ElasticsearchとKuromojiを使った形態素解析とN-Gramによる検索の適合率と再現率の向上:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(2)(1/3 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、テンプレートを利用したインデックス生成など、検索結果の品質を向上させるためのさまざまな取り組みを紹介する。
リクルートの全社検索基盤「Qass」の事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する本連載。初回の前回「リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか」では全体的なアーキテクチャ、採用技術、開発体制について紹介しました。
今回は、「Qass」における検索結果の品質向上における取り組みを紹介します。
検索機能を提供する側の課題
「Elasticsearch」などの検索システムを用いて、大量のドキュメントに対する検索機能を提供する際、最も頭を悩ますのは、下記のような問題でしょう。
どうしてこのドキュメントが、検索結果に現れるのか?
どうしてこのドキュメントが、検索結果に現れないのか?
どうしてこのドキュメントが、他のドキュメントより上位にいるのか?
「カスタマー(消費者)が求めている結果」と「システムが提供する結果」の間に生じるズレが問題となるわけです。今回は、「情報検索」と呼ばれる分野の手法を用いることにより、「Qassでは、このズレをどのように捕らえているのか」、そして「そのズレをどのように解消していくのか」に着目して、検索品質向上の取り組みを紹介します。
形態素解析とN-Gramによる検索の適合率と再現率の両立
適合率と再現率
「カスタマーが求めている結果」と「システムが提供する結果」のズレは、情報検索と呼ばれる分野で「精度」「検索品質」と呼ばれています。
精度が高ければ、ズレは小さく、システムはカスタマーが求めている結果を提供できており、反対に、精度が低ければ、ズレは大きく、システムはカスタマーが求めている結果を提供できていないことになります。
このような精度を定量的に表す方法として、情報検索の分野では、「適合率(Precision)」と「再現率(Recall)」という尺度を用います。
「適合率」とは「システムが返却するドキュメント集合のうち、カスタマーの本来求めていたドキュメントが含まれる割合」です。「再現率」は「カスタマーの本来求めていたドキュメント集合のうち、システムから検索結果として返却されドキュメントが含まれる割合」のことです。
煙に巻いたような日本語になってしまっていますが、とてもシンプルな考え方です。ベン図を用いて適合率と再現率を見ていきましょう。
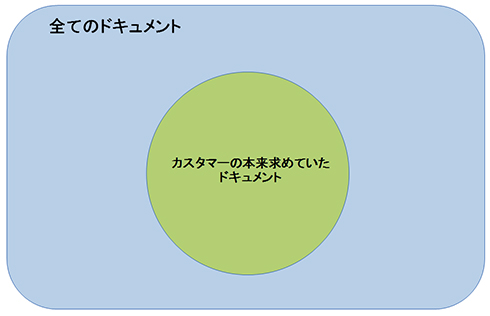
「全てのドキュメント」を外の枠で表し、その中の「カスタマーの本来求めていたドキュメント」が理想的な検索結果を表しています。
注意!「カスタマーの本来求めていたドキュメント」は「理想的なドキュメントの集合」
一つ疑問となるのは、「『カスタマーの本来求めていたドキュメント』とは、どのように分かるのでしょうか?」ということです。
実は、「カスタマーの本来求めていたドキュメント」というのは、「理想的なドキュメントの集合」です。というのも、あらかじめ「カスタマーの本来求めていたドキュメント」を抽出する方法が分かっているならば、それをそのまま検索システムに使ってしまうべきでしょう。
ここでは、あくまで理想的な究極の検索システムがあるとして、「カスタマーの本来求めていたドキュメント」が分かるものと仮定しています。「『カスタマーの本来求めていたドキュメント』とは、どのように分かるのでしょうか?」という問題そのものについては、後ほど「これまで見逃していた2つの問題」の章で再び取り上げます。
それでは、理想的な「カスタマーの本来求めていたドキュメント」に対して、実際のシステムが返却した「検索結果のドキュメント」をこの図にプロットしてみます。
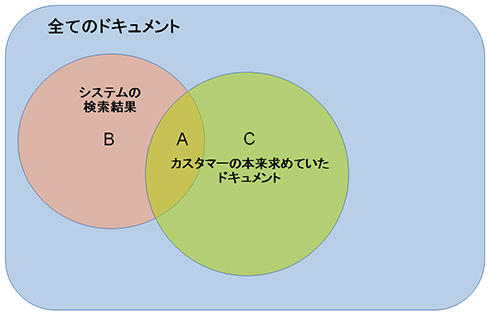
このようにプロットすると、以下のように3つのブロックができることが分かります。
- A:「カスタマーの本来求めていたドキュメント」と「検索結果のドキュメント」が重なる部分
⇒カスタマーの要求とシステムの結果が一致した部分 - B:「検索結果のドキュメント」の中で「カスタマーの本来求めていたドキュメント」に含まれない部分
⇒カスタマーが求めていないのに、検索結果に含まれたノイジーな部分 - C:「カスタマーの本来求めていたドキュメント」の中で「検索結果のドキュメント」に含まれない部分
⇒カスタマーが求めているのに、検索結果に含まれず、取りこぼしてしまった部分
このように表すことで、下記を表すことが可能になります。
- 検索結果が一致しているか? ⇒ Bに相当するノイジーな部分が少ないか?
