Zabbix+Pacemaker+Fluentd+Norikra+Jenkinsで監視、クラスタリング、ログ収集/解析、バックアップ:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(終)(1/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。最終回は、監視、クラスタリング、ログ収集/解析、バックアップに使っているOSS技術と、その使いどころを紹介する。
リクルートの全社検索基盤「Qass」の事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する本連載。
最終回となる今回は、前回の「AWS+オンプレのハイブリッドクラウドな大規模検索基盤ではImmutable InfrastructureとCI/CDをどうやって実践しているのか」に引き続き運用部分(監視・ログ収集・バックアップ)、そしてQassの今後の展望についてお伝えします。
検索基盤の監視方式
システムを安定稼働させるには、「サーバーやアプリケーションが正常に動作しているか」「要求されるパフォーマンスに対してリソースは足りているか」を常に監視し、障害やリソース不足をすぐさま管理者に通知する仕組みが必要不可欠です。Qassではそうした一般的なシステム監視に加えて、Qassのアーキテクチャやサービスに対応した独自のモニタリングを行っています。どのようなプロダクトをどのような目的で活用しているか、これから詳しく見ていきます。
Zabbixを中心とした監視のための技術
Qassの監視は、統合監視ソフトウエアのZabbixを中心に以下のツールを組み合わせて実行しています。
Qassの継続的インテグレーション/デリバリを実現するツールとして、前回紹介したChefやConsulと同様、OSSで構成されていることが特徴です。オンプレミスのサーバーやネットワークの監視については商用ソフトウエアも一部併用していますが、AWS上で稼働しているサーバーはZabbixのみで監視しています。
オンプレミスとクラウドが混在するシステムにも柔軟に対応できること、後述するように運用を自動化できること、標準の監視項目に加えて自作のスクリプトを監視に使えることがQassにおけるZabbixのメリットと言えます。
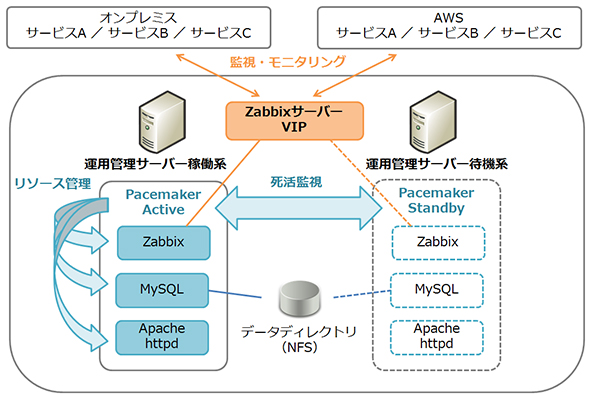
Zabbixサーバーはオンプレミスに2台あり、アクティブ・スタンバイのHAクラスターとして冗長構成を取っています。クラスタリングはPacemakerで実装し、Zabbix、MySQL、Apache HTTP Serverを1つのリソースグループとして管理しています。Zabbixサーバーは仮想IPアドレスを使用しており、フェイルオーバーすると待機系が引き継いで監視を継続します。
オンプレミスとAWSの連携
Qassではオンプレミス〜AWS間の接続に専用線(DirectConnect)を利用し、AWSにAmazon Virtual Private Cloud(VPC)を適用することで両環境を同一のネットワークアドレス体系で運用しています。そのため、Zabbixのネットワークディスカバリ機能や自動登録機能を設定しておけば、AWSにサーバー(インスタンス)を新たに構築した時点で自動的にホストを登録できます。
ただし、Zabbixのホスト名は重複が許されないため、Immutable Infrastructureとしてインスタンスを作り替える際は新旧のホスト名を別々に設定することになります。そうなるとホスト登録も別個で行われ、モニタリングのログを一貫して見渡せないなどの不便が生じます。
Qassの監視方式では、AWS APIとZabbix APIを用いてこうした課題に対処しています。Immutable Infrastructureのビルドフローにおいて新しいインスタンスを構築し、テストまで完了した後はAWS SDK for Rubyを利用した自作スクリプトで以下の処理を行います。
- Zabbixに登録されているホストの一覧をZabbix APIで取得する
- AWSに存在するインスタンスの情報をAWS APIで取得する
- Zabbixのホスト一覧とAWSのインスタンス情報を比較する
- インスタンスのホスト登録が行われている場合はZabbix APIでIPアドレスを上書きして監視を有効化する
- インスタンスが実在しないにもかかわらず、ホスト登録されている場合は監視を無効化する
実在しないインスタンスについて「ホスト削除」ではなく「監視無効化」する理由は、モニタリングのログを残して後から振り返ることができるようにするためです。これら一連の作業が終わり次第、次のアクションとして新インスタンスをELBに取り付け、旧インスタンスの切り離しと破棄を行います。
