僕たちが分散KVSでファイルシステムを実装した理由:分散KVSを使ったファイルシステム「okuyamaFuse」(1)(3/3 ページ)
データベースで使われるKVSの仕組みをそのままファイルシステムに使ったら? okuyamaの開発者たちがファイルシステムを実装してみたらこうなった。
KVSファイルシステムを開発した経緯
さてここまでファイルシステムの簡単な概要と、実際に記憶装置をどのように扱っているかを説明してきました。そしてなぜ「遅さ」が生まれるかも説明しました。
ここからは本連載の本題であるKVSでのファイルシステムの説明に移りたいと思います。
配列に早くアクセスする=KVSの得意分野!
筆者が記憶装置をKVSにしたファイルシステムを作ろうとしたきっかけは、先ほどのHDDとSSDの違いにあります。
ファイルシステム内部のデータを概念的にとらえると、先ほど説明した配列になります。そして、その配列のそれぞれの要素にアクセスする速度が速ければそれだけファイルシステムとして高速な応答が返せることになります。
このそれぞれの要素にアクセスするという動作はKVSでいうKeyでValueにアクセスする動作に置き換えることができます。そして、この動作はKVSが最も得意とする動作です。
これらのことからKVSでファイルシステムを作れば高速なファイルシステムが作れるのではないかと考えたのです。
okuyamaをどのようにファイルシステムにするか
ここまでで、KVSの持つ1つのデータへのアクセス性能がファイルシステムに向いているという部分までは説明しました。しかし、KVSはデータベースではありますが、ファイルシステムではありません。okuyamaは専用のクライアントもしくはmemcached用のクライアントでアクセスされることを想定して実装されており、そのままWindowsやLinuxのファイルシステムとしてマウントするようなことはできません。
そこでFuseという仕組みを利用します。FuseはLinuxのファイルシステムをユーザー空間で実装するためのフレームワークになります。本来ファイルシステムを実装するにはOSカーネルの深い理解が必要ですが、Fuseを利用することで定められたインターフェイスを実装するのみで、オリジナルのファイルシステムを開発することが可能です。
okuyamaファイルシステムのオーバービューを図6に示しましょう。
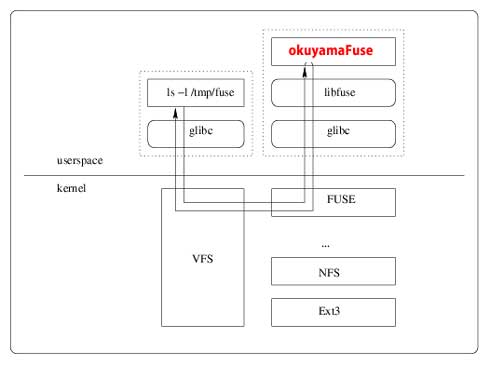
okuyamaは分散型のKVSのため、複数のサーバでクラスタ構成をとることができます。
一般的なファイルシステムに対して並列に大量のアクセスが来た場合、通常1つの物理デバイスでそのアクセスに対応する必要がありますが、KVS型のファイルシステムであればそれらのアクセスを複数台のサーバで処理することが可能になり、同時アクセスに強いファイルシステムが実現します。そして、okuyamaはデータの保存先をメモリ、ディスクどちらにすることも可能なため、複数台のサーバのメモリを保存先として大きなメモリ型のファイルシステムを作ることも可能なのです。
まとめ
今回の連載ではファイルシステムの概要と仕組み、そしてKVSをファイルシステムとした場合の利点をご紹介しました。次回以降は、実際のokuyamaをファイルシステム化するokuyamaFuseの使い方から性能測定の結果などを紹介したいと思います。どうぞお楽しみに。
Copyright © ITmedia, Inc. All Rights Reserved.