AWS+オンプレのハイブリッドクラウドな大規模検索基盤ではImmutable InfrastructureとCI/CDをどうやって実践しているのか:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(4)(2/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、継続的インテグレーション/継続的デリバリを実現するのに使っている技術と、その使いどころを紹介する。
少ないコストで基盤を運用・管理するために効果的だったChefとconsul
これまでに述べた一般的なImmutable Infrastructureに加えて、Qassでは複数事業サービスを手掛けることで発生する特有の課題を解消するための取り組みを行っています。
Qassは、その性質上、連携する複数の事業サービス(サイト)に応じて、複数種類のサーバーや設定を管理していく必要があります。例えば、「Qass検索サーバー」といっても、それがどのサービス向けなのか、どの設定を適用すればよいのかを管理・把握している必要があるということです。
それぞれをサービスの単位で個別に管理していたのでは、設定情報が膨大になり、変更の際にも手間が掛かります。一方で、むやみに共通化を進めてしまうと、サービスごとの特有の設定に対応しきれなくなり、開発に悪影響を及ぼし、利便性が低下します。そこで、共通的な情報はできるだけ流用するようにし、それでいて拡張性を持たせる仕組みが必要になります。
ここでは、上記目的の中で、特に効果を発揮したツールを紹介します。
chef-solo
Chefとは、現在最も人気のある構成管理ツールの一つです。その中でもスタンドアロンで構成管理を行うものが「chef-solo」です。最近は「chef-zero」など後継のソフトウエアもアナウンスされていますが、Qassでは乗り換えのコストを考慮し、現時点ではchef-soloを利用しています。
Chefの便利な点は、管理体系を柔軟に設計できるところです。例えば、同じミドルウエアを導入する場合でも、ケースによって設定値が異なることがしばしば考えられます。例えば、以下のような場合です:
- 環境の種類:本番、ステージング、開発
- インフラ:オンプレミス、AWS
- ノード種別:Webサーバー、DBサーバー(監視エージェントなど、あらゆるノードに適用する場合)

これらについて、Chefを用いることで、同じ設定手順(レシピ)を用いながら、値だけはそれぞれの環境に合わせて設定することで、設定の柔軟な管理を実現できます。Chefはtemplate機能によって、設定ファイルを定型化可能で、その上でattributeによって設定値を環境・インフラ・ノード種別によって使い分けることができます。
Qassの場合は、さらに事業サービス単位での設定値の使い分けも必要なため、さらに設定が複雑化しますが、この場合でもChefは有効です。Chefの管理体系に合わせて、以下のように設定を使い分けています。
- nodes:実際のサーバーの種類単位
- environments:環境(上記例で言う環境、インフラ、事業サイト単位を組み合わせたもの)
- roles:機能的な役割ごと(検索、監視など)
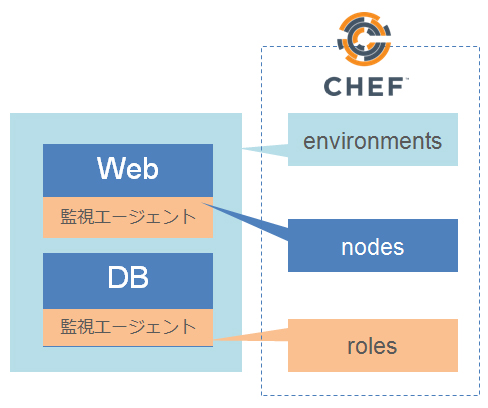
このように、Chefを使いこなすことで、複数の環境に合わせた柔軟な構成管理を行えます。
consul
さまざまな役割を持つサーバーが増えてくると、その役割ごとにサーバーを管理するのが煩雑になってきます。「どのサービス向けのサーバーが何台あって、IPアドレスが何なのか」を把握しないと、そのサーバーに向けてプロビジョニングが実施できないためです。設定ファイルやデータベースなどでサーバー情報を管理していくのも有効ですが、スケールアウト/スケールインのたびに管理情報をメンテナンスするようでは、管理が大変になってしまい本末転倒になってしまいます。

