儕僋儖乕僩慡幮専嶕婎斦偺傾乕僉僥僋僠儍丄嵦梡媄弍丄奐敪懱惂偼偳偆側偭偰偄傞偺偐丗Elasticsearch亄Hadoop儀乕僗偺戝婯柾専嶕婎斦戝夝朥乮1乯乮1/2 儁乕僕乯
儕僋儖乕僩偺帠椺傪婎偵丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偡傞楢嵹丅弶夞偼慡懱揑側傾乕僉僥僋僠儍丄嵦梡媄弍丄奐敪懱惂偵偮偄偰丅
戝婯柾BtoC僒乕價僗偱媮傔傜傟傞専嶕婎斦偼丄偳偆偁傞傋偒側偺偐
丂僇僗僞儅乕乮徚旓幰乯偑媮傔傞傕偺偑擔乆曄傢偭偰偄偔尰嵼偵偍偄偰丄BtoC偺専嶕婎斦偼偳偆偁傞傋偒側偺偱偟傚偆偐丅
丂椺偊偽丄儕僋儖乕僩偱巊傢傟偰偄傞専嶕婎斦偺乽Qass乮Query analyze search system乯乿偼扨偵慡暥専嶕婡擻傪採嫙偡傞偺偱偼側偔丄埲壓傪幉偲偟偰偄傑偡丅
- 僒乕價僗偛偲偵嵟揔壔偝傟偨僋僄儕偺帺摦曄姺乮Query Rewriter乯
- 儐乕僓乕峴摦偵婎偯偔専嶕寢壥偺嵟揔壔
- 暘愅婎斦偐傜偺僼傿乕僪僶僢僋傪僔僗僥儉偵庢傝崬傒丄専嶕昳幙偺帺摦揑側岦忋
丂偙傟偵偼丄儕僋儖乕僩偑採嫙偡傞慡偰偺僒乕價僗偺崻掙偵偼乽廤媞傪媮傔傞僋儔僀傾儞僩偲彜昳傪媮傔傞僇僗僞儅乕傪偮側偖乿偲偄偆儅僢僠儞僌價僕僱僗儌僨儖偑偁傞偐傜偱偡乮恾1乯丅
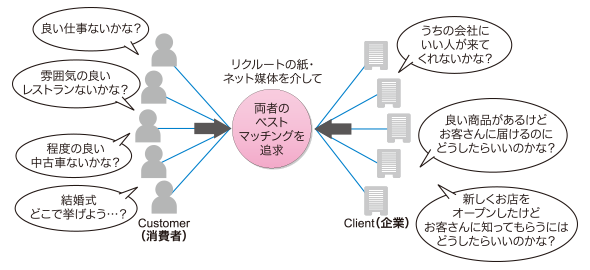 恾1丂儕僋儖乕僩偺價僕僱僗儌僨儖
恾1丂儕僋儖乕僩偺價僕僱僗儌僨儖丂乽亀僋儔僀傾儞僩亁偐傜乬忣曬傗彜昳傪廤傔偰乭丄亀僇僗僞儅乕亁偵乬峸攦偟偰傕傜偆乮摦偄偰傕傜偆乯乭乿傪惉棫偝偣傞偨傔偵偼丄壓婰偺偙偲偑廳梫偱偡丅専嶕婎斦偼丄偦傫側儅僢僠儞僌價僕僱僗偺拞怱揑側栶妱傪扴偆廳梫椞堟偲偟偰丄儕僋儖乕僩偱偼埵抲晅偗偰偄傑偡丅
- 僋儔僀傾儞僩偑採嫙偡傞彜嵽傪僇僗僞儅乕偺尦偵撏偗傞
- 僇僗僞儅乕偑梕堈偵栚揑偺彜嵽傪尒偮偗傜傟傞傛偆偵偡傞
- 僇僗僞儅乕偲僋儔僀傾儞僩傪怴偨偵弰傝崌傢偣丄椉幰偵婥晅偒傪撏偗傞
丂偦偟偰奜晹娐嫬曄壔傪帺恎偺惉挿儌僨儖偵庢傝崬傓偲摨帪偵丄僒乕價僗A偱摼偨惉壥偲抦尒傪丄僒乕價僗B偺擖椡偲偟偰巊偆丅偦偺斀懳傕偟偐傝丅偡側傢偪丄儕僋儖乕僩偑桳偡傞100傪挻偊傞僒乕價僗娫偺憡屳嶌梡偵傛偭偰僒乕價僗傪惉挿偝偣傞丄偦偺尮愹偲側傞専嶕僄僐僔僗僥儉傪栚巜偟偰偄傑偡丅偦傟傪巟偊偰偄傞偺偑Qass側偺偱偡丅
丂杮楢嵹偱偼丄偙偺Qass傪椺偵偟偰丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偟偰偄偒傑偡丅
丂昅幰偑強懏偡傞儕僋儖乕僩僥僋僲儘僕乕僘偼丄IT丒僱僢僩儅乕働僥傿儞僌僥僋僲儘僕偺奐敪丒採嫙傪捠偟偰儕僋儖乕僩僌儖乕僾偺僒乕價僗傪巟偊傞婡擻夛幮偱偡丅儕僋儖乕僩僥僋僲儘僕乕僘偱偼丄僥僋僲儘僕傪僜儕儏乕僔儑儞扨埵偵傑偲傔偰僌儖乕僾奺幮偵採嫙偟偰偍傝丄杮楢嵹偱徯夘偡傞Qass傕丄偦偺堦偮偱偡丅Qass偼儕僋儖乕僩僥僋僲儘僕乕僘偱奐敪丒塣梡傪峴偭偰偄傞惉挿宆専嶕婎斦偱偁傝丄2014擭3寧傛傝塣梡偟偰偄傑偡丅
