Cでポピュラーな脆弱性とバッファオーバーフロー(前編):もいちど知りたい、セキュアコーディングの基本(2)(2/2 ページ)
連載の第2回では、Cアプリの脆弱性として頻繁に耳にする「バッファオーバーフロー」の基礎知識と対策の考え方を復習します。
簡単なコードで動作を確かめてみよう
バッファオーバーフローで何が起こるのか、簡単なコードで実験してみましょう。コード例2は、gets()関数を使って標準入力からデータを読み取り、そのまま出力します。
#include <stdio.h>
int main(int argc, char *argv[]){
int a = 0;
char buf[10];
char *result = gets(buf);
if (result == NULL){
fprintf(stderr, "ERROR\n");
} else {
printf("%x %s\n", a, buf);
}
}
このコードをi386アーキテクチャのLinux環境で実行してみるとこうなりました。
% ./code2
abcdefghi
0 abcdefghi
% ./code2
abcdefghij
0 abcdefghij
% ./code2
abcdefghijk
6b abcdefghijk
% ./code2
abcdefghijkl
6c6b abcdefghijkl
%
入力が9文字までの場合、("abcdefghi")はbufに収まるので問題ありません。しかし入力が10文字になると("abcdefghij")、文字列末尾に付けるnull終端文字がaの領域にはみ出してしまいます。しかしnull終端文字の値は0であり、もともとaに入っていた値も0なので、出力だけからはその影響は分かりません。
次に、11文字入力("abcdefghijk")すると、今度は'k'とnull終端文字がaの領域に書き込まれてしまいます(図3)。実行環境はリトルエンディアンなi386アーキテクチャだったため、'k'が書き込まれたのは整数型4バイトのうちの最下位バイトでした。そのため、'k'の文字コード、0x6bが出力されています。
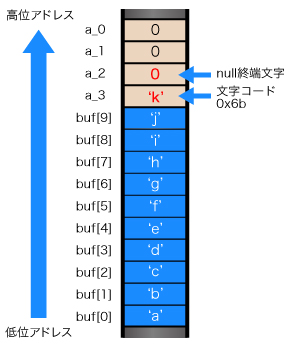
最後に12文字入力("abcdefghijkl")すると、'k'、'l'、null終端文字がaの領域に書き込まれているため、'k'と'l'の文字コードに対応する値が出力されています(図4)。
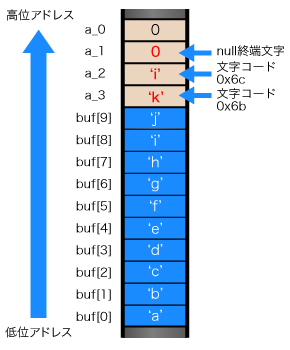
ちなみに、gets()関数の引数bufにNULLを渡し、入力データを読み込ませた場合はどうなるのでしょうか? Cの言語仕様の中のgets()の記述を見ても、何も書いてありません。
このような場合の挙動は、「未定義の動作」("undefined behavior")と呼ばれます。コード例1では*NULL++ = cが実行されるため、実際にはNULLポインタ参照が発生します(NULLポインタ、すなわちアドレス0のメモリに入力データを書き込もうとする)。NULLポインタ参照も未定義の動作であり、言語仕様では何の規定もされていません。我々が普段使うようなPC環境では、ユーザーアプリがNULLポインタ参照を起こした場合にはOSによって強制終了させられることが多いでしょう。
gets()の修正を考える
コード例1はどのように修正すべきでしょうか。問題となったのは以下の前提が成り立たないことでした。
[gets() 実行時の前提条件]
- 引数 buf が指しているバッファは、入力データ(およびその後ろに付けるnull終端文字)を全て収めることのできる大きさであること
標準入力からやってくるデータがどのくらいあるかを事前に知る術はなく、実際に読み込んでみなければ分かりません。この前提条件にはもともと無理があったわけです。
バッファオーバーフローを起こさないようにするためには、読み込むデータ長を制限する必要があります。また、バッファ長は関数の中からは分からないので、引数として受け取りましょう。
char *
gets_fixed(char *buf, size_t size)
{
int c;
char *s;
size_t n = size;
if(n<=0){
return NULL;
}
n--; /* null 終端文字の分を確保 */
while(0<n){
for (s = buf; (c = getchar()) != '\n'; )
if (c == EOF)
if (s == buf){
return (NULL);
} else
break;
else {
*s++ = c;
n--;
}
}
*s = '\0';
return (buf);
}
C言語仕様で規定されている標準ライブラリの中では、この修正版に近い関数として、fgets()関数があります。
char *fgets(char *s, int size, FILE *stream);
fgets()では、第3引数に指定されたFILEポインタから入力データを読み込む、改行コードも含めてコピーする、など、gets()と比べて挙動の違いがあるため、単純に置き換えるだけでは済まないこともあると思いますが、gets()よりはfgets()を使うよう心掛けるべきです。
実際、OpenBSDやLinuxのmanページでは「gets()は使うな」とはっきり書かれています。また、gets()関数を含むコードをコンパイルした場合に警告が出るのを見たことがある方もいることでしょう(注2)。
注2:LLVMを使っているApple OS X環境では実行時に警告メッセージが出ます。--analyze オプションを付けてコンパイルするとコンパイル時にも警告メッセージが出ます。
ちなみに、C89からC99への改訂に伴ってまとめられた「C99 Rationale」を見ると、C99制定当時にもgets()関数を標準ライブラリに入れるかどうか議論があったらしきことがうかがえます。2011年に改定されたC言語仕様の最新版、C11では、とうとうgets()関数は削除されました。
まとめ
今回はCWE/SANS Top 25 Most Dangerous Software Errorsというドキュメントと、バッファオーバーフローの基礎知識を説明し、コード例としてgets()関数の実装を使って、どのように修正すべきか考えてみました。
コピーするデータ長を明示してバッファオーバーフローを防ぐ、という方法は標準ライブラリ関数ではfgets()関数の他にもstrncpy()、strncat()、snprintf()、memcpy()などで使われています。このやり方がgets()のように無制限にデータを読み込むよりも安全なのは確かですが、今度は正しいデータ長を指定することが重要になってくることに注意しましょう。
次回は、バッファオーバーフローの問題があるソフトウェアの例をいくつか見てみたいと思います。
参考文献
5分で絶対に分かるバッファオーバーフロー
http://www.atmarkit.co.jp/fsecurity/special/110buffer/buffer00.html
Wikipedia (日本語版) バッファオーバーラン
http://ja.wikipedia.org/wiki/バッファオーバーラン
Different ways of looking at security bugs
http://software-security.sans.org/blog/2012/06/26/different-ways-of-looking-at-security-bugs
CWE/SANS Top 25 Most Dangerous Software Errors
http://www.sans.org/top25-software-errors/
Rationale for C99, Revision 5.10, April 2003
http://www.open-std.org/JTC1/SC22/WG14/www/C99RationaleV5.10.pdf
Copyright © ITmedia, Inc. All Rights Reserved.