AWS+オンプレのハイブリッドクラウドな大規模検索基盤ではImmutable InfrastructureとCI/CDをどうやって実践しているのか:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(4)(1/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、継続的インテグレーション/継続的デリバリを実現するのに使っている技術と、その使いどころを紹介する。
継続的インテグレーション/継続的デリバリを実現するのに使っている技術
リクルートの全社検索基盤「Qass」の事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する本連載。
初回の「リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか」では全体的なアーキテクチャ、採用技術、開発体制を紹介しました。
前々回の「ElasticsearchとKuromojiを使った形態素解析とN-Gramによる検索の適合率と再現率の向上」で、検索品質向上の取り組みを紹介。前回の「Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み」ではQassの検索基盤を支えるデータ集計基盤を紹介しました。
今回と次回で、Qassの運用部分に焦点を当てます。
Qassでは、継続的インテグレーション(CI)/継続的デリバリ(CD)を実現するに当たり、以下の技術を採用しています。
第4回となる今回は、QassにおけるCI/CDの事例と、それを実現するソフトウエアを紹介します。
CI/CDを行っているAWS+オンプレのハイブリッドクラウド構成
連載第1回で触れた通り、Qassはセキュリティやレイテンシ、サービスレベルなどの目的に応じて、2種類のインフラ(オンプレミスとAWS)を併用しています。それぞれ重視するものが異なっており、オンプレミスは堅牢性・安定性を、AWSは提供スピードを重視しています。

しかし、オンプレミスにせよAWSにせよ、検索によってサービスの価値を最大限に高めるという意味では目的は同じです。そのためには、いかに素早く価値を提供するか、そして提供し続けるかが重要になります。
さまざまな施策を打ち立て、それらについて検証・開発・リリース・効果確認という一連のサイクルを実行する仕組みをできるだけ少ない手間で行っていくことで、価値を継続して提供し続けることができます。
Qassで利用するAWS環境では、提供と検証のスピードを高めるために、Immutable Infrastructureを採用しています。Qassの提供するサジェスト機能はAWS上で動作しますが、サジェスト用データには頻繁に更新が発生しないことからサーバーを一から作り直しやすく、またインデクシングするデータ量が少ないことから構築が短時間で済むこともあり、Immutable Infrastructureの利用に非常に適しています。
Immutable Infrastructureとは
「Immutable Infrastructure(イミュータブルインフラストラクチャ)」とは、その名の通り「不変なサーバー群」のことを指します。一度サーバーを構築したら、二度とそのサーバーには手を加えず、設定変更の際にはサーバーごとに新しく作り直す提供方法を採ります。言い換えれば、破棄可能なサーバーを作るという意味にもなります。
「Immutable Infrastructure」や、その元になった考え方「ブルーグリーン・デプロイメント」について詳細を知りたい読者は記事「継続的デリバリ/デプロイを実現する手法・ツールまとめ」を参照してください。
この手法のメリットは、過去の状態や設定に縛られないことです。サーバーを長く運用していると、現実問題として急な設定の追加や削除などを行わざるを得ないこともあり、設定がどんどん複雑になってしまい、もともと環境が分からなくなってしまいがちです。Immutable Infrastructureでは、常にサーバー環境を一から構築することになるため、もともとあった環境の再現が容易になります。一度サーバーを構築したら、二度とそのサーバーには手を加えないため、環境設定など常にもともとのクリーンな状態を保つことができます。結果として、スケールアウトも容易に行うことができるようになります。
どのようにしてImmutable Infrastructureを実現しているのか
ここからは、どのようにしてQassでImmutable Infrastructureを実現しているのかについて、少しだけ紹介します。