- 検索結果が網羅されているか? ⇒ Cに相当する取りこぼしが少ないか?
これらを表しているのが、適合率と再現率であり、以下のように定義されます。
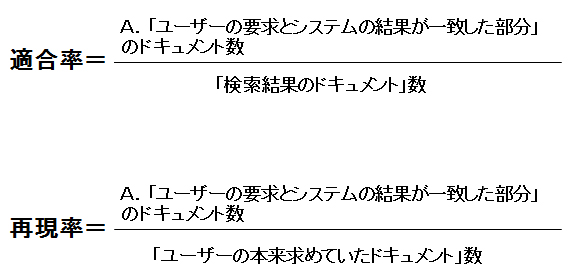
重要なことは、「適合率と再現率は、実際のシステムでは相反する傾向にある」ということです。すなわち、次のような傾向です。
- 適合率を上げれば、再現率は下がる
⇒分母に当たる「検索結果のドキュメント」の数を厳選すれば、適合率は上がります。
⇒その代わり、厳選をミスして、カスタマーの求めるドキュメントを取りこぼす可能性が高くなります。
⇒その結果、再現率は下がります。 - 再現率を上げれば、適合率は下がる
⇒「検索結果のドキュメント」の数を多くすれば多くするほど、A.に該当する分が大きくなり、再現率は上がります。
⇒その代わり、カスタマーの求めていないドキュメントを返却し、検索結果がノイジーになる可能性が高くなります。
⇒その結果、適合率は下がります。
適合率と再現率のバランスを計る「F値」
よって、適合率も再現率もバランスよ良く高いことが、「検索の精度が良い」ということになります。
このようなバランスを計る指標は、「F値(F-measure)」と呼ばれており、適合率と再現率の重み付き調和平均で表されます。
「重み付き」とは、「適合率と再現率を、どれだけの比率で重要視するか?」を表しており、その割合となります。割合ですので、0以上の1以下の値として表し、例えば適合率が70%、再現率が30%ならば、それぞれ「0.7」「0.3」で表されます。
F値は次のように定義されます:
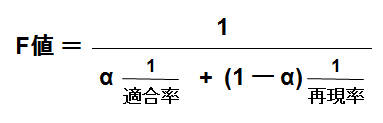
ここで「α」が割合を表しており、先ほどの例で言えば、「α」は適合率の割合であり、「(1-α)」が再現率の割合となります。「単純な適合率と再現率の和の平均」を考えない理由は、バランスを考えるためです。というのも、再現率というものは、検索対象のドキュメントを全て返却すれば、必ず「1」になりますが、極端に適合率の悪い検索システムになります。
反対に、必ず間違いのない1件だけを返却する検索システムの場合、適合率はこちらも「1」になりますが、極端に再現率の悪い検索システムです。極端に一方の値が悪い方、すなわち、小さい値の方が全体に影響するようにするために、「和の平均」ではなく「重み付きの調和平均」を採用するのが一般的です。
形態素解析とN-Gramを使ったインデックスにおける適合率と再現率を向上させる手法の一例
ここからは、実際に検索の精度を上げる手法として、日本語ドキュメントを扱う検索システムを構築する際用いられる「形態素解析」と「N-Gram」を使った、「index」(インデックス)における適合率と再現率を向上させる手法の一例を紹介します。
検索エンジンの概要とインデックス、「形態素解析」と「N-Gram」について知らない方は、下記記事を参照してください。Elasticsearchと同じく「Apache Lucene」をベースに作られた「Apache Solr」の紹介記事ですが、基本的な考え方は同じです。
形態素解析とN-gramによる「index」
欧米言語と比較して、日本語のドキュメントをトークン、もしくは語などの最小単位に分割するタスクは非常に難しい問題です。そして、この分割方法が日本語における検索での精度に大きく関わります。日本語におけるindex構築には、多くの場合に次の2つの方法が採られます。
- 形態素解析による「index」
- N-Gramによる「index」
検索から見ると、「形態素解析」とは、「ドキュメントを構成する最小単位にドキュメントを分割する」ことが主なタスクになります。形態素解析では、主に文法や特定のルールと辞書をベースに分割が行われ、単語の分割に加えて品詞の推定なども含まれるため、日本語として自然な分割結果を得られます。
一方の「N-Gram」は「N」文字単位での分割になり、例えば「2-Gram」では2文字単位での分割となります。
