Elasticsearch偲Kuromoji傪巊偭偨宍懺慺夝愅偲N-Gram偵傛傞専嶕偺揔崌棪偲嵞尰棪偺岦忋丗Elasticsearch亄Hadoop儀乕僗偺戝婯柾専嶕婎斦戝夝朥乮2乯乮1/3 儁乕僕乯
儕僋儖乕僩偺帠椺傪婎偵丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偡傞楢嵹丅崱夞偼丄僥儞僾儗乕僩傪棙梡偟偨僀儞僨僢僋僗惗惉側偳丄専嶕寢壥偺昳幙傪岦忋偝偣傞偨傔偺偝傑偞傑側庢傝慻傒傪徯夘偡傞丅
丂儕僋儖乕僩偺慡幮専嶕婎斦乽Qass乿偺帠椺傪婎偵丄戝婯柾BtoC僒乕價僗偵媮傔傜傟傞専嶕婎斦偼偳偆峔抸偝傟傞傕偺側偺偐丄偳傫側媄弍偑嵦梡偝傟偰偄傞偺偐丄塣梡偼偳偆側偭偰偄傞偺偐側偳偵偮偄偰夝愢偡傞杮楢嵹丅弶夞偺慜夞乽儕僋儖乕僩慡幮専嶕婎斦偺傾乕僉僥僋僠儍丄嵦梡媄弍丄奐敪懱惂偼偳偆側偭偰偄傞偺偐乿偱偼慡懱揑側傾乕僉僥僋僠儍丄嵦梡媄弍丄奐敪懱惂偵偮偄偰徯夘偟傑偟偨丅
丂崱夞偼丄乽Qass乿偵偍偗傞専嶕寢壥偺昳幙岦忋偵偍偗傞庢傝慻傒傪徯夘偟傑偡丅
専嶕婡擻傪採嫙偡傞懁偺壽戣
丂乽Elasticsearch乿側偳偺専嶕僔僗僥儉傪梡偄偰丄戝検偺僪僉儏儊儞僩偵懳偡傞専嶕婡擻傪採嫙偡傞嵺丄嵟傕摢傪擸傑偡偺偼丄壓婰偺傛偆側栤戣偱偟傚偆丅
偳偆偟偰偙偺僪僉儏儊儞僩偑丄専嶕寢壥偵尰傟傞偺偐丠
偳偆偟偰偙偺僪僉儏儊儞僩偑丄専嶕寢壥偵尰傟側偄偺偐丠
偳偆偟偰偙偺僪僉儏儊儞僩偑丄懠偺僪僉儏儊儞僩傛傝忋埵偵偄傞偺偐丠
丂乽僇僗僞儅乕乮徚旓幰乯偑媮傔偰偄傞寢壥乿偲乽僔僗僥儉偑採嫙偡傞寢壥乿偺娫偵惗偠傞僘儗偑栤戣偲側傞傢偗偱偡丅崱夞偼丄乽忣曬専嶕乿偲屇偽傟傞暘栰偺庤朄傪梡偄傞偙偲偵傛傝丄乽Qass偱偼丄偙偺僘儗傪偳偺傛偆偵曔傜偊偰偄傞偺偐乿丄偦偟偰乽偦偺僘儗傪偳偺傛偆偵夝徚偟偰偄偔偺偐乿偵拝栚偟偰丄専嶕昳幙岦忋偺庢傝慻傒傪徯夘偟傑偡丅
宍懺慺夝愅偲N-Gram偵傛傞専嶕偺揔崌棪偲嵞尰棪偺椉棫
揔崌棪偲嵞尰棪
丂乽僇僗僞儅乕偑媮傔偰偄傞寢壥乿偲乽僔僗僥儉偑採嫙偡傞寢壥乿偺僘儗偼丄忣曬専嶕偲屇偽傟傞暘栰偱乽惛搙乿乽専嶕昳幙乿偲屇偽傟偰偄傑偡丅
丂惛搙偑崅偗傟偽丄僘儗偼彫偝偔丄僔僗僥儉偼僇僗僞儅乕偑媮傔偰偄傞寢壥傪採嫙偱偒偰偍傝丄斀懳偵丄惛搙偑掅偗傟偽丄僘儗偼戝偒偔丄僔僗僥儉偼僇僗僞儅乕偑媮傔偰偄傞寢壥傪採嫙偱偒偰偄側偄偙偲偵側傝傑偡丅
丂偙偺傛偆側惛搙傪掕検揑偵昞偡曽朄偲偟偰丄忣曬専嶕偺暘栰偱偼丄乽揔崌棪乮Precision乯乿偲乽嵞尰棪乮Recall乯乿偲偄偆広搙傪梡偄傑偡丅
