オープンソース化は「必須」? 米国の選定トレンドとPivotalの狙い/Exadata X5の性能を支える技術要素:Database Watch(2015年3月号)(1/2 ページ)
今月はオープンソース化戦略をさらに進めた「Pivotal」と、「Oracle Exadata X5」の進化したポイントをウオッチします。
オープンソース化で成長を続けるPivotalの戦略
2015年3月12日、Pivotalジャパンは最新製品に関する記者発表会を行いました。そこで発表されたのは同社が持つビッグデータ製品群のオープンソース化、ビッグデータ基盤の統合パッケージ「Pivotal Big Data Suite」の最新版の発表および販売開始、エンタープライズ向けHadoopソリューションの推進団体となる「Open Data Platform」の設立、Hadoopディストリビューターである「Hortonworks」との戦略的提携などと盛りだくさんでした。
振り返ると、米Pivotal Software(以降、Pivotal)は次世代プラットフォームに特化したEMCグループの新企業として発足しました。日本法人である「Pivotalジャパン」の設立は2013年7月のことでした。初年度のビジネスは、いわゆるビッグデータ中心でしたが、2014年はクラウドやアジャイル開発の割合が増えてきているとのことです。
2015年1月に米Pivotalが発表したところによると、2014年のソフトウエア売上(後述する「Pivotal Cloud Foundry」の売上)が1年未満で4000万米ドルに迫る勢いとのことです。Pivotalジャパンでは、「Data Lake(データレイク)」と呼ぶHadoop関連ビジネスが2014年は前年比27%の伸びとなるなど、世界だけではなく日本においても着実に成長しているようです。
さて今回、Pivotalはビッグデータ製品群のオープンソース化を発表しました。Pivotalは「全ての『Pivotal Big Data Suite』製品を段階的にオープンソース化する」と話しています。Pivotalでは、まずはインメモリNoSQLデータベース「Pivotal GemFire」とエンタープライズ向けHadoop-SQL互換インターフェースを提供する「Pivotal HAWQ」をオープンソース化するとしています(関連記事)。これらのソフトウエアをオープンソース化した後、分析向けの超並列処理型データベース「Pivotal Greenplum Database」もオープンソース化していくとしています(いずれも時期の明言はなく、現段階ではオープンソース化を発表した段階です)。
Cloud Foundryの経験
オープンソース化についてPivotalは「Cloud Foundry Foundationの成功モデルをビッグデータ領域へ拡大」と説明しています。もともと「Cloud Foundry」はヴイエムウェアがオープンソースのPaaS基盤として開発し、後にPivotalに移管したものです。2014年末にはヒューレット・パッカードやIBMなどのITベンダーが開発コミュニティに加わり「Cloud Foundry Foundation」という推進団体が設立されました。
PivotalはCloud Foundryでのオープンソース活動に積極的に関わりつつ、同時にそれをベースとした自社版ソリューション「Pivotal Cloud Foundry」を提供しています。こちらのビジネスは先述したように初年度から大きな成功を収めています。この勝ちパターンを同社のビッグデータ関連製品でも展開していこうということです。
とはいえ、自社製品をオープンソース化するということは、これまでの開発の成果を手放してしまうようにも思えます。しかし、これも時流なのでしょう。実際、自社で開発していたものをオープンソース化するというのは珍しいことではありません。例えばオープソースで無償のIaaS基盤構築ソフトウエアである「OpenStack」は米航空宇宙局(NASA)が開発していた「NOVA」と米データセンター事業者である「RackSpace」が開発していた「Swift」をオープンソース化したものですし、2014年12月号で紹介した「Cassandra」も元は米ソーシャルネットワーキングサービス運営企業である「Facebook」が開発して、オープンソースソフトウエアプロジェクト支援団体である「Apacheソフトウェア財団」へと寄贈したものです。
