リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(1)(1/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。初回は全体的なアーキテクチャ、採用技術、開発体制について。
大規模BtoCサービスで求められる検索基盤は、どうあるべきなのか
カスタマー(消費者)が求めるものが日々変わっていく現在において、BtoCの検索基盤はどうあるべきなのでしょうか。
例えば、リクルートで使われている検索基盤の「Qass(Query analyze search system)」は単に全文検索機能を提供するのではなく、以下を軸としています。
- サービスごとに最適化されたクエリの自動変換(Query Rewriter)
- ユーザー行動に基づく検索結果の最適化
- 分析基盤からのフィードバックをシステムに取り込み、検索品質の自動的な向上
これには、リクルートが提供する全てのサービスの根底には「集客を求めるクライアントと商品を求めるカスタマーをつなぐ」というマッチングビジネスモデルがあるからです(図1)。
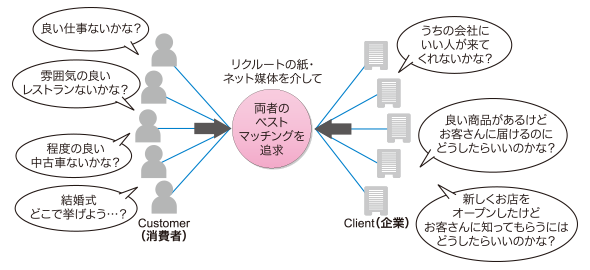
「『クライアント』から“情報や商品を集めて”、『カスタマー』に“購買してもらう(動いてもらう)”」を成立させるためには、下記のことが重要です。検索基盤は、そんなマッチングビジネスの中心的な役割を担う重要領域として、リクルートでは位置付けています。
- クライアントが提供する商材をカスタマーの元に届ける
- カスタマーが容易に目的の商材を見つけられるようにする
- カスタマーとクライアントを新たに巡り合わせ、両者に気付きを届ける
そして外部環境変化を自身の成長モデルに取り込むと同時に、サービスAで得た成果と知見を、サービスBの入力として使う。その反対もしかり。すなわち、リクルートが有する100を超えるサービス間の相互作用によってサービスを成長させる、その源泉となる検索エコシステムを目指しています。それを支えているのがQassなのです。
本連載では、このQassを例にして、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説していきます。
筆者が所属するリクルートテクノロジーズは、IT・ネットマーケティングテクノロジの開発・提供を通してリクルートグループのサービスを支える機能会社です。リクルートテクノロジーズでは、テクノロジをソリューション単位にまとめてグループ各社に提供しており、本連載で紹介するQassも、その一つです。Qassはリクルートテクノロジーズで開発・運用を行っている成長型検索基盤であり、2014年3月より運用しています。
第1回の今回は、リクルート検索領域の変遷とQassのシステム構成やQassが目指しているもの、そして開発体制などの全体概要を紹介します。
リクルートにおける検索基盤の変遷
リクルートでは、もともと商用検索エンジンをベースに検索基盤を構築していましたが、環境変化に早期に対応するためには技術力を内部留保することが必須と考え、外部ソリューションを使い続けるよりもオープンソースソフトウエア(以下、OSS)を流用した自社ソリューションを構築することが重要と判断し、「Apache Solr」(以下、Solr)への移行を行いました。
Solrへの移行は社内技術力の向上、およびコスト面で非常に大きな成果を上げましたが、下記のような課題がありました。
- サジェストなどの周辺機能はサービスごとに独自に実装され、ソフトウエア品質特性にバラつきがある
- 辞書メンテナンスが人力なので手間が掛かる
- Solr単体ではクラスタリング周りが弱く、更新性能、または耐障害性を犠牲にしなければならなかった
- 「SolrCloud」などを併用するとアーキテクチャが複雑になり、運用が大変になる
新検索基盤は、これらの課題を解決すること、既存サービスへの影響を最小限にすること、そして運用に手間が掛からない自己成長型であることをテーマとして構築し、現在リクルートグループのいくつかのサービスに導入、今後の展開を進めています。
Qassの構成
今回構築した新検索基盤では検索のコアエンジンに「Elasticsearch」を採用し、Hadoopによる機械学習を組み合わせることでカスタマーの検索行動に基づいた自己成長型の検索ソリューションを実現し、最適な検索結果に向けて日々改善活動を行っています。
Qassのシステム構成は以下のようになっています。

インフラは自社オンプレとAWS(Amazon Web Services)を組み合わせていて、商品や広告、原稿などの商材に関わる重要なインデックスはオンプレ上に、サジェスト表出用のインデックスはトレンドのリアルタイム反映、負荷分散、レイテンシを考慮してAWS上にストアしています。
また、ElasticsearchにQass独自のプラグインを差し込み、検索クエリを書き換える(Rewrite)などして、アプリケーションの改修なしに検索結果の最適化を図れるようにしています。プラグインはQass独自のクラスローダーによって読み込まれ、Elasticsearchの再起動なしに差し替えられるようにして高頻度のエンハンスを可能にしています。
Elasticsearchを採用したポイントは以下の通りです。
- Solrと同じApache Luceneベースなので既存サービスを新検索基盤に移行しやすい
- クラスター構築が容易なので、高い耐障害性を確保できスケールしやすい
- 洗練された分散モデルにより短スパンでのデータ更新が可能
ElasticsearchとHadoop以外の主要な技術要素として以下のものが挙げられますが、これら以外にもChefやRSpec、ServerSpecなどを使用して、属人性を排除した短サイクルでのリリースを実現しています。詳細については後の連載で紹介します。
- 開発言語
- Java 8
- Go
- Clojure
- 開発、運用環境
- Git
- Jenkins
- Zabbix
- Pacemaker
- 分析環境
- Kibana 4
- Embulk
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。 いまさら聞けないHadoopとテキストマイニング入門
いまさら聞けないHadoopとテキストマイニング入門
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します 検索エンジンの常識をApache Solrで身につける
検索エンジンの常識をApache Solrで身につける
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載 全文検索エンジン「Lucene.Net」を使う
全文検索エンジン「Lucene.Net」を使う
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。- クックパッド、グリー、ぐるなび、CROOZは検索技術をどう使っているのか:検索技術を使うなら知ってないと損する6つのこと
ソーシャルアプリなど大規模Webサービスや企業内システムでも欠かせない検索技術のまとめ - Namazuによる全文検索システムの導入
サーバに集積した情報を再利用するには全文検索システムが必要だ。Namazuのインストールから設定、WordやExcelファイルのサポート方法、効果的な運用方法までを解説する