UDIDがはらむプライバシー問題:デジタル・アイデンティティ技術最新動向(6)(1/2 ページ)
前回はUDIDに起因するセキュリティの問題について紹介しました。今回は引き続き、UDIDに起因するプライバシーの問題、特に名寄せの問題について述べていきます。
前回は、UDIDに起因するセキュリティの問題について紹介しました。今回は引き続きUDIDに起因するプライバシーの問題について述べていきます。
「プライバシー? 関係ない」とはいえない時代
学生時代にSNSにアップロードした写真が元で就職活動の際に不利な状況になってしまったり、知人しか見ないと思っていたつぶやきが実はWeb全体に公開されていたために自分の生活パターンなどが公にされてしまうなど、SNSに関係するプライバシー侵害事例が増加しています。
一方で、ビッグデータやライフログなどと呼ばれる技術も発展しています。1つ1つには大した価値がないデータでも、それらを大量に集め、こうした技術を用いて解析した結果、個人の趣向などを詳細に知ることも可能になります。ユーザーベースに対して解析結果があまりに詳細な場合には、直接は特定の個人にひも付かないデータからでさえ、個人を特定できてしまうケースもあります。
昨今見られる、行動ターゲティング広告に対するプライバシー面からの批判には、このような、匿名化されているはずのデータが、ある日突然個人を特定できるまでに解析されてしまう可能性への恐怖も多く見受けられます。
これらの事例は、大きく以下の2つのパターンに分けて考えることができます。
2つのプライバシーリスク
なりすましによるプライバシーリスク
前回の記事ではセキュリティの問題としてなりすましについて述べましたが、なりすましはプライバシーリスクにつながることも少なくありません。
特に、SNSにおけるなりすましは、SNS上で意図しない投稿をさせられたり、特定の相手にのみ発信していたはずの情報が公に漏えいしてしまうケースなどのように、容易にプライバシーリスクを想像できるでしょう。サービスの特性上、自分だけでなく自分の知人にも被害が及ぶ可能性が高いことにも注意が必要です。
先日LinkedInやTwitterからパスワードが流出した際には、多くのユーザーが「パスワード漏えいチェックツール」を利用して、自分のパスワードが含まれていないか確認を試みました。このことから判断するに、ユーザー側も、SNSからのパスワード漏えいリスクへの認識は強いようです(なお実際には、「パスワード漏えいチェックツール」自体が悪意を持って提供されている可能性もあるため、安易にそのようなツールを利用することはお勧めしません)。
名寄せによるプライバシーリスク
名寄せとは、「あるサービスを利用しているユーザーAと、別のサービスを利用しているユーザーBが、同一人物であることを特定すること」と理解すると分かりやすいでしょうか。
例えばTwitterの@novとFacebookの@matakeは同一人物ですが、それを特定することが名寄せとなります。名寄せ自体は悪いことではありませんし、現に僕と親しい人たちは、「Twitterの@novとFacebookの@matakeが同一人物である」ことを知っているでしょう。
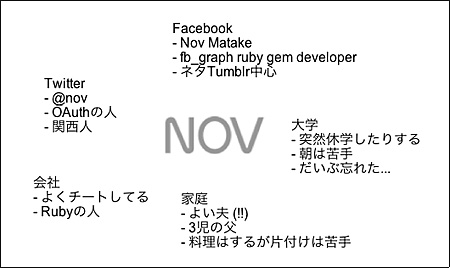
しかし、例えばOpenID Foundation Japanの関係者(人数は多くありません)が書いている記事をよく読んでいるユーザーAと、複数の萌え系ゲームをダウンロードしているユーザーXが同一人物であることを特定された場合、かなり狭い範囲で個人を特定される可能性があります。この場合、ユーザーAとユーザーXが名寄せされることは、プライバシーリスクになり得るでしょう。
最近では、佐賀県武雄市で進行中のカルチュア・コンビニエンス・クラブ社(CCC)への図書館運営委託計画に対して、「たとえ匿名化された情報であっても、人口の少ない地域では、図書館貸出履歴情報を基に個人を特定できてしまう可能性がある」との指摘がありました。このケースをはじめ、名寄せによるプライバシー侵害の問題が現実に議論されるようになってきています。
「プライバシーを守る」ということの意味
「プライバシー保護」と「個人情報保護」の違い
ここで1つ、整理しておきたい論点があります。日本では往々にして、「プライバシー保護」と「個人情報保護」が混同されて語られがちです。しかし、これらは本来、全く違うものです。
さらにいえば、「個人情報」自体についても、「名前などで本人と結び付かなければ個人情報ではない」というような誤った考え方が流布しています。しかし本来「個人情報」とは、個人にまつわるさまざまな情報のことを指します。名前が分かるかどうかは関係ありません。

「個人情報保護」とは、こうした、個人にまつわるさまざまな情報の安全管理処置がどのように行われているか、ということを意味します。つまり、個人情報をいかに「秘する」か、という問題です。
一方プライバシーは、「秘する」こととは直接関係はありません。例えば広辞苑第五版でも「他人の干渉を許さない、各個人の私生活上の自由」と定義されているように、プライバシーとはそもそも、「自らの私的領域への他者の不干渉の権利」、つまり、自分の所有するものや情報を、自分の好きに使う権利なのです。ですから、たとえSNS上にダダ漏れにしていた個人情報であっても、プライバシーの権利で保護されることになります。
まとめると、プライバシーとは、「秘する」ではなく「御する」ことを保証する概念です。こうしたことからしばしば、プライバシーとは「自己情報決定権のことだ」ともいわれます。
繰り返しになりますが、プライバシーは個人情報保護とは全く違う概念です。あえていうならば、個人情報保護とは、プライバシーの権利を守るための一手段に過ぎないのです。
プライバシー保護の11原則
では、プライバシーを保護するためには、どのような要件を確保していくべきなのでしょうか?