丂乽揔崌棪乿偲偼乽僔僗僥儉偑曉媝偡傞僪僉儏儊儞僩廤崌偺偆偪丄僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩偑娷傑傟傞妱崌乿偱偡丅乽嵞尰棪乿偼乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩廤崌偺偆偪丄僔僗僥儉偐傜専嶕寢壥偲偟偰曉媝偝傟僪僉儏儊儞僩偑娷傑傟傞妱崌乿偺偙偲偱偡丅
丂墝偵姫偄偨傛偆側擔杮岅偵側偭偰偟傑偭偰偄傑偡偑丄偲偰傕僔儞僾儖側峫偊曽偱偡丅儀儞恾傪梡偄偰揔崌棪偲嵞尰棪傪尒偰偄偒傑偟傚偆丅
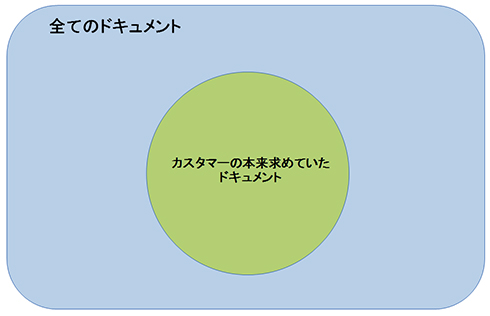 恾1
恾1丂乽慡偰偺僪僉儏儊儞僩乿傪奜偺榞偱昞偟丄偦偺拞偺乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偑棟憐揑側専嶕寢壥傪昞偟偰偄傑偡丅
拲堄両乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偼乽棟憐揑側僪僉儏儊儞僩偺廤崌乿
丂堦偮媈栤偲側傞偺偼丄乽亀僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩亁偲偼丄偳偺傛偆偵暘偐傞偺偱偟傚偆偐丠乿偲偄偆偙偲偱偡丅
丂幚偼丄乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偲偄偆偺偼丄乽棟憐揑側僪僉儏儊儞僩偺廤崌乿偱偡丅偲偄偆偺傕丄偁傜偐偠傔乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿傪拪弌偡傞曽朄偑暘偐偭偰偄傞側傜偽丄偦傟傪偦偺傑傑専嶕僔僗僥儉偵巊偭偰偟傑偆傋偒偱偟傚偆丅
丂偙偙偱偼丄偁偔傑偱棟憐揑側媶嬌偺専嶕僔僗僥儉偑偁傞偲偟偰丄乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偑暘偐傞傕偺偲壖掕偟偰偄傑偡丅乽亀僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩亁偲偼丄偳偺傛偆偵暘偐傞偺偱偟傚偆偐丠乿偲偄偆栤戣偦偺傕偺偵偮偄偰偼丄屻傎偳乽偙傟傑偱尒摝偟偰偄偨2偮偺栤戣乿偺復偱嵞傃庢傝忋偘傑偡丅