丂戞1夞偺崱夞偼丄儕僋儖乕僩専嶕椞堟偺曄慗偲Qass偺僔僗僥儉峔惉傗Qass偑栚巜偟偰偄傞傕偺丄偦偟偰奐敪懱惂側偳偺慡懱奣梫傪徯夘偟傑偡丅
儕僋儖乕僩偵偍偗傞専嶕婎斦偺曄慗
丂儕僋儖乕僩偱偼丄傕偲傕偲彜梡専嶕僄儞僕儞傪儀乕僗偵専嶕婎斦傪峔抸偟偰偄傑偟偨偑丄娐嫬曄壔偵憗婜偵懳墳偡傞偨傔偵偼媄弍椡傪撪晹棷曐偡傞偙偲偑昁恵偲峫偊丄奜晹僜儕儏乕僔儑儞傪巊偄懕偗傞傛傝傕僆乕僾儞僜乕僗僜僼僩僂僄傾乮埲壓丄OSS乯傪棳梡偟偨帺幮僜儕儏乕僔儑儞傪峔抸偡傞偙偲偑廳梫偲敾抐偟丄乽Apache Solr乿乮埲壓丄Solr乯傊偺堏峴傪峴偄傑偟偨丅
丂Solr傊偺堏峴偼幮撪媄弍椡偺岦忋丄偍傛傃僐僗僩柺偱旕忢偵戝偒側惉壥傪忋偘傑偟偨偑丄壓婰偺傛偆側壽戣偑偁傝傑偟偨丅
- 僒僕僃僗僩側偳偺廃曈婡擻偼僒乕價僗偛偲偵撈帺偵幚憰偝傟丄僜僼僩僂僄傾昳幙摿惈偵僶儔偮偒偑偁傞
- 帿彂儊儞僥僫儞僗偑恖椡側偺偱庤娫偑妡偐傞
- Solr扨懱偱偼僋儔僗僞儕儞僌廃傝偑庛偔丄峏怴惈擻丄傑偨偼懴忈奞惈傪媇惖偵偟側偗傟偽側傜側偐偭偨
- 乽SolrCloud乿側偳傪暪梡偡傞偲傾乕僉僥僋僠儍偑暋嶨偵側傝丄塣梡偑戝曄偵側傞
丂怴専嶕婎斦偼丄偙傟傜偺壽戣傪夝寛偡傞偙偲丄婛懚僒乕價僗傊偺塭嬁傪嵟彫尷偵偡傞偙偲丄偦偟偰塣梡偵庤娫偑妡偐傜側偄帺屓惉挿宆偱偁傞偙偲傪僥乕儅偲偟偰峔抸偟丄尰嵼儕僋儖乕僩僌儖乕僾偺偄偔偮偐偺僒乕價僗偵摫擖丄崱屻偺揥奐傪恑傔偰偄傑偡丅
Qass偺峔惉
丂崱夞峔抸偟偨怴専嶕婎斦偱偼専嶕偺僐傾僄儞僕儞偵乽Elasticsearch乿傪嵦梡偟丄Hadoop偵傛傞婡夿妛廗傪慻傒崌傢偣傞偙偲偱僇僗僞儅乕偺専嶕峴摦偵婎偯偄偨帺屓惉挿宆偺専嶕僜儕儏乕僔儑儞傪幚尰偟丄嵟揔側専嶕寢壥偵岦偗偰擔乆夵慞妶摦傪峴偭偰偄傑偡丅
丂Qass偺僔僗僥儉峔惉偼埲壓偺傛偆偵側偭偰偄傑偡丅

丂僀儞僼儔偼帺幮僆儞僾儗偲AWS乮Amazon Web Services乯傪慻傒崌傢偣偰偄偰丄彜昳傗峀崘丄尨峞側偳偺彜嵽偵娭傢傞廳梫側僀儞僨僢僋僗偼僆儞僾儗忋偵丄僒僕僃僗僩昞弌梡偺僀儞僨僢僋僗偼僩儗儞僪偺儕傾儖僞僀儉斀塮丄晧壸暘嶶丄儗僀僥儞僔傪峫椂偟偰AWS忋偵僗僩傾偟偰偄傑偡丅
丂傑偨丄Elasticsearch偵Qass撈帺偺僾儔僌僀儞傪嵎偟崬傒丄専嶕僋僄儕傪彂偒姺偊傞乮Rewrite乯側偳偟偰丄傾僾儕働乕僔儑儞偺夵廋側偟偵専嶕寢壥偺嵟揔壔傪恾傟傞傛偆偵偟偰偄傑偡丅僾儔僌僀儞偼Qass撈帺偺僋儔僗儘乕僟乕偵傛偭偰撉傒崬傑傟丄Elasticsearch偺嵞婲摦側偟偵嵎偟懼偊傜傟傞傛偆偵偟偰崅昿搙偺僄儞僴儞僗傪壜擻偵偟偰偄傑偡丅
丂Elasticsearch傪嵦梡偟偨億僀儞僩偼埲壓偺捠傝偱偡丅
- Solr偲摨偠Apache Lucene儀乕僗側偺偱婛懚僒乕價僗傪怴専嶕婎斦偵堏峴偟傗偡偄