構築からリリースまでのフロー
Immutable Infrastructureでは、その性質上サーバーを作っては消すことを繰り返すことになるため、サーバーの構築からデプロイ、古いサーバーの破棄までの一連のフローを手間なく高速に(一貫して)行う必要があります。
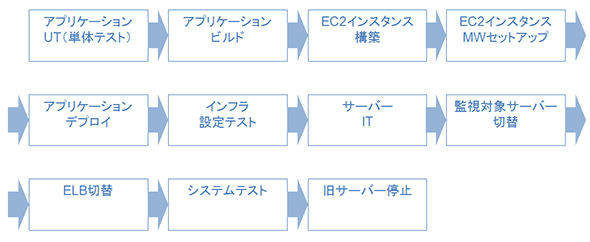
Qassでは、個々のタスクをJenkinsのジョブとして扱い、それらをつなぎ合わせることで実現しています。ジョブ間の連結には、Jenkinsの「Build Flowプラグイン」を利用しています。このプラグインを利用することで、ジョブをパラレルに実行したり、複数のジョブを待ち受けて(合流して)後続ジョブを実行したりすることも可能になり、複雑なビルドフローを構成する場合に便利です。
オンプレミスの環境ではサーバー自体の構築と破棄は行っておらず、同一サーバーを繰り返し利用していますが、基本的に同一サーバーに対して同様のビルドフローを実行しています。
構築とテストを高速に繰り返す
「Immutable Infrastructureでは、さまざまなタスクを一連のフローとして手間なく高速に行う必要がある」つまり、「自動化されている必要がある」と述べましたが、タスク間の連動だけではなく、それぞれのタスクの中についても自動化が必要になります。構築、テスト、リリースなどの目的の異なるさまざまなタスクを自動化するために、Qassでは以下のようなソフトウエアを利用しています。
【構築】
サーバー(インスタンス)の構築自体は「AWS SDK for Ruby」を利用して自作したスクリプトで実現しています。スクリプトの中で、台数やAWSの情報など、サーバー構築における必要な設定を全て行うイメージです。
サーバーソフトウエアのインストールはChefを利用しています。Chefについては後述します。
【テスト】
目的に応じて複数のプロダクトを使い分けています。
- Serverspec:インフラの設定が正常に行われ、正しく稼働しているかをチェックする。設定ファイルの正当性をチェックするためのチェック値はChefから自動的に生成される
- Rspec:意図した検索結果、検索順序が得られているかをテスト
- infrataster:Elasticsearchに対してデータのbulkを行った際、最終的に正しくbulkされているかをテスト
【リリース】
構築と同じくAWS SDK for Rubyを利用したスクリプトによってほぼ行われていますが、監視に関わる部分はZabbixのAPIを利用して監視対象ホストの切り替えを行っています(監視の仕組みについては次回紹介します)。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 継続的インテグレーションを始めるための基礎知識
継続的インテグレーションを始めるための基礎知識
大規模開発とCIの関係、CI製品/サービス7選、選定の3つのポイント、Jenkins導入で解決した問題点などを解説する 継続的デリバリ/デプロイを実現する手法・ツールまとめ
継続的デリバリ/デプロイを実現する手法・ツールまとめ
バージョン管理や継続的インテグレーションとも密接に関わる継続的デリバリ/デプロイメントの概要や主なツール、経緯、実践事例を紹介。実践手法として「ブルーグリーン・デプロイメント」「Immutable Infrastructure」が注目だ。 24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
大規模プッシュ通知基盤について、「Pusna-RS」の実装事例を基にアーキテクチャや運用を解説する連載。今回は、Pusna-RSの運用面や発生した課題について、使用している技術やツール「AWS Elastic Beanstalk」「Jenkins」「Amazon CloudWatch」「GrowthForecast」「fluentd」「Elasticsearch」「Kibana」などの説明を交えながら紹介します。 いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。 絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
多くの企業にとって“クラウドファースト”がキーワードとなっている今、クラウドを「適切に」活用する能力はSIerやIT部門のエンジニアにとって必須の技能となっている。今回はビジネス要請にアジャイルに応える「クラウドファースト時代のシステムインテグレーション」に必要な要素技術を解説する。