丂偦傟偱偼丄棟憐揑側乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偵懳偟偰丄幚嵺偺僔僗僥儉偑曉媝偟偨乽専嶕寢壥偺僪僉儏儊儞僩乿傪偙偺恾偵僾儘僢僩偟偰傒傑偡丅
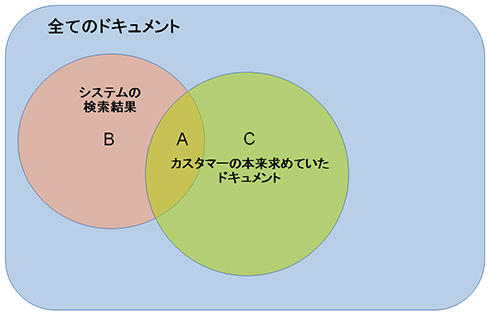 恾2
恾2丂偙偺傛偆偵僾儘僢僩偡傞偲丄埲壓偺傛偆偵3偮偺僽儘僢僋偑偱偒傞偙偲偑暘偐傝傑偡丅
- A丗乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偲乽専嶕寢壥偺僪僉儏儊儞僩乿偑廳側傞晹暘
佀僇僗僞儅乕偺梫媮偲僔僗僥儉偺寢壥偑堦抳偟偨晹暘 - B丗乽専嶕寢壥偺僪僉儏儊儞僩乿偺拞偱乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偵娷傑傟側偄晹暘
佀僇僗僞儅乕偑媮傔偰偄側偄偺偵丄専嶕寢壥偵娷傑傟偨僲僀僕乕側晹暘 - C丗乽僇僗僞儅乕偺杮棃媮傔偰偄偨僪僉儏儊儞僩乿偺拞偱乽専嶕寢壥偺僪僉儏儊儞僩乿偵娷傑傟側偄晹暘
佀僇僗僞儅乕偑媮傔偰偄傞偺偵丄専嶕寢壥偵娷傑傟偢丄庢傝偙傏偟偰偟傑偭偨晹暘
丂偙偺傛偆偵昞偡偙偲偱丄壓婰傪昞偡偙偲偑壜擻偵側傝傑偡丅
- 専嶕寢壥偑堦抳偟偰偄傞偐丠 佀 B偵憡摉偡傞僲僀僕乕側晹暘偑彮側偄偐丠
- 専嶕寢壥偑栐梾偝傟偰偄傞偐丠 佀 C偵憡摉偡傞庢傝偙傏偟偑彮側偄偐丠
丂偙傟傜傪昞偟偰偄傞偺偑丄揔崌棪偲嵞尰棪偱偁傝丄埲壓偺傛偆偵掕媊偝傟傑偡丅
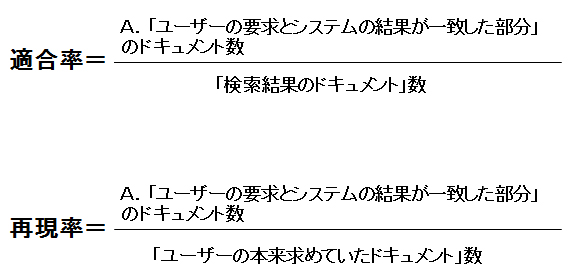 恾3
恾3丂廳梫側偙偲偼丄乽揔崌棪偲嵞尰棪偼丄幚嵺偺僔僗僥儉偱偼憡斀偡傞孹岦偵偁傞乿偲偄偆偙偲偱偡丅偡側傢偪丄師偺傛偆側孹岦偱偡丅
- 揔崌棪傪忋偘傟偽丄嵞尰棪偼壓偑傞
佀暘曣偵摉偨傞乽専嶕寢壥偺僪僉儏儊儞僩乿偺悢傪尩慖偡傟偽丄揔崌棪偼忋偑傝傑偡丅
佀偦偺戙傢傝丄尩慖傪儈僗偟偰丄僇僗僞儅乕偺媮傔傞僪僉儏儊儞僩傪庢傝偙傏偡壜擻惈偑崅偔側傝傑偡丅
佀偦偺寢壥丄嵞尰棪偼壓偑傝傑偡丅 - 嵞尰棪傪忋偘傟偽丄揔崌棪偼壓偑傞
佀乽専嶕寢壥偺僪僉儏儊儞僩乿偺悢傪懡偔偡傟偽懡偔偡傞傎偳丄A.偵奩摉偡傞暘偑戝偒偔側傝丄嵞尰棪偼忋偑傝傑偡丅
佀偦偺戙傢傝丄僇僗僞儅乕偺媮傔偰偄側偄僪僉儏儊儞僩傪曉媝偟丄専嶕寢壥偑僲僀僕乕偵側傞壜擻惈偑崅偔側傝傑偡丅
佀偦偺寢壥丄揔崌棪偼壓偑傝傑偡丅
揔崌棪偲嵞尰棪偺僶儔儞僗傪寁傞乽F抣乿
丂傛偭偰丄揔崌棪傕嵞尰棪傕僶儔儞僗傛椙偔崅偄偙偲偑丄乽専嶕偺惛搙偑椙偄乿偲偄偆偙偲偵側傝傑偡丅
