見落としがちな整数関連の脆弱性(後編):もいちど知りたい、セキュアコーディングの基本(5)(1/2 ページ)
前回に続き、バグの中でも大きな割合を占める整数の取り扱いに関する脆弱性について解説します。今回取り上げるのは「切り捨て」「符号拡張/ゼロ拡張」についてです。
「Coverity Scan レポート」にみる整数関連のバグ
初めに、脆弱性に関する最近のトピックスとして「Coverity Scanレポート」を紹介したいと思います。
2013年5月7日、静的解析ツールベンダの米Coverityは、2012年度版「Coverity Scan レポート」を公開しました。
Coverityは、自社のコード解析ツールを使ってオープンソースソフトウェア(OSS)を解析し、解析結果を無償で開発者に提供することを通じて、OSSコミュニティのコード品質向上に寄与する「Coverity Scan」プロジェクトを2006年から実施しており、レポートには2012年度に行った解析結果がまとめられています。
OSSのコード品質の現状を垣間みることのできる興味深いレポートですが、特に今回の連載に関連する2つの数字が目に留まりました。
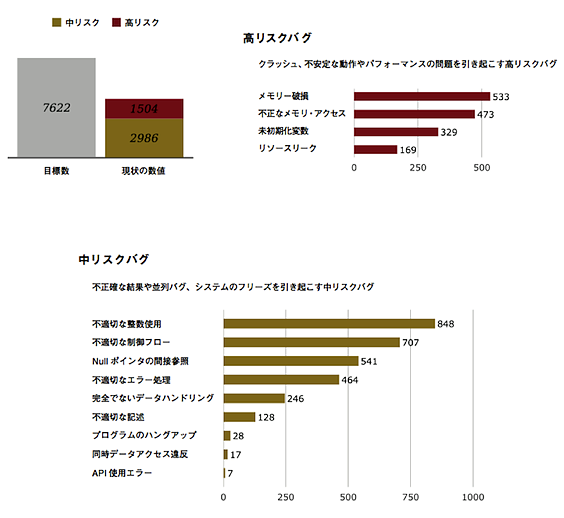
1つ目は、Linux 3.8の品質評価レポートに記されていた整数関連のバグの数です。解析対象約760万行に上るLinux 3.8のソースコード中、「高、中リスクバグ」は4490件検出されています。
中でも最も多かったのが「中リスクバグ」に分類される「不適切な整数使用」の848件です。リスクの比較的高いバグ全体の2割弱が、整数の取り扱いに関連するバグであったということです。これは、前回の記事で紹介したLinuxカーネルにおける脅威の高い脆弱性に占める整数関連の脆弱性の数に符合します。
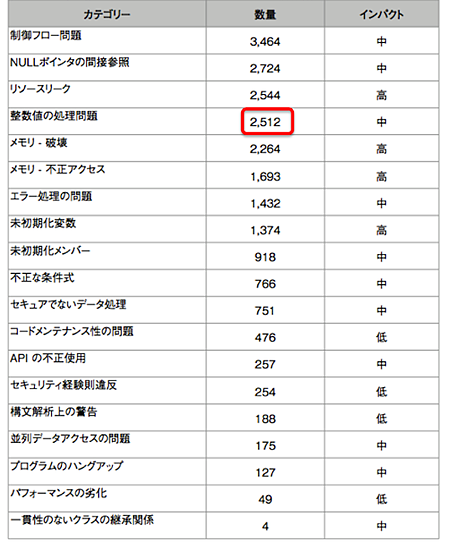
2つ目は、Coverity Scan全体を通じて2012年に修正された、OSSのバグに占める整数関連のバグの割合です。2012年に修正された2万1972件のバグのうち、「整数値の処理問題」に分類されるバグは、全体の1割以上を占める2512件でした。これは4番目に多いバグです。
この数は必ずしも現実を反映しているとは限りません。あくまでツールが検出できたバグの数であり、潜在的に存在するが検知されなかったバグは含まれていません。その点を割り引いても、整数関連のバグは作り込まれやすい、あるいはツールで検知しやすい問題であると言えそうです。
さて、今回は、(3)切り捨て、(4)符号拡張/ゼロ拡張の2つを見ていきたいと思います。
「切り捨て」のおさらい
charやshortといったintより「小さい型」を含む整数演算では、「整数拡張」や「通常の算術型変換」が発生し、「より大きい型」へと暗黙的に型変換されるというルールがC言語にはあります(このあたりの仕組みをおさらいしたい人は、CERT C セキュアコーディングスタンダードのINT02-C「整数変換のルールを理解する」を参照)。
「切り捨て」とは、ビット幅の大きい型を、小さい型に変換するときに発生し得る問題です。切り捨てが発生する場面としては、代入、キャスト、関数の引数の評価などの式が考えられます。ただし、大きい型から小さい型への変換において、必ず切り捨てが発生するわけではありません。大きい型で表現される値が、小さい型で表現できる範囲に収まっていれば、切り捨ては発生しません。従って、変換を行う前に、結果の型に収まる値であるかどうか明示的にチェックすることで、この問題は回避できます。
