性能対策、できてますか?:性能エンジニアリング入門(1)(1/2 ページ)
ピーク時になると応答時間が急激に悪化したので、とりあえずCPUとメモリを倍増しておけば大丈夫かな……と勘に頼って対応し、ドツボにはまった経験、ありませんか? この連載では、インフラエンジニアなら最低限理解しておきたい性能問題の基礎を解説します。(編集部)
古くて新しい「性能問題」
ITシステムの性能問題は昔からのテーマです。その基礎はほとんど変わっていないにも関わらず、多くのITエンジニアが十分には理解できていないのではないかと危惧しています。
現代のITシステムは多数の構成要素から成り立っており、性能問題の解決は相当にやっかいな難問になってきているのが実状です。そのような状況であるからこそ、基礎をしっかりと理解して臨むことが必要であると感じています。
私たちは、この高度化したITシステムの性能問題を解決したいと考え、高負荷テスト、性能データ分析、シミュレーション技法による性能事前評価などに取り組んできました。しかし、それらの高度な技術を有効に活用するためには、単にツールの使い方を習得するだけでは不十分だと身をもって感じています。
性能問題への対処は、ほとんどのITエンジニアにとって避けては通れない課題です。この連載を通じて、多くのITエンジニア仲間たちに、性能問題の基礎を理解していただきたいと考えています。
勘に頼ると失敗する
高負荷になったときの性能は、直感に反することがあります。100÷50=2のような単純計算にはならないのです。
例えば、次のようなケースがありました。
単体テストの応答時間を参考にしたら……
本番での応答時間の要件が5秒でした。アプリケーションソフトウェアの開発がほぼ完了して、本番想定のデータを使って単体/単発で測定したところ、応答時間は約3秒ほどでした。
アプリケーションの開発者はこれで「十分に5秒に収まった」と考えていたようですが、残念ながら本番想定負荷ではとても耐えられません。本当は同時200ユーザー程度のアクセスまで期待されていたのですが、負荷テストは、50ユーザーまで負荷を上げる前にシステムが固まってしまって打ち切りになりました。
このケースは、そもそも高負荷時に性能が悪化することを考えていないので「あまりにお粗末」と思われるかもしれません。けれど、これと似たようなケースに遭遇することは意外と多いものです。「開発環境で○秒だったから、本番環境でも悪くても2倍くらいで収まるよね」と、別案件の経験則だけで語るような場合も同じです。
CPUとメモリを倍にすればOK?
業務処理のピーク時間帯に応答時間が急激に悪くなる問題が発生したため、急遽、サーバのCPUとメモリをそれぞれ倍に増設しました。これだけで解決するという確証はなかったようですが、「それでもある程度は改善してくれるんじゃないか」と期待していたようです。
その結果は、CPUもメモリも増設分はまったく使われず、使用率が半分になっただけで、応答時間はほぼ改善されませんでした。
これと似たようなことは、類似案件の前例がある場合にも見られます。「次の案件では処理業務量が多いので、その分、サーバ資源を増やしておけば大丈夫だろう」と安易にサイジングする場合などです。
このように性能問題には難しさがつきまといます。とはいうものの、「計算が成り立たない」のではなく、ちょっと複雑になっただけなのです。
例えば、一口に「高負荷になった」といっても、アプリケーションサーバ(APサーバ)とデータベースサーバ(DBサーバ)の両方ともが同じように遅くなることはありません。システム構成や処理の内容によって異なるはずです。従って、「1秒に納まりそうな気がする」とか、「以前の案件の2倍くらいで見ておこう」と勘だけに頼るのではなくて、工学的な取り組みが必要になるのです。
さて、当初の想定と比べて10倍、100倍というほどの桁違いの品質ギャップが起こり得るのが、性能問題の厄介な特徴です。
性能以外のテーマでは、10倍とか100倍もの差がある豪気なトラブルには、なかなかお目に掛かれません。もしもプロジェクト管理で工数見積もりが10倍違ったらどうでしょう? 想像するだけで恐ろしい状況です。
これに対し性能問題では、例えば「応答時間が見積もりの10倍になった」などという状況に遭遇したことがある方は、少なくないのではないでしょうか。中には「さすがに100倍なんて極端なことはない」と思われるかもしれませんが、いやいや、結構あると思います。
仮に「応答時間の要求が3秒で、そのうちサーバ内の滞留時間が1秒以内が目安」というありがちなパターンを考えてみましょう。ピーク時間帯に100秒超のサーバ内滞留が発生してタイムアウトエラーが頻発するケースに遭遇したことはありませんか? こう考えると、100倍のギャップというのも「ありそうだ」といっていただけるのではないでしょうか。
性能トラブルを招かないために
では、そんな桁違いのトラブルを避けるためには、どんな対策が実行可能でしょうか?
静的積算でしょうか? もちろんやらないよりもずっといいですし、可能ならば実施した方がいい項目の1つです。でも、本番想定の高負荷状態でどんな性能を出せるのか、きちんと答えることができるでしょうか?
この問いに答える最もシンプルな解答は、当たり前のようですが「テストをしましょう」ということです。本番と同程度の高負荷状態を作り出す、いわゆる「負荷テスト」です。
 写真 負荷テストの実施光景(イメージ)
写真 負荷テストの実施光景(イメージ)負荷テストを上手に実行するには、意外と高度なノウハウが必要です。右の写真は、クライアントPCの代わりに負荷を発生させる負荷ジェネレータ用のPCを7台並べて、数百〜千ほどの同時アクセスのテストをしているところです。この規模の負荷テストになると、テストの実施や結果の分析は案外と難しいものです。
さて、負荷テストは対象システムが構築し終わってからでないと実施できません。その前に本番環境での、本番負荷下での性能を見積もることはできないでしょうか?
その解決策の1つが性能シミュレーションです。図1は、負荷を50多重(ここでの多重度は同時アクセスユーザー数と同じ意味ととらえてください)から800多重まで上げたときに、2種類の画面の応答時間が悪化していく様子を、シミュレータが計算したものです。
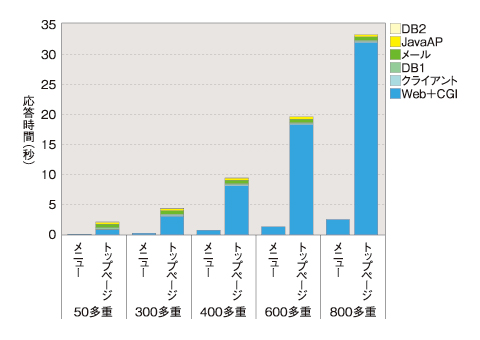 図1 性能シミュレーションの例
図1 性能シミュレーションの例実際には、実システムに合わせてもっと多種類の画面のシミュレーションを行うケースが普通です。
【関連記事】
キャパシティ・プランニングの進め方 ? 上流工程-設計:ITpro
http://itpro.nikkeibp.co.jp/article/COLUMN/20060807/245309/
@IT [FYI] Web負荷テストの押さえるべきポイントとは
http://www.atmarkit.co.jp/ad/empirix/eload/eload01.html
VizJournal―トピックス(ITシステムの未来を可視化する HyPerformix IPS)http://kgt.cybernet.co.jp/viz-journal/contents/ver1/topics/hypx.html
実践的な技術ノウハウに先立つ性能の「基礎」
性能問題解消のための対策は、大きく2つに分類できます。
1つは高負荷時の性能ボトルネックの発見で、これに寄与するのが、前述の2つの対策、構築前の性能シミュレーションと、構築後の負荷テストです。
もう1つが性能改善対策で、たとえばDBチューニングや、アプリケーションプログラム(Javaなど)の性能プロファイリングなどが必要になります。
この連載が対象とするのは、1つ目の、高負荷時の性能ボトルネックを発見する対策技術です。けれど、シミュレーションや負荷テストなどの実践的な技術ノウハウやケーススタディ的な解説は、ひとまず後回しにします。
連載前半では、多くの普通のITエンジニアが「つまらない」と思うかもしれない基礎の基礎の話から始めます。なぜそんな基礎の話から始めようと考えたかというと、私たちの仕事場であるIT業界には、基礎力が足りない「エンジニアもどき」が多すぎると感じているからです。
世の中にはいろんなプロフェッショナルな領域があるとは思いますが、エンジニアが活躍できる領域では、基礎力なき応用力はあり得ません。IT分野も当然その1つです。そこで、性能エンジニアリングの技術話を、思いきり基礎の話から始めてみようと考えた次第です。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ




注目のテーマ

編集部からのお知らせ
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。