丂偙偺傛偆側僶儔儞僗傪寁傞巜昗偼丄乽F抣乮F-measure乯乿偲屇偽傟偰偍傝丄揔崌棪偲嵞尰棪偺廳傒晅偒挷榓暯嬒偱昞偝傟傑偡丅
丂乽廳傒晅偒乿偲偼丄乽揔崌棪偲嵞尰棪傪丄偳傟偩偗偺斾棪偱廳梫帇偡傞偐丠乿傪昞偟偰偍傝丄偦偺妱崌偲側傝傑偡丅妱崌偱偡偺偱丄0埲忋偺1埲壓偺抣偲偟偰昞偟丄椺偊偽揔崌棪偑70亾丄嵞尰棪偑30亾側傜偽丄偦傟偧傟乽0.7乿乽0.3乿偱昞偝傟傑偡丅
丂F抣偼師偺傛偆偵掕媊偝傟傑偡:
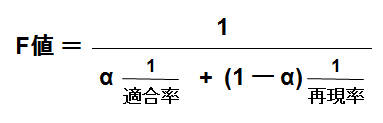 恾4
恾4丂偙偙偱乽兛乿偑妱崌傪昞偟偰偍傝丄愭傎偳偺椺偱尵偊偽丄乽兛乿偼揔崌棪偺妱崌偱偁傝丄乽(1-兛)乿偑嵞尰棪偺妱崌偲側傝傑偡丅乽扨弮側揔崌棪偲嵞尰棪偺榓偺暯嬒乿傪峫偊側偄棟桼偼丄僶儔儞僗傪峫偊傞偨傔偱偡丅偲偄偆偺傕丄嵞尰棪偲偄偆傕偺偼丄専嶕懳徾偺僪僉儏儊儞僩傪慡偰曉媝偡傟偽丄昁偢乽1乿偵側傝傑偡偑丄嬌抂偵揔崌棪偺埆偄専嶕僔僗僥儉偵側傝傑偡丅
丂斀懳偵丄昁偢娫堘偄偺側偄1審偩偗傪曉媝偡傞専嶕僔僗僥儉偺応崌丄揔崌棪偼偙偪傜傕乽1乿偵側傝傑偡偑丄嬌抂偵嵞尰棪偺埆偄専嶕僔僗僥儉偱偡丅嬌抂偵堦曽偺抣偑埆偄曽丄偡側傢偪丄彫偝偄抣偺曽偑慡懱偵塭嬁偡傞傛偆偵偡傞偨傔偵丄乽榓偺暯嬒乿偱偼側偔乽廳傒晅偒偺挷榓暯嬒乿傪嵦梡偡傞偺偑堦斒揑偱偡丅
宍懺慺夝愅偲N-Gram傪巊偭偨僀儞僨僢僋僗偵偍偗傞揔崌棪偲嵞尰棪傪岦忋偝偣傞庤朄偺堦椺
丂偙偙偐傜偼丄幚嵺偵専嶕偺惛搙傪忋偘傞庤朄偲偟偰丄擔杮岅僪僉儏儊儞僩傪埖偆専嶕僔僗僥儉傪峔抸偡傞嵺梡偄傜傟傞乽宍懺慺夝愅乿偲乽N-Gram乿傪巊偭偨丄乽index乿乮僀儞僨僢僋僗乯偵偍偗傞揔崌棪偲嵞尰棪傪岦忋偝偣傞庤朄偺堦椺傪徯夘偟傑偡丅
丂専嶕僄儞僕儞偺奣梫偲僀儞僨僢僋僗丄乽宍懺慺夝愅乿偲乽N-Gram乿偵偮偄偰抦傜側偄曽偼丄壓婰婰帠傪嶲徠偟偰偔偩偝偄丅Elasticsearch偲摨偠偔乽Apache Lucene乿傪儀乕僗偵嶌傜傟偨乽Apache Solr乿偺徯夘婰帠偱偡偑丄婎杮揑側峫偊曽偼摨偠偱偡丅
宍懺慺夝愅偲N-gram偵傛傞乽index乿
丂墷暷尵岅偲斾妑偟偰丄擔杮岅偺僪僉儏儊儞僩傪僩乕僋儞丄傕偟偔偼岅側偳偺嵟彫扨埵偵暘妱偡傞僞僗僋偼旕忢偵擄偟偄栤戣偱偡丅偦偟偰丄偙偺暘妱曽朄偑擔杮岅偵偍偗傞専嶕偱偺惛搙偵戝偒偔娭傢傝傑偡丅擔杮岅偵偍偗傞index峔抸偵偼丄懡偔偺応崌偵師偺2偮偺曽朄偑嵦傜傟傑偡丅
- 宍懺慺夝愅偵傛傞乽index乿
- N-Gram偵傛傞乽index乿