下記サンプルドキュメント「中目黒の桜」を形態素解析とN-Gram(2-Gram)で分割した結果は、以下のようになるでしょう。
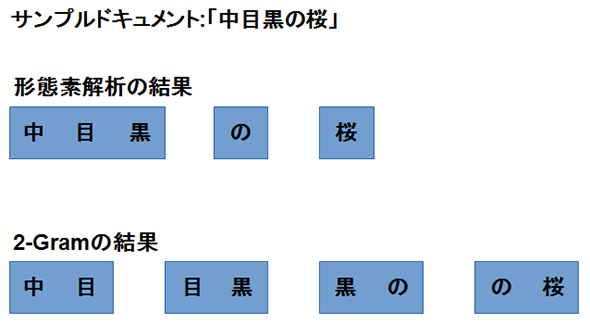
検索は、「ドキュメントの分割された要素」と「検索語であるクエリ」が一致するか否かを判定することになります。
サンプルドキュメント「中目黒の桜」に対して、クエリ「目黒」が検索されたと仮定しましょう。残念ながら、形態素解析のindexではヒットせず、N-Gramのindexのみにヒットします(形態素解析の分割結果には「目黒」は現れず、N-Gramの分割結果には「目黒」が現れます)。
形態素解析とN-Gramの利点と欠点
この例だけでは、あまりにも形態素解析のindexに分がないように見えますが、それぞれに利点と欠点とがあり、それは次のようになるでしょう。
- 形態素解析
- 利点:ノイズが少ない⇒「中目黒」と「目黒」が区別される。
- 欠点:取りこぼしがある⇒「目黒」で検索した人は、「中目黒」も検索結果に含めて欲しかったかもしれない
- N-Gram
- 利点:取りこぼしがない⇒「目黒」で検索した人で、「中目黒」も含めて欲しかった人には良い結果となる
- 欠点:ノイズが多い⇒「目黒」を検索した人は、「中目黒」を検索に含めて欲しくないかもしれない
これまで議論した適合率と再現率に当てはめてみれば、一般的に次のような傾向になります。
| 適合率 | 再現率 | |
|---|---|---|
| 形態素解析 | 高 | 低 |
| N-Gram | 低 | 高 |
残念ながら、先ほど議論したF値を考慮してみても、適合率と再現率の比率を変えてみない限り、一般的にどちらの精度が高いかは甲乙つけがたい状況です。
すなわち、サンプル「中目黒」の例にあるように、『「目黒」で検索した場合、「中目黒」を検索結果に含めるべきか? 否か?』という問いに、一般的な答えを求めるのは非常に難しい問題です。しかし、適合率と再現率の議論でF値を導入したように、これら形態素解析とN-Gramのバランスを取る検索が可能です。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
Hadoopは「難しい・遅い・使えない」? 越えられない壁がある理由と打開策を整理する
ブームだったHadoop。でも実際にはアーリーアダプター以外には、扱いにくくて普及が進まないのが現状だ。その課題に幾つかの解決策が出てきた。転換期を迎えるHadoopをめぐる状況を整理しよう。 いまさら聞けないHadoopとテキストマイニング入門
いまさら聞けないHadoopとテキストマイニング入門
Hadoopとは何かを解説し、実際にHadoopを使って大規模データを対象にしたテキストマイニングを行います。テキストマイニングを行うサンプルプログラムの作成を通じて、Hadoopの使い方や、どのように活用できるのかを解説します 検索エンジンの常識をApache Solrで身につける
検索エンジンの常識をApache Solrで身につける
Hadoopをはじめ、Java言語を使って構築されることが多い「ビッグデータ」処理のためのフレームワーク/ライブラリを紹介しながら、大量データを活用するための技術の常識を身に付けていく連載 全文検索エンジン「Lucene.Net」を使う
全文検索エンジン「Lucene.Net」を使う
サイト構築などで使用できる検索エンジンをVBで活用。日本語アナライザを用いたインデックス作成から検索アプリ作成まで。- クックパッド、グリー、ぐるなび、CROOZは検索技術をどう使っているのか:検索技術を使うなら知ってないと損する6つのこと
ソーシャルアプリなど大規模Webサービスや企業内システムでも欠かせない検索技術のまとめ - Namazuによる全文検索システムの導入
サーバに集積した情報を再利用するには全文検索システムが必要だ。Namazuのインストールから設定、WordやExcelファイルのサポート方法、効果的な運用方法までを解説する