Fluentdのログ収集基盤
監視やモニタリングのみならず、アプリケーションのエラー解析やさらなる検索改善に向けてログを保存しておくことも必要です。Qassでは、冒頭にも記したようにFluentd(td-agent)を用いてログ収集を実施しています。
ログ収集のソフトウエアとして、rsyslogやFlume、Logstashなどが他に存在しますが、Qassでは以下のポイントを評価してFluentdを採用しました。
- RPMパッケージ1つのみで構築が可能
- 多様なInput/Outputフォーマットがプラグイン形式で提供されている
- Rubyで記述されているため、ChefなどでRubyを利用したインフラエンジニアが親しみやすい
- 冗長化や負荷分散が標準機能として備えられている
特にRPMパッケージ1つのみと構成要素が少なく、管理対象を最低限にできることは、Chefなどで構築が自動化されている中でもメリットと感じます。また、各ソフトウエアを検証した際に最も負荷が低かったのがFluentdであり、検索基盤で稼働するアプリケーションに少しでも多くのリソースを割り振りたいという意図にもかなっていました。
Fluentdの構成
Fluentdではとても柔軟に転送やロジック実行などができるので、それだけ設計の自由度も高くなります。ただし、その中では運用開始後に変更が加わる箇所をできるだけ減らし、運用負荷を下げられるようにすることを意識しなければなりません。
導入当初はノードの役割の区分がなく、必要な箇所で転送・集約を行っていました。しかし、「ノード数が増えるにつれて、どのログがどのように転送されているか」「Configや構成要素がどのノードに影響を及ぼすか」が判断しづらい状況となってきました。そのため、現在QassではFluentdの構成としてシンプルなForwarder/Aggregatorのモデルを採用しています。
ここで各ノードの役割は、次のように明確に区別されています。
- Forwarderは、必要なログフォーマットの整形およびAggregatorノードへの転送のみを実施
- Aggregatorは、ログ集約や保存先の割り振り、ロジック実行を担当
サービスを提供するノードにはForwarderという役割のみを与え、ログ集約するためのノードに運用機能を委ねることで各ノード間のConfigの依存を可能な限り減らし、データの流れを分かりやすくしています。

上記のような構成では、Aggregatorノード側で柔軟にデータ転送先を指定することが可能となり、分析基盤を追加する際やデータ連携先を増やしたいといったケースに対応しやすくなります。また、Forwarderノードが増加した際に動的にメトリクスを割り振れるよう、「fluent-plugin-forest」を利用したConfigとしておくことで、設定を更新することなくサーバー追加が行えるようになっています。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 継続的インテグレーションを始めるための基礎知識
継続的インテグレーションを始めるための基礎知識
大規模開発とCIの関係、CI製品/サービス7選、選定の3つのポイント、Jenkins導入で解決した問題点などを解説する 継続的デリバリ/デプロイを実現する手法・ツールまとめ
継続的デリバリ/デプロイを実現する手法・ツールまとめ
バージョン管理や継続的インテグレーションとも密接に関わる継続的デリバリ/デプロイメントの概要や主なツール、経緯、実践事例を紹介。実践手法として「ブルーグリーン・デプロイメント」「Immutable Infrastructure」が注目だ。 24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
大規模プッシュ通知基盤について、「Pusna-RS」の実装事例を基にアーキテクチャや運用を解説する連載。今回は、Pusna-RSの運用面や発生した課題について、使用している技術やツール「AWS Elastic Beanstalk」「Jenkins」「Amazon CloudWatch」「GrowthForecast」「fluentd」「Elasticsearch」「Kibana」などの説明を交えながら紹介します。 いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。 絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
多くの企業にとって“クラウドファースト”がキーワードとなっている今、クラウドを「適切に」活用する能力はSIerやIT部門のエンジニアにとって必須の技能となっている。今回はビジネス要請にアジャイルに応える「クラウドファースト時代のシステムインテグレーション」に必要な要素技術を解説する。