丂専嶕偐傜尒傞偲丄乽宍懺慺夝愅乿偲偼丄乽僪僉儏儊儞僩傪峔惉偡傞嵟彫扨埵偵僪僉儏儊儞僩傪暘妱偡傞乿偙偲偑庡側僞僗僋偵側傝傑偡丅宍懺慺夝愅偱偼丄庡偵暥朄傗摿掕偺儖乕儖偲帿彂傪儀乕僗偵暘妱偑峴傢傟丄扨岅偺暘妱偵壛偊偰昳帉偺悇掕側偳傕娷傑傟傞偨傔丄擔杮岅偲偟偰帺慠側暘妱寢壥傪摼傜傟傑偡丅
丂堦曽偺乽N-Gram乿偼乽N乿暥帤扨埵偱偺暘妱偵側傝丄椺偊偽乽2-Gram乿偱偼2暥帤扨埵偱偺暘妱偲側傝傑偡丅
丂壓婰僒儞僾儖僪僉儏儊儞僩乽拞栚崟偺嶗乿傪宍懺慺夝愅偲N-Gram乮2-Gram乯偱暘妱偟偨寢壥偼丄埲壓偺傛偆偵側傞偱偟傚偆丅
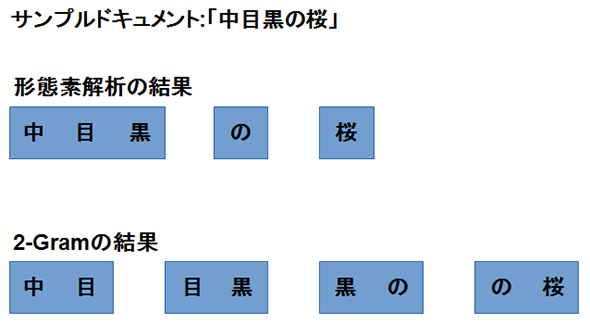 恾5
恾5丂専嶕偼丄乽僪僉儏儊儞僩偺暘妱偝傟偨梫慺乿偲乽専嶕岅偱偁傞僋僄儕乿偑堦抳偡傞偐斲偐傪敾掕偡傞偙偲偵側傝傑偡丅
丂僒儞僾儖僪僉儏儊儞僩乽拞栚崟偺嶗乿偵懳偟偰丄僋僄儕乽栚崟乿偑専嶕偝傟偨偲壖掕偟傑偟傚偆丅巆擮側偑傜丄宍懺慺夝愅偺index偱偼僸僢僩偣偢丄N-Gram偺index偺傒偵僸僢僩偟傑偡乮宍懺慺夝愅偺暘妱寢壥偵偼乽栚崟乿偼尰傟偢丄N-Gram偺暘妱寢壥偵偼乽栚崟乿偑尰傟傑偡乯丅
宍懺慺夝愅偲N-Gram偺棙揰偲寚揰
丂偙偺椺偩偗偱偼丄偁傑傝偵傕宍懺慺夝愅偺index偵暘偑側偄傛偆偵尒偊傑偡偑丄偦傟偧傟偵棙揰偲寚揰偲偑偁傝丄偦傟偼師偺傛偆偵側傞偱偟傚偆丅
- 宍懺慺夝愅
- 棙揰丗僲僀僘偑彮側偄佀乽拞栚崟乿偲乽栚崟乿偑嬫暿偝傟傞丅
- 寚揰丗庢傝偙傏偟偑偁傞佀乽栚崟乿偱専嶕偟偨恖偼丄乽拞栚崟乿傕専嶕寢壥偵娷傔偰梸偟偐偭偨偐傕偟傟側偄
- N-Gram
- 棙揰丗庢傝偙傏偟偑側偄佀乽栚崟乿偱専嶕偟偨恖偱丄乽拞栚崟乿傕娷傔偰梸偟偐偭偨恖偵偼椙偄寢壥偲側傞
- 寚揰丗僲僀僘偑懡偄佀乽栚崟乿傪専嶕偟偨恖偼丄乽拞栚崟乿傪専嶕偵娷傔偰梸偟偔側偄偐傕偟傟側偄
丂偙傟傑偱媍榑偟偨揔崌棪偲嵞尰棪偵摉偰偼傔偰傒傟偽丄堦斒揑偵師偺傛偆側孹岦偵側傝傑偡丅
| 揔崌棪 | 嵞尰棪 | |
|---|---|---|
| 宍懺慺夝愅 | 崅 | 掅 |
| N-Gram | 掅 | 崅 |
丂巆擮側偑傜丄愭傎偳媍榑偟偨F抣傪峫椂偟偰傒偰傕丄揔崌棪偲嵞尰棪偺斾棪傪曄偊偰傒側偄尷傝丄堦斒揑偵偳偪傜偺惛搙偑崅偄偐偼峛壋偮偗偑偨偄忬嫷偱偡丅
丂偡側傢偪丄僒儞僾儖乽拞栚崟乿偺椺偵偁傞傛偆偵丄亀乽栚崟乿偱専嶕偟偨応崌丄乽拞栚崟乿傪専嶕寢壥偵娷傔傞傋偒偐丠 斲偐丠亁偲偄偆栤偄偵丄堦斒揑側摎偊傪媮傔傞偺偼旕忢偵擄偟偄栤戣偱偡丅偟偐偟丄揔崌棪偲嵞尰棪偺媍榑偱F抣傪摫擖偟偨傛偆偵丄偙傟傜宍懺慺夝愅偲N-Gram偺僶儔儞僗傪庢傞専嶕偑壜擻偱偡丅