AWSの場合は、EC2インスタンスに対してタグ情報を付与することで、「AWS コマンドラインインターフェイス(CLI)」などによって、その都度問い合わせを行い、タグの単位でサーバーの一覧を把握できます。しかしオンプレミスの場合は、そのまま同じ方法を用いることができません。そこで、解決策として「consul」を利用しています。
consulは、Vagrantなどで有名なHashiCorpが提供するサービス管理用のソフトウエアです。
consulにはさまざまな機能がありますが、Qassでは中でもサービス管理の特徴を活用してサーバー管理を行っています。consulを用いることで、サーバー単位で同一のチェック方法でパスしたサービスIP/ポートを同一グループでまとめて管理できます。例えば、以下のようなサービスチェック設定用のjsonをconsulに登録します。
{
"services": [
{
"id": "elasticsearch",
"address": "192.168.0.1",
"port": 9200,
"name": "elasticsearch",
"tags": ["master"],
"checks": [
{
"http": "http://192.168.0.1:9200/",
"interval": "10s"
}
]
}
]
}
ノード単位に、このような設定ファイルを作成し、それを読み込んだ上でconsulクラスターを形成した場合、以下のように、意味のあるサービス単位でノードの情報を取得できます。以下の例では、Elasticsearchが起動しているノードの一覧を取得しています。
$ curl -s localhost:8500/v1/catalog/service/elasticsearch | jq -r '.[] | .ServiceAddress' 192.168.0.1 192.168.0.2 192.168.0.3
後は、こうして得られたノードの一覧に対してプロビジョニングを行うことで、ノードの情報を都度管理する必要なく目的を達成できます。契機はプロビジョニングだけではありません。グループ単位で一斉に何かを行う場合にも便利です(実際には、「consul exec」コマンドによってサービスにひも付くノードの絞り込みとコマンド発行を同時に行っています)。
加えて、Qassではconsulの持つマルチデータセンター機能を利用して、事業サービスや環境(本番/ステージング/開発)をデータセンターの管理単位とし、その単位でサーバーの一覧を管理する方式を採っています。こうすることで、オンプレミス環境であっても、どの事業サービス向けにどんなノードが何台存在するのかを把握する必要がなくなります。

次回は、監視やバックアップなどについて
今回は、駆け足でしたがCI/CDの観点から、Qass特有の課題を踏まえつつ利用している技術と活用方法を紹介しました。次回は、監視やバックアップなどの運用のもう一つの側面と、今後の展望を紹介します。
筆者紹介
北野 太郎
大手SI企業を経て2013年にリクルートテクノロジーズに入社。リクルートにおけるApache Solrの導入推進、機能改善に従事した後、現在は検索ユニットでのインフラ面での開発に従事。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 継続的インテグレーションを始めるための基礎知識
継続的インテグレーションを始めるための基礎知識
大規模開発とCIの関係、CI製品/サービス7選、選定の3つのポイント、Jenkins導入で解決した問題点などを解説する 継続的デリバリ/デプロイを実現する手法・ツールまとめ
継続的デリバリ/デプロイを実現する手法・ツールまとめ
バージョン管理や継続的インテグレーションとも密接に関わる継続的デリバリ/デプロイメントの概要や主なツール、経緯、実践事例を紹介。実践手法として「ブルーグリーン・デプロイメント」「Immutable Infrastructure」が注目だ。 24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
大規模プッシュ通知基盤について、「Pusna-RS」の実装事例を基にアーキテクチャや運用を解説する連載。今回は、Pusna-RSの運用面や発生した課題について、使用している技術やツール「AWS Elastic Beanstalk」「Jenkins」「Amazon CloudWatch」「GrowthForecast」「fluentd」「Elasticsearch」「Kibana」などの説明を交えながら紹介します。 いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。 絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
多くの企業にとって“クラウドファースト”がキーワードとなっている今、クラウドを「適切に」活用する能力はSIerやIT部門のエンジニアにとって必須の技能となっている。今回はビジネス要請にアジャイルに応える「クラウドファースト時代のシステムインテグレーション」に必要な要素技術を解説する。