前置きはこれくらいにして、単純なコード例を見ながら考えてみましょう。
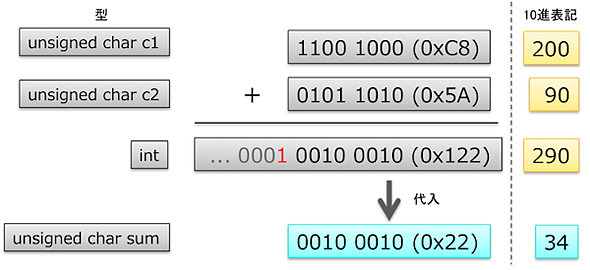
1 unsigned char sum, c1, c2; 2 c1 = 200; 3 c2 = 90; 4 sum = c1 + c2;
このコードにおいて、切り捨て、つまり大きい型から小さい型への変換が行われているのはどこでしょうか?
言語仕様に沿ってコードを解釈するならば、4行目で切り捨てが発生すると考えられます。c1 + c2という加算式を考えるとき、まずチェックすべきはオペランドの型です。c1もc2もintより小さいchar型です。従って、「整数拡張」のルールに従い、それぞれの型をまずint型に変換したた上で、加算演算が行われます。charが8ビットである処理系において、unsigned charで表現できる整数値の範囲は 0〜255(0xFF)ですが、整数拡張が行われるため、c1 + c2の結果の型はint型になり、加算結果の290は表現可能な値となります。そして、加算結果のint型の値をchar型変数sumに代入する際に切り捨てが発生し、sumに代入される値は34になります。
余談ですが、実際のコンパイラの処理は、代入先の変数sumがcharの幅であることから、8ビットのレジスタ同士の加算を8ビット幅で加算するという、切り捨ての発生を見越したコードを生成するので、わざわざ整数拡張のために32ビットレジスタにオペランドを格納するようなことはないでしょう。
それでは整数の切捨てが脆弱性につながった実例を見てみましょう。
OpenSSLの脆弱性(CVE-2012-2110)
OpenSSLは、SSLとTLSを実装したオープンソースのライブラリとしてさまざまな製品に利用されています。OpenSSLには過去に84件の脆弱性が発見されています(osvdbにおける2013年6月1日時点のデータ)。今回はその中から、整数の切り捨てに関する脆弱性を取り上げます。
CVE-2012-2110 として公開されたこの脆弱性は、Google Security Team の Tavis Ormandy氏によって発見されました。脆弱性は0.9.8vで修正されています。今回は脆弱なコードとしてOpenSSL 0.9.8uのソースコードを題材に解説します。
脆弱性は、整数データの不適切な解釈が原因でバッファオーバーフローが発生するというものです。攻撃は、細工したDER形式の証明書データ(X.509証明書やRSA公開鍵など)をOpenSSLに処理させることで行われます。CVEの概要には次のように書かれています。
The asn1_d2i_read_bio function in crypto/asn1/a_d2i_fp.c in OpenSSL before 0.9.8v, 1.0.0 before 1.0.0i, and 1.0.1 before 1.0.1a does not properly interpret integer data, which allows remote attackers to conduct buffer overflow attacks, and cause a denial of service (memory corruption) or possibly have unspecified other impact, via crafted DER data, as demonstrated by an X.509 certificate or an RSA public key.
OpenSSL バージョン 0.9.8vより前、1.0.0iより前の1.0.0、1.0.1aより前の1.0.1において、crypto/asn1/a_d2i_fp.cに含まれるasn1_d2i_read_bio関数は整数データを適切に解釈しません。そのため、遠隔の攻撃者は、X.509証明書やRSA公開鍵などに用いられるDERデータを細工することで、バッファオーバーフロー攻撃やサービス運用妨害(メモリ破壊)、その他の何らかの影響をシステムに及ぼすことが可能です。
脆弱性が作り込まれたcrypto/asn1/a_d2i_fp.cのasn1_d2i_read_bio()関数のコードは次の通りです。
141 static int asn1_d2i_read_bio(BIO *in, BUF_MEM **pb)
142 {
143 BUF_MEM *b;
144 unsigned char *p;
145 int i;
146 int ret = -1;
147 ASN1_const_CTX c;
148 int want = HEADER_SIZE;
149 int eos=0;
(中略)
190 c.inf=ASN1_get_object(&(c.p),&(c.slen),&(c.tag),&(c.xclass),
191 len-off);
(中略)
222 /* suck in c.slen bytes of data */
223 want=(int)c.slen;
224 if (want > (len-off))
225 {
226 want-=(len-off);
227 if (!BUF_MEM_grow_clean(b,len+want))
228 {
229 ASN1err(ASN1_F_ASN1_D2I_READ_BIO,ERR_R_MALLOC_FAILURE);
230 goto err;
231 }
変数wantはint型として宣言され、HEADER_SIZEの値で初期化されています(148行目)。ASN1_const_CTX構造体c.slenの値は、int型にキャストされたのち、wantに代入されています(223行目)。ASN1_const_CTXは/crypto/asn1/asn1.hで以下のようにtypedef宣言されており、メンバー変数slenはlong型として宣言されています(198行目)。この構造体は、ASNのデコーダがデコーダの状態を保持するために利用されます。
190 typedef struct asn1_const_ctx_st
191 {
192 const unsigned char *p; /* work char pointer */
193 int eos; /* end of sequence read for indefinite encoding */
194 int error; /* error code to use when returning an error */
195 int inf; /* constructed if 0x20, indefinite is 0x21 */
196 int tag; /* tag from last 'get object' */
197 int xclass; /* class from last 'get object' */
198 long slen; /* length of last 'get object' */
199 const unsigned char *max; /* largest value of p allowed */
200 const unsigned char *q; /* temporary variable */
201 const unsigned char **pp; /* variable */
202 int line; /* used in error processing */
203 } ASN1_const_CTX;
今回の脆弱性で問題となるのはlong型変数slenの値です。
構造体のメンバー変数であるslenの値は、リスト1の190行目でDER形式の証明書からデータを取得するASN1_get_object()関数と、関数内で呼び出されるasn1_get_length()関数によって設定されています。これらの関数はcrypto/asn1/asn1_lib.cで定義されています。以下に関数のプロトタイプを記します。
int ASN1_get_object(const unsigned char **pp,
long *plength,
int *ptag,
int *pclass,
long omax)
static int asn1_get_length(const unsigned char **pp,
int *inf,
long *rl,
int max)
関数の定義を見ると、長さを表すslenの値は常に符号付きlong型として保持されていることが分かります。
ASN1_get_object()関数により取得されたc.slenの値(long型)は、int型にキャストされ、int型変数wantに格納されます(223行目)。intとlongのサイズが32ビットであるようなILP32データモデルでは、両者で表現できる値の範囲が同じであるため問題ありません。しかし、intが32ビット、longが64ビットであるLP64データモデル(多くのUNIXやLinux OS)においては、キャスト時に切り捨てが発生し、その結果、想定外の値がwantに代入されて、メモリ破壊につながります。
例えばc.slenにINT_MAX + 1 (0x80000000)のように31ビット目が立っている値が設定されている場合、最上位ビットが符号ビットとして解釈され、wantには負の値が代入されることになります。
この脆弱性はどのように修正すればよいでしょうか?