娭楢婰帠
 Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞
Hadoop偼乽擄偟偄丒抶偄丒巊偊側偄乿丠 墇偊傜傟側偄暻偑偁傞棟桼偲懪奐嶔傪惍棟偡傞
僽乕儉偩偭偨Hadoop丅偱傕幚嵺偵偼傾乕儕乕傾僟僾僞乕埲奜偵偼丄埖偄偵偔偔偰晛媦偑恑傑側偄偺偑尰忬偩丅偦偺壽戣偵婔偮偐偺夝寛嶔偑弌偰偒偨丅揮姺婜傪寎偊傞Hadoop傪傔偖傞忬嫷傪惍棟偟傛偆丅 偄傑偝傜暦偗側偄Hadoop偲僥僉僗僩儅僀僯儞僌擖栧
偄傑偝傜暦偗側偄Hadoop偲僥僉僗僩儅僀僯儞僌擖栧
Hadoop偲偼壗偐傪夝愢偟丄幚嵺偵Hadoop傪巊偭偰戝婯柾僨乕僞傪懳徾偵偟偨僥僉僗僩儅僀僯儞僌傪峴偄傑偡丅僥僉僗僩儅僀僯儞僌傪峴偆僒儞僾儖僾儘僌儔儉偺嶌惉傪捠偠偰丄Hadoop偺巊偄曽傗丄偳偺傛偆偵妶梡偱偒傞偺偐傪夝愢偟傑偡 専嶕僄儞僕儞偺忢幆傪Apache Solr偱恎偵偮偗傞
専嶕僄儞僕儞偺忢幆傪Apache Solr偱恎偵偮偗傞
Hadoop傪偼偠傔丄Java尵岅傪巊偭偰峔抸偝傟傞偙偲偑懡偄乽價僢僌僨乕僞乿張棟偺偨傔偺僼儗乕儉儚乕僋乛儔僀僽儔儕傪徯夘偟側偑傜丄戝検僨乕僞傪妶梡偡傞偨傔偺媄弍偺忢幆傪恎偵晅偗偰偄偔楢嵹 慡暥専嶕僄儞僕儞乽Lucene.Net乿傪巊偆
慡暥専嶕僄儞僕儞乽Lucene.Net乿傪巊偆
僒僀僩峔抸側偳偱巊梡偱偒傞専嶕僄儞僕儞傪VB偱妶梡丅擔杮岅傾僫儔僀僓傪梡偄偨僀儞僨僢僋僗嶌惉偐傜専嶕傾僾儕嶌惉傑偱丅- 僋僢僋僷僢僪丄僌儕乕丄偖傞側傃丄CROOZ偼専嶕媄弍傪偳偆巊偭偰偄傞偺偐丗専嶕媄弍傪巊偆側傜抦偭偰側偄偲懝偡傞6偮偺偙偲
僜乕僔儍儖傾僾儕側偳戝婯柾Web僒乕價僗傗婇嬈撪僔僗僥儉偱傕寚偐偣側偄専嶕媄弍偺傑偲傔 - Namazu偵傛傞慡暥専嶕僔僗僥儉偺摫擖
僒乕僶偵廤愊偟偨忣曬傪嵞棙梡偡傞偵偼慡暥専嶕僔僗僥儉偑昁梫偩丅Namazu偺僀儞僗僩乕儖偐傜愝掕丄Word傗Excel僼傽僀儖偺僒億乕僩曽朄丄岠壥揑側塣梡曽朄傑偱傪夝愢偡傞
Copyright © ITmedia, Inc. All Rights Reserved.
傾僀僥傿儊僨傿傾偐傜偺偍抦傜偣




拲栚偺僥乕儅

曇廤晹偐傜偺偍抦傜偣
![]() ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅
ITmedia偼傾僀僥傿儊僨傿傾姅幃夛幮偺搊榐彜昗偱偡丅