無償オープンソースのリレーショナルデータベース(RDB)の一つである「PostgreSQL」に実装された「ストリーミングレプリケーション」も、元は日本のSI企業の一つであるNTTデータが自社製品に実装していた技術をPostgreSQL開発コミュニティへと寄贈したものです(実際には、提供するに当たって、コードを書き直したそうです)。かつて筆者が「なぜオープンソースソフトウエア開発コミュニティに自社技術を提供したのか?」とNTTデータで開発に携わった方に聞いたところ、「会社としては将来の開発や保守にかかるコストを減らせること」と「コミュニティという広い場で育てた方がいいものになる」という考えが主な理由でした。
Pivotalにおいても、「自社だけで作るより、皆で作った方がいい」という考えが浸透して現在のオープンソース化に結び付いているようです。オープンソース化以降の開発体制を維持するために独立した組織を形成し、エコシステムをきちんと整備することも重視されています。
米国で進む、OSS重視のソフトウエア選定のトレンド
Pivotalが自社製品をオープンソース化した理由は他にもあります。Pivotalジャパン技術統括部テクニカルディレクターの仲田聰氏は「いまや米国においてはオープンソースであるかどうかが製品選択の重要な判断基準となっています」と話していました。米国では「先進的な取り組みはオープンソースから始まる」という考えが浸透しているからだそうです。自社製品をオープンソース化するのはよりよいものを作るためだけではなく、米国のビジネスにおいてはオープンソースであることは「必須」とまで変わってきているようです。

技術を企業からコミュニティへ手放しつつ、コミュニティの場で開発に関与し、それをベースによりよいものを自社製品として提供してビジネスで成功する――これがPivotalはじめ昨今のオープンソースビジネスの「勝ちパターン」のようです。Pivotal Cloud Foundryだけではありません。例えば、前述したオープンソースソフトウエアCassandraでは、コミュニティで開発に携わるメンバーを擁している企業「DataStax」がCassandraのエンタープライズ版を提供してビジネスで躍進しています。
「Pivotal Big Data Suite」と「Open Data Platform」の立ち上げ
2015年3月12日の記者会見ではPivotalのビッグデータ製品のオープンソース化と同時に、ビッグデータ基盤の統合パッケージ「Pivotal Big Data Suite」の最新版が発表され、同日から販売開始となりました。Pivotal Cloud Foundryのビッグデータ製品版といえるでしょう。
Pivotal Big Data Suiteは同社のビッグデータ関連製品がセットになっています。データ処理にはストリーミング処理の「Spring XD」、インメモリ処理の「Spark」、Hadoopの「Pivotal HD」があり、分析には「Pivotal Greenplum DB」と「Pivotal HAWQ」、次世代アプリケーションには「Pivotal GemFire」、インメモリデータストアの「Redis」、メッセージングサービスを担う「Rabbit MQ」の他、PaaSプラットフォームのPivotal Cloud Foundryも含まれています。
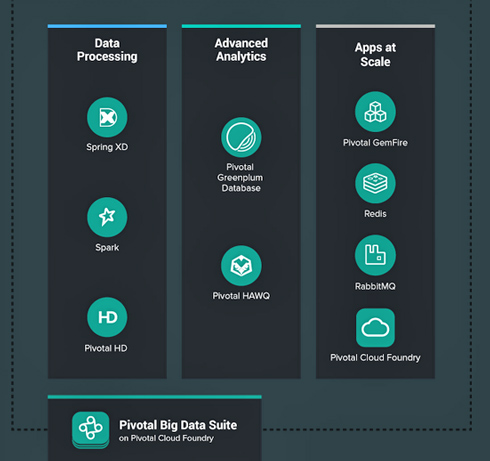
提供はサブスクリプションライセンス、CPUコア数による課金です。契約コア数の範囲であれば、その中で各製品へのコア数割り当てを変えることも可能です(価格は個別見積もり)。
Pivotalでは、これらの発表と同時に、エンタープライズ向けHadoopソリューションの推進団体「Open Data Platform」を設立、Hadoopの普及促進のためにHortonworksとの協業も発表しています。Pivotal製品は多くがHadoop環境を前提に作られており、今やHadoopはPivotalにとって不可欠なものとなっています。
PivotalおよびEMCグループが考える次世代プラットフォームが一つ一つ具現化し、進化しています。
Copyright © ITmedia, Inc. All Rights Reserved.