトルネックを解消するために、APサーバの処理を改善します。
APサーバ側を改善
- APサーバの処理能力上限:(32÷0.25)×0.9≒115件/秒
- DBサーバの処理能力上限:(16÷0.2)×0.9=72件/秒
APサーバのボトルネックは、十分とまではいえないものの改善されましたが、代わりにDBサーバ側がボトルネックとなります。
このケースでは最初からAPサーバ、DBサーバ両方の処理能力上限値を計算していますから、次にDBサーバがボトルネックになるのは最初から分かっていることです。けれど、全体の処理能力についての確固たる見通しがないままに負荷テストを実施し、見つかったボトルネックを逐次改善するアプローチをとっていたらどうなるでしょうか。
1回目の負荷テスト:50件/秒くらいでAPサーバがボトルネック
APサーバの改善努力(かなり大変なチューニング)
2回目の負荷テスト:60件/秒くらいで、今度はDBサーバがボトルネックに
DBサーバの改善努力(さらに大変なチューニング、またはサーバ増設?)
3回目の負荷テスト:100件にあと少し届かずにAPサーバが再びボトルネック
となって、2回の性能チューニングと3回の負荷テストを実施しても、まだ性能要件に合格できません。この後でもプロジェクトがまだ余力を残していることを祈るばかりです。
ですから、やみくもに負荷テストとチューニングを繰り返すのではなく、システムそれぞれの構成要素や各サーバ資源などのキャパシティを考慮に入れて、性能要件の達成前にボトルネックとなる可能性のある個所を見定めておく必要があります。
シミュレーションで確かめてみる
この連載の第1回「性能対策、できてますか?」で、性能をシミュレーション技法で評価する手法について少しだけ触れました。今回の練習問題のケースも、この性能シミュレーションで評価してみるとどうなるでしょうか。ちょっと試してみました。前述した手計算の方法の精度の検証や、残された問題点が見えてきます。
この回では性能シミュレーションの詳しい説明は割愛しますが、ソフトウェア上で、サーバ構成とソフトウェア構成を擬似的に組み立てて、想定した負荷が掛かった状態をシミュレーションします。負荷量が変わった時の応答時間の変化を見たり、サーバ構成を変えてみたときの変化を確認することができます。今回使用した性能シミュレータの実行中の画面例を図2に示します。
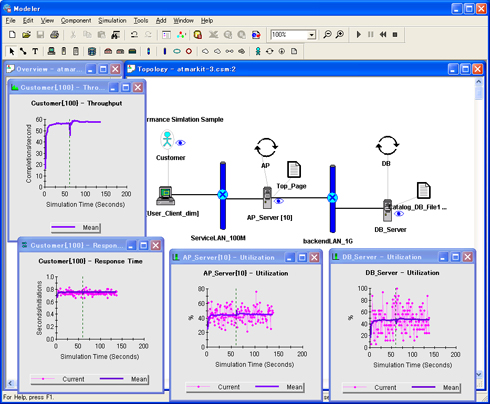
図1で机上試算したのとほぼ同じ条件を、シミュレータ上で構成してみて処理量ごとの応答時間を算出した結果が図3です。点線が図1の机上試算のもので、シミュレータが算出した値が、■、▲、◆でプロットしたものです。
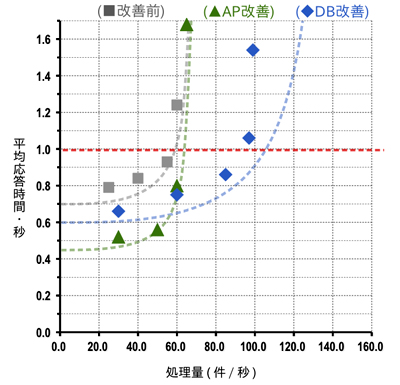
全体的には、机上試算した点線と、シミュレーション結果のプロットは同じような傾向になっていることが分かります。負荷が低い状態では単発実行から極端に悪くなることなく推移しますが、ある資源、つまりボトルネックとなる資源の上限値に近づくと急激に応答時間が悪化し始めます。
机上試算とシミュレーションの結果は似てはいますが、ほとんどの点でシミュレーション結果の方が左上側に出ています。つまり、シミュレーションの方が性能的には悪い結果になっています。
これは、シミュレーションではCPU以外の資源使用量についてもある程度考慮していることと、それぞれのサーバやサーバの資源が多段階に連なって処理されている点を反映できているためと思われます。つまり、現実に起こるであろう現象を、机上試算よりは正しく反映できているはずです。
机上試算した結果では、DBサーバを改善すれば100件/秒の処理までは応答時間1秒に収まってくれるのではないかと推測しましたが、このシミュレーション結果を見る限りは、ちょっと不足しそうです。性能要件の上限負荷を緩めるか、さらなるチューニングをするか、サーバ資源を増設するかの努力が必要になりそうです。
統計量について理解するための参考情報
ここまでに解説した3つの問題は、いずれも紙上で理解できる程度のシンプルなものです。
現実のITシステムは多数の構成要素が組み合わさっており、今回の問題をさらに数倍、数十倍も複雑にしたものになります。そのようなITシステムの性能分析をするためには、高度なソフトウェアツールを用いた方が得策でしょう。
けれども「計算が自動化されたツールを使うので原理までは理解していなくてよい」ということは決してありません。ITシステムの性能がどのような特性を持つのか、なぜそのような特性になるのかを理解しなければ、優秀な道具も使いこなすことはできません。本稿で解説した点は、ツールによって性能分析する際の最低限の基礎になっていると考えて題材を選びました。
さて、基礎の基礎の話はここまでです。次回は、現実にありそうな程度には複雑な構成での性能改善対策を考えます。
【参考情報】
- 谷口俊一・飯田博記・他「アプリケーションの安定稼働を実現する システム基盤の統合ノウハウ」、日経BP、2008年「第2部 システムの安定稼働」に、サーバの資源サイジングを含む性能対策についての解説が豊富に書かれています。
- Chris Loosley・Frank Douglas「データベースチューニング 256の法則 上」、日経BP、1999年
性能エンジニアリングや性能予測の技術について解説した数少ない日本語文献だと思います。 - Cal Henderson「スケーラブルWebサイト」、オライリー・ジャパン、2006年
インターネットWebサイトが対象ですが、性能ボトルネックについて解説する章も設けており、タイトルの通り、性能スケーラビリティを持たせる技術についての解説もあります。 - 「すべてわかる仮想化大全2011」、日経BP、2010年
サーバ仮想化環境での資源使用量やサーバサイジングの考え方が示されています(このシリーズとして「すべてわかる仮想化大全2012」もすでに発行されています)。 - John Allspaw「キャパシティプランニング - リソースを最大限に活かすサイト分析・予測・配置 -」、オライリー・ジャパン、2009年
本番システムの稼働状況監視の例がいろいろ紹介されています。比較的薄い書籍なので読みやすいと思います。
著者プロフィール
TIS株式会社 先端技術センター
溝口則行(みぞぐち のりゆき)
かつて高トラフィックなインターネットサイトの構築・運用に関わったことがきっかけで、性能問題に真面目に取り組む必要性を痛感する。以来、同業のSI'erとの研究会にてITシステムの性能や可用性の検証活動に取り組んでいるが、活動後のビールが楽しみで続けている。勤務先ではオープンソースソフトウェアの活用を推進。TIS先端技術センターでは、採れたての検証成果や知見などをWebサイト http://TECH-SKETCH.jp/ でも発信中。
Copyright © ITmedia, Inc. All Rights Reserved.