プライバシー保護の原則をまとめた資料として、国際標準の「ISO29100:2011 プライバシー原則」があります。ISO29100のプライバシー原則は、以下の11の項目から構成されています。
- 同意と選択
- 合法的目的の明確化
- 収集の制限
- データ最小化
- 利用、保持、開示の制限
- 正確性と品質
- 公開性、透明性、および通知
- 個人の参加とアクセス
- 説明責任
- 情報セキュリティ
- プライバシーコンプライアンス
ここでは1つ1つの項目の細かな説明は省きますが、一例として1番目の原則「同意と選択」について考えてみましょう。
日本ではしばしば、サービス提供側の立場から、個人情報の扱いについて「とりあえず画面に表示する規約に書いてさえあればよい」「むしろあまり明確に説明すると、ユーザーが怖がって同意しないため、長文の利用規約の中に埋めて分からないようにして同意を取るほうがいい」というようなあり方が常態化しています。
しかしこうしたやり方は、上記の「同意と選択」の原則に反します。「同意と選択の原則」では、同意した場合、あるいはしなかった場合にどのようなことが起きるかをユーザーに説明し、理解してもらった上で、個人情報の取得に対する同意を得ることを求めています。ここで重要なポイントは「理解してもらう」ことです。
「同意と選択の原則」は、「意味ある同意」ともいわれます。これはすなわち、サービス提供側は「ユーザーが予想できる範囲のみ」で情報を取り扱うべきだということです。従ってサービス設計時には、常に「この個人情報の使い方は、ユーザーの想定内かどうか」を自問していくことが求められます。
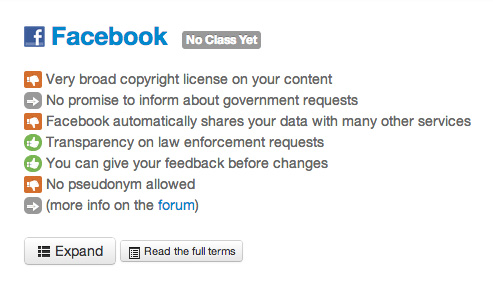
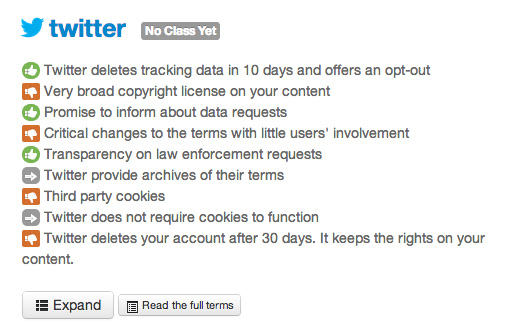
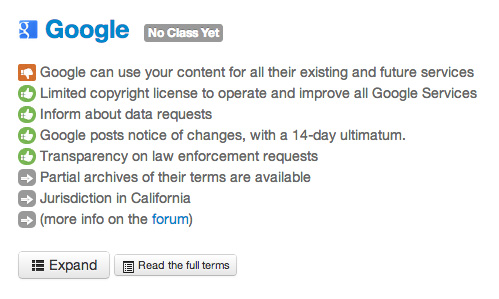
また多くの場合、開発者やサービス提供者と、実際のユーザーとでは、この「想定」にずれが生じます。そういったずれを軽減するために、ユーザーアンケートを取ってみることを検討してもよいでしょう。
このように、ISO29100ではそれぞれの原則に関連して、ステークホルダーが具体的に何をすべきかがまとめられています。関心があれば、いや関心がなくとも、ぜひ一読いただければと思います。
【補足情報】
興味深い動きとして、いろいろなサービスの利用規約を一目で分かりやすく評価する“Terms of Service; Didn't Read”プロジェクトという取り組みも存在します。
http://www.sakimura.org/2012/08/1803/
Copyright © ITmedia, Inc. All Rights Reserved.