Zabbix+Pacemaker+Fluentd+Norikra+Jenkinsで監視、クラスタリング、ログ収集/解析、バックアップ:Elasticsearch+Hadoopベースの大規模検索基盤大解剖(終)(2/2 ページ)
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。最終回は、監視、クラスタリング、ログ収集/解析、バックアップに使っているOSS技術と、その使いどころを紹介する。
FluentdとNorikraを使う検索性能の計測
QassのZabbixは検索基盤としての性能を随時測定しています。性能評価指標は主に以下の2つです。
- QPS:1秒間に処理する検索リクエスト数
- Qtime:ミリ秒単位に変換した検索実行時間
検索が100QPSで行われているときのQtimeはいくらか、Elasticsearchのチューニングを行った結果Qtimeはどれだけ増減したかなど、性能試験や通常の運用においてこれらの値を記録し可視化することは欠かせません。
従来Qassでは、各サーバー上で一定期間のログから値を抜き出して集計する、といったバッチ的な処理でQPSやQtimeを計算し、その結果をZabbixに送信することで対応していました。しかし、その方法ではサーバーのリソースを運用目的で消費したり、バースト的に負荷が上昇してしまったりするなど、効率が良くありませんでした。そこで、現在ではFluentdとNorikraを使った新方式に移行しています。
Norikraはストリームデータの処理をSQLライクな構文で実施できるミドルウエアです。一定のタイムウインドー(1分間など)の間に条件に合致したレコードや値を集計して返却する仕組みで、これはQPSやQtimeといった一定期間の平均値などを取得する場合に効率的です。Qassでもそのようなメトリクスを収集する際に用いています。
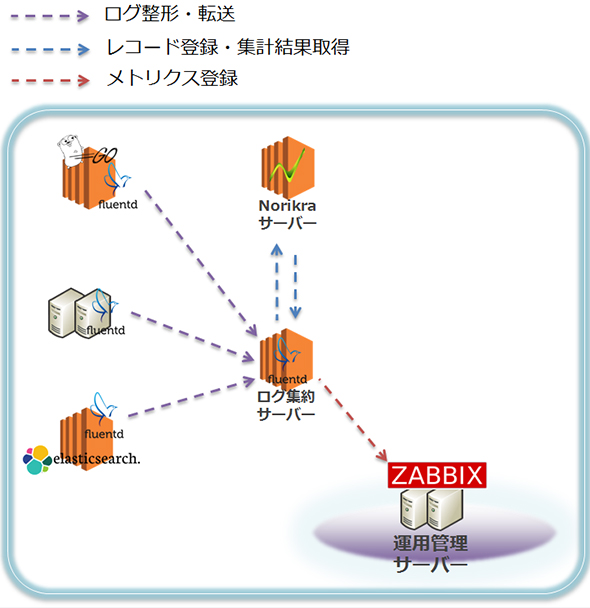
Qassでは、上記の図のように各アプリケーションサーバーからログを集約した後、「fluent-plugin-norikra」でNorikraが動作しているサーバーへ転送・集計結果を取得し、「fluent-plugin-zabbix」を利用してZabbixへメトリクスとして送信することで性能を測定しています。
ElasticsearchのSnapshot And Restore APIとJenkinsを使う検索基盤のバックアップ方式
Qassの検索サーバー群は巨大なインