プライバシー保護データマイニング(PPDM)手法の種類、特徴を理解する:匿名化技術とPPDM(2)(2/3 ページ)
現在、プライバシーの侵害なく安全にデータを公開するためにさまざまな手法が考案され始めています。企業が保有するデータには資産価値があるものが多く含まれますが、それらが一部の権限者しか活用できないようでは、商品開発や企画検討、サービス開発に時間がかかることになります。本稿では今後、データを利用する上で理解しておく必要にせまられるであろう、プライバシー保護データマイニングの手法の概要や課題、現状を紹介します。
入力データプライバシー保護技術
入力データプライバシー保護技術の代表的な手法には「匿名化」と「攪乱(かくらん)」があります。
匿名化
前回の記事でも紹介した通り、匿名化とは、「データをひもといていっても、ある特定の個人にデータが戻らないようにすること」を意味します。その手法には「切り落とし」「仮名化」「曖昧化」などがあります。「切り落とし」は特定性のある情報自体を削除するものであり、「仮名化」は別の情報に置き換えることで個人の特定性をなくすものです。「曖昧化」は情報の粒度を粗くすることで特定性や識別性を下げる手法です。
これらの単純な匿名化技術については、すでに複数のデータ処理ソフトウエアで実装され、実用化されています。例えば、オラクルのデータベースソフトウエアのオプション機能の一つに、「Oracle Data Masking Pack」があります。これは、センシティブなデータを不可逆なマスキング(仮名化)データに置き換えることで個人が再特定されるリスクを低減します。ここで言う「センシティブなデータ」とは、クレジットカード番号、電話番号、国民ID(米国のSocial Security Numberや英国のNational Insurance Number)などの情報であり、これらの汎用的なデータに対して共通の仮名化フォーマットのライブラリを提供しています。
しかしながら、このような単純な匿名化手法だけでは十分にリスクを低減できない場合があります。特にデータ量が大きくなった場合、その傾向が強くなることが知られています。このような背景から、匿名化したデータが再特定化されるリスクや属性推定のリスクを評価する手法が求められるようになりました。本稿で解説する「k-匿名性」や「l-多様性」などの指標がそれに該当します。
匿名化(1)k-匿名性の仕組みと実装ソフトウエア
k-匿名性とは、Latanya Sweeney氏(注3)が提案した指標で、個人を特定できる可能性がある情報(準識別子=単体では特定性がないが複数の組み合わせで特定性が生じる情報)がk個以上存在するようにすることで、個人が特定されるリスクを低減します。
例えば、図2のように、準識別子の内容を踏まえて「k=3」に設定した場合、これを満たすように郵便番号の下二桁を削除し、年齢を10歳刻みで曖昧化することで「同じ準識別子を持つデータが3個以上」存在するデータになります。これで「k=3」を満たした匿名化が完了した、と言うことができます。
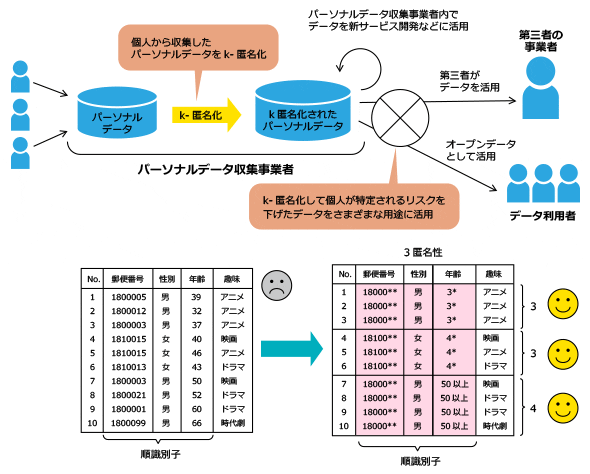
カナダのPrivacy Analytics社はk-匿名性を担保するアルゴリズムを実装する「Privacy Analytics Risk Assessment Tool」(PARAT)を商用ソフトウエアとして提供しています。それ以外にも、無償のオープンソースソフトウエアとして公開されている「Cornell Anonymization Toolkit」(CAT)、「UTD Anonymization ToolBox」(UAT)などがある他、日本では、経済産業省の情報大航海プロジェクト(2007〜2009年度)においてk-匿名性に対応した個人情報匿名化基盤が開発されています。また、NEC、富士通、日立製作所などにおいても、同技術の実用化が進められています。
注3:Latanya Sweeney、k-anonymity: a model for protecting privacy, International Journal on Uncertainty, Fuzziness and Knowledge-based Systems, 10 (5), pp.557-570, 2002.
匿名化(2)l-多様性
k-匿名性の属性推定リスクをさらに低減する手法として、Ashwin Machanavajjhala氏らが提唱した「l-多様性」(注4)があります。l-多様性とは、k-匿名性を担保することを前提とした技術です。k-匿名化だけでは、同じデータがk個あったとしても、その属性が偏っている場合に個人の属性が推定できる可能性が生じます。このリスクを排除するために、l-多様性を評価することでこれを回避できます。例えば、A市に住む40代の男性が100人いて、そのうち、50人ががんを患っている場合、A市の2分の1の男性はがんであることが分かります。l-多様性という指標を用いて、疾病名のようなセンシティブな情報に多様性を持たせることで、個人の属性推定によるプライバシー侵害のリスクを低減することができるのです。
他に、l-多様性の属性推定リスクをさらに低減する手法として、Ninghui Li氏ら(注5)が「t-近似性」と呼ばれる評価手法を提示しています。これについては、ソフトウエアレベルでの実装事例はあるものの、実用レベルで評価手法として用いている事例が見られないので、本稿では割愛しますが、このように現在でも匿名化手法についてはさまざまな研究が進められています。
注4:Ashwin Machanavajjhala、Johannes Gehrke、Daniel Kifer、Muthuramakrishnan Venkitasubramaniam、l-Diversity: Privacy Beyond k-Anonymity, ACM Transactions on Knowledge Discovery from Data (TKDD), 2007.
注5:Ninghui Li、Tiancheng Li、Suresh Venkatasubramanian、t-closeness: Privacy beyond k-anonymity and l-diversity、ICDE 2007、pp.106-115, 2007.
攪乱(かくらん)
「攪乱(かくらん)」とは、個人に関わるデータの属性を事前に定めたルールに基づいて、攪乱(ランダム化)したり、ノイズを加えたりすることで、個人が特定されるリスクを低減する手法です。例えば、複数の属性をランダム化することで、個々のデータが「実在しないデータ」に変換されるため、個人と結び付くことが極めて困難になります。
さらには、攪乱手法と匿名化手法を組み合わせた研究も行われています。NTTが2014年に発表した「Pk-匿名化」という技術は、攪乱の手法を用いながら、生成データの有用性を損なわずにk-匿名性を確保することで、元データの個人が特定されるリスクを低減します(図3)。
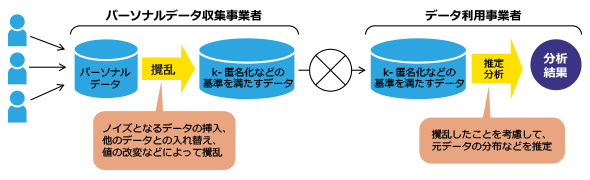
また、ベイズ推定などの技術を組み合わせることで元データに近い分析結果が得られるよう工夫してあります。個人が特定されるリスクを低減しつつ、データの有用性を保てる、ということです。このように攪乱手法に関しては、データの有用性との両立が大きな課題であり、分析技術(推定技術)と合わせた今後の技術展開が期待されます。
Copyright © ITmedia, Inc. All Rights Reserved.