実機では測定できない性能を測定?〜性能シミュレーションの概要〜:性能エンジニアリング入門(5)(1/2 ページ)
ピーク時になると応答時間が急激に悪化したので、とりあえずCPUとメモリを倍増しておけば大丈夫かな……と勘に頼って対応し、ドツボにはまった経験、ありませんか? この連載では、インフラエンジニアなら最低限理解しておきたい性能問題の基礎を解説します。(編集部)
はじめに
ITシステムの構築や保守に際し、開発や改修作業がひととおり完了した後に高負荷テストを実施するのは必要なプロセスの1つです。けれど、システム開発をビジネスで請け負っているITのプロが実施すべき性能対策としては、それでは不十分なのではないでしょうか。
ITのプロならば、システムが完成する前に、達成し得る性能値や必要となるサーバリソースを知る方法を確立するべきだと思います。そうしなければ、ITシステム構築はいつまでも「勘」と「度胸」に頼るだけで、定量的なエンジニアリングからはほど遠い状態のままです。この連載記事ではこの点を基本的な問題意識としています。
第1回「性能対策、できてますか?」と、第3回「遅いところを直すだけでいいのですか?」で少しだけ触れた性能シミュレーション技法は、この問題に対する解の1つです。今回と次回の2回に渡って、ITシステムの性能を決定付ける要因を明らかにし、性能問題の解決に向けたシミュレーション技法による性能見積もりの試行的事例について解説します。
ITシステムの性能とは?
設計するという作業には、結果の予測も含まれます。性能品質についても同じです。
ただし予測値には誤差が出たり、時には大きく間違えることもあります。事前に結果のズレを想定して複数のパターンを評価(感度解析)したり、誤差/間違い/想定外の事象が発生したときに、速やかに評価をやり直せるようになっていることが望ましいでしょう。
詳細な設計が進みつつある段階/実装をしている途中/テスト中/運用に入ってから……などなど、性能を再評価したくなるタイミングは、システムライフサイクルの中のすべてのフェイズに存在します。システムライフサイクルの任意のタイミングで性能を評価・再評価するには、性能シミュレーションが最も適しています。
性能方程式 P = f (W, S, H)
性能の予測・評価は簡単ではありません。しかし、どんなデータをそろえてやれば答を得ることができるのか、その因果関係を知ることは問題を解く第一歩です。
上記の見出しの表現は少し奇抜に感じられるかもしれません。しかしこの「性能方程式」は、皆さんが普段、性能に関して感じていることを表現したつもりです。以下に簡単に説明します。
(1)P:(結果として得られる)性能
性能は「次の3つの要因によって決定する」ということを示しています。いい換えると、3つの要因が決まれば性能も決まるのです。逆に、3つの要因のうちの1つでも決まらなければ、性能も決まりません。
(2)W:ワークロード
対象となるITシステムにどれだけの仕事をさせるかを表すものです。例えば、同時にログインする利用者数や、1日に処理しなければいけない業務量などです。
(3)S:ソフトウェアのリソース使用量
稼働させるソフトウェアがサーバやネットワークなどのリソースを消費する量です。搭載するソフトウェアサブシステムの各々について、CPU使用量/メモリ使用量等々の負荷特性があります。この段階(性能に影響を与える要素の大枠を考えている段階)では、アプリケーションプログラムもミドルウェア製品もOSも、すべて含めて考えています。
(4)H:ハードウェアリソース
代表的なものがCPUの処理スピードやCPU数でしょう。その他にメモリやネットワーク、外部記憶装置など、ITシステムのコンピューティングリソースを含みます。
P = f(W, S, H)という表現は奇抜かもしれませんが、このように文章で表現してみると、何も突飛なことはいっていません。
「仕事の量が増えればレスポンスが遅くなる」(W)
「ソフトウェアのロジックが複雑だったりアクセスするデータ量が多いと時間が掛かる」(S)
「ハードウェアを増強すると性能改善が期待できる」(H)
のように表現すれば、違和感はさらになくなるでしょう。
ここでは各要因を1文字のパラメータで表現していますが、それぞれが単独の数値というわけではなく、もっと複雑なものです。ここでは、これらパラメータの中身を1つ1つ取り出す作業は省略しますが、例えば、S(ソフトウェア資源使用量)について例示すると、図1のようなイメージになります。この表全体がSというパラメータを表現しています。

複雑な待ち行列
前述の表現「P = f(W, S, H)」では見えにくいもう1つ重要な特徴に、「性能値は一定ではない(変動する)」という事実があります。同じ負荷(ワークロード)が掛かった状態で、同じ処理をさせた場合でも、応答時間はいつも同じとは限りません。これは、ITシステムの挙動が待ち行列の法則に従った確率過程であることに起因します。