intとlongでビット幅が異なる場合でも切り捨てが発生しないよう、wantをlong型として宣言すればよいでしょう。修正パッチでは、wantをsize_tとして宣言し、代入演算で切り捨てが発生しないように修正しています。
- int want=HEADER_SIZE; + size_t want=HEADER_SIZE; /* suck in c.slen bytes of data */ - want=(int)c.slen; + want=c.slen;
修正パッチだけを見ると、符号付きlongであるc.slenの値を、符号なしのsize_t型に代入しているので、c.slenの値が負の場合に符号エラーが発生するのではないかと推察するかもしれません。c.slenの値を取得するasn1_get_length()関数定義を見ると、slenの値はLONG_MAXより小さいunsigned long型の値であることが保証されているため、修正パッチの内容で問題ないことが分かります。
intとlong が同じサイズであると仮定しない
sizeof(int) == sizeof(long) == sizeof(pointer)であるような典型的な32ビットシステムを前提に書かれたコードでは、intとlongにサイズの差がないがゆえに両者を区別しないで使ってしまい、longの値をintへ代入したり、その逆にintの値をlongに代入するようなコードが書かれることがあります。ILP32データモデルとLP64データモデルの大きな違いを挙げると、
- longとintのサイズが同じではない
- ポインタとintのサイズが同じではない
- ポインタとlongは64ビットであり、アラインメントも64ビットである
- size_tも64ビットの整数型である
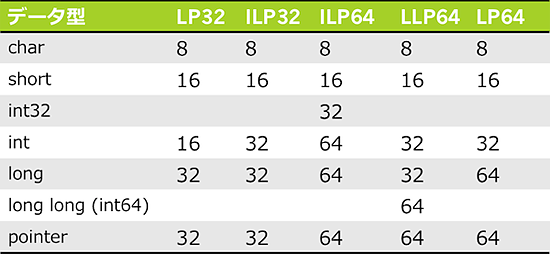
これらの違いが原因で、整数の切り捨てや、その逆に整数拡張が発生したり、構造体のアラインメントに影響が及ぶ可能性があります。
実例を1つだけ紹介しておきます。
セキュリティ関連のブログ「xorl %eax, %eax」でも解説されていたGID/UIDの切り捨てに関するバグです。
Aurelien Jarno 2009-01-04 10:56:47 UTC
uid/gid は32ビット整数を使っているので、64ビットシステムで(2^32)-1よりも大きい値がuid/gidに設定されていると、こんな風にオーバーフローが発生する。
# echo "toto:x:4294967296:4294967296:Fake root:/home/linus:/bin/bash" >> /etc/passwd # id toto uid=0(root) gid=0(root) groupes=0(root)
こんなことが起きる原因は、strtoul()を使ってuid/gidの値をパースしていて、結果をチェックせずにintにキャストしているからだ
出典:http://sourceware.org/bugzilla/show_bug.cgi?id=9706(筆者翻訳)
GNU C Library(glibc-2.17)のソースコードを確認すると、UIDとGIDは確かにunsigned 32ビット型として宣言されています。
typedef unsigned int gid_t; typedef unsigned int uid_t;
そして、strtoul()関数のシグネチャは下記の通り、unsigned longを返します。
unsigned long strtoul(const char *restrict str, char **restrict endptr, int base);
従って、仮に攻撃者が32ビットより大きいUID/GID値を設定していると(上の例では4294967296、つまりUINT_MAX + 1)、切り捨てが発生し、結果が0になってしまうのです。
ブログでは他にも、LP64アーキテクチャで切り捨てが発生する例として、Mozilla Firefox の例を紹介しています。興味のある方はこちらもご一読ください。
【関連リンク】
- Mozilla Firefox/Thunderbird Base64 Integer Overflows(CVE-2009-2463)
Copyright © ITmedia, Inc. All Rights Reserved.