- 僋儔僗僞乕峔抸偑梕堈側偺偱丄崅偄懴忈奞惈傪妋曐偱偒僗働乕儖偟傗偡偄
- 愻楙偝傟偨暘嶶儌僨儖偵傛傝抁僗僷儞偱偺僨乕僞峏怴偑壜擻
丂Elasticsearch偲Hadoop埲奜偺庡梫側媄弍梫慺偲偟偰埲壓偺傕偺偑嫇偘傜傟傑偡偑丄偙傟傜埲奜偵傕Chef傗RSpec丄ServerSpec側偳傪巊梡偟偰丄懏恖惈傪攔彍偟偨抁僒僀僋儖偱偺儕儕乕僗傪幚尰偟偰偄傑偡丅徻嵶偵偮偄偰偼屻偺楢嵹偱徯夘偟傑偡丅
- 奐敪尵岅
- Java 8
- Go
- Clojure
- 奐敪丄塣梡娐嫬
- Git
- Jenkins
- Zabbix
- Pacemaker
- 暘愅娐嫬
- Kibana 4
- Embulk
娭楢婰帠
 Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞
Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞
僽乕儉偩偭偨Hadoop丅偱傕幚嵺偵偼傾乕儕乕傾僟僾僞乕埲奜偵偼丄埖偄偵偔偔偰晛媦偑恑傑側偄偺偑尰忬偩丅偦偺壽戣偵婔偮偐偺夝寛嶔偑弌偰偒偨丅揮姺婜傪寎偊傞Hadoop傪傔偖傞忬嫷傪惍棟偟傛偆丅 偄傑偝傜暦偗側偄Hadoop偲僥僉僗僩儅僀僯儞僌擖栧
偄傑偝傜暦偗側偄Hadoop偲僥僉僗僩儅僀僯儞僌擖栧
Hadoop偲偼壗偐傪夝愢偟丄幚嵺偵Hadoop傪巊偭偰戝婯柾僨乕僞傪懳徾偵偟偨僥僉僗僩儅僀僯儞僌傪峴偄傑偡丅僥僉僗僩儅僀僯儞僌傪峴偆僒儞僾儖僾儘僌儔儉偺嶌惉傪捠偠偰丄Hadoop偺巊偄曽傗丄偳偺傛偆偵妶梡偱偒傞偺偐傪夝愢偟傑偡 専嶕僄儞僕儞偺忢幆傪Apache Solr偱恎偵偮偗傞
専嶕僄儞僕儞偺忢幆傪Apache Solr偱恎偵偮偗傞
Hadoop傪偼偠傔丄Java尵岅傪巊偭偰峔抸偝傟傞偙偲偑懡偄乽價僢僌僨乕僞乿張棟偺偨傔偺僼儗乕儉儚乕僋乛儔僀僽儔儕傪徯夘偟側偑傜丄戝検僨乕僞傪妶梡偡傞偨傔偺媄弍偺忢幆傪恎偵晅偗偰偄偔楢嵹 慡暥専嶕僄儞僕儞乽Lucene.Net乿傪巊偆
慡暥専嶕僄儞僕儞乽Lucene.Net乿傪巊偆
僒僀僩峔抸側偳偱巊梡偱偒傞専嶕僄儞僕儞傪VB偱妶梡丅擔杮岅傾僫儔僀僓傪梡偄偨僀儞僨僢僋僗嶌惉偐傜専嶕傾僾儕嶌惉傑偱丅- 僋僢僋僷僢僪丄僌儕乕丄偖傞側傃丄CROOZ偼専嶕媄弍傪偳偆巊偭偰偄傞偺偐丗専嶕媄弍傪巊偆側傜抦偭偰側偄偲懝偡傞6偮偺偙偲
僜乕僔儍儖傾僾儕側偳戝婯柾Web僒乕價僗傗婇嬈撪僔僗僥儉偱傕寚偐偣側偄専嶕媄弍偺傑偲傔 - Namazu偵傛傞慡暥専嶕僔僗僥儉偺摫擖
僒乕僶偵廤愊偟偨忣曬傪嵞棙梡偡傞偵偼慡暥専嶕僔僗僥儉偑昁梫偩丅Namazu偺僀儞僗僩乕儖偐傜愝掕丄Word傗Excel僼傽僀儖偺僒億乕僩曽朄丄岠壥揑側塣梡曽朄傑偱傪夝愢偡傞
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