情報処理技術の基礎課程で学ぶように、シンプルな待ち行列の挙動は簡単な計算式で片付きます。ところが現実のITシステムは多数のコンポーネントから構成され、それらのほとんどが待ち行列法則に従った動きをします。
もっと具体的にいうと、CPU、メモリアクセス、ディスクI/O、ネットワークI/Oなどが、すべて独立した待ち行列を構成して確率的挙動をします。現代のITシステムは多数のサーバ群から構成され、広範囲のネットワークで接続されるケースも多いので、さらに複雑な「待ち行列ネットワーク」にを形作っています。
図2は、第4回「性能チューニング個所の検討」の問題で用いたシステム構成ですが、クライアントPCから見て、ネットワーク→Web&APサーバ→DBサーバの順にリクエストを投げて処理を待っている様子を示しています。それぞれの処理時間と待ち時間は常に一定ではなく、処理内容とタイミングによって変動します。
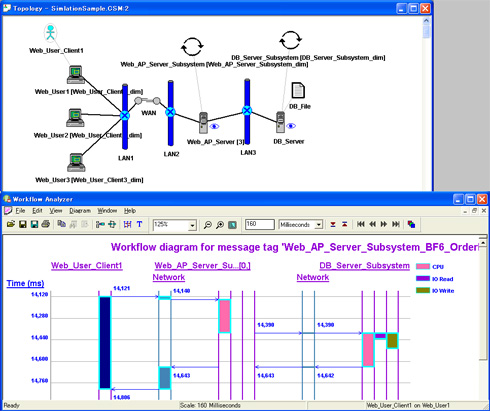 図2 複雑な待ち行列ネットワーク
図2 複雑な待ち行列ネットワークただし誤解してほしくないことがあります。「性能は確率的に変動するから、その動きは分からない」というわけではありません。結果として得られる性能値(P)も、影響因子(W,S,H)も、確率的に変動することを踏まえた上で、評価可能なものです。
性能問題に取り組むために、待ち行列理論の公式を暗記したり、その数値計算ができたりする必要はありません。しかし、待ち行列がどのような挙動を示すのかを理解しておくことと、「平均値」「標準偏差」「パーセンタイル値」などの確率・統計の基本的な考え方は理解しておくことは必要不可欠となります。
シミュレーション技法による性能評価の方法
前のセクションでは、ITシステムの性能がどのように決まってくるのかを概念的に説明しましたが、その性能値を具体的に評価する方法の1つがシミュレーションの方法です。ただし前述のように、現実のITシステムは手計算で性能を評価できるほど単純ではないため、この手法を実施するにはシミュレーションツールを使用します。
第1段階:測定(可能な場合)
実際に稼働するシステムからデータを採取可能な場合には、実現可能な範囲で測定します。測定データの利用目的は次の2点です。
(a)性能モデル作成に必要な、各機能単位のリソース使用量(性能方程式のS)
これを「性能単価」または「シングルプロファイル」と呼びます。この測定は、可能な限り無風時(他に何の処理も行っていないとき)に、測定する機能単位を1つだけ実行して行います。
(b)性能モデルの妥当性(信頼性)を判断するための比較値
これは、実現可能な範囲で多重化した準高負荷状態を測定します。
第2段階:性能モデル作成
シミュレーションツール上にハードウェアモデルとソフトウェアモデルを構築します。
・ハードウェアモデル
本番環境を構成するサーバ、ストレージ、ネットワーク機器を、内部スペックや台数を含めて実際通りに配置します(性能方程式のH)。
・ソフトウェアモデル
各サーバ上に、測定したシングルプロファイルと同じリソース消費をする機能単位を配置します(S)。ターゲットアプリケーションのすべての機能を対象にできればいいのですが、それは作業量的に困難な場合が多いため、処理パターンや負荷の重さなどから、代表的な機能(画面)をピックアップしてモデル作成する場合が大半です。
第3段階:シミュレーション実行
前項で性能シミュレーションのモデルができ上がりますので、シミュレータ上で想定ワークロード(W)を掛け、疑似実行します。シミュレータが各機能単位のレスポンス時間や全体でのCPUなどの資源使用量を計算してくれます(結果としての性能Pが得られます)。
このシミュレーションでは、最初に実測定できているのと同じ負荷量を実行して、シミュレーション結果と実測定結果がほぼ等しいことで、性能モデルの妥当性を確認します。その際、確認ポイント(比較するワークロードの種類)を複数パターン用意した方が、正確な性能モデルにできます。
第4段階:分析&改善案検討
シミュレーションで得た予測値が期待よりも悪いものであった場合などには、性能改善策を見付けたくなるはずです。そこで、シミュレーション結果の中の個々のサーバのリソース使用量や、レスポンス時間中の比率が大きい機能単位を見つけ出して、改善策を検討します。
ただし、これはあくまでも性能改善の“可能性の抽出”であって、実際にそのような改善策が実装可能かどうかは別途検討する必要があります。
第5段階:再シミュレーション
前項で抽出した改善策によって性能がどのように変化するかを、性能モデルの修正→再シミュレーションによって確認します。多数のサーバなどのコンポーネントから構成されるシステムでは、ある個所の変更がどのように結果として現れるかは自明とは言えないため、シミュレーションによって結果を予測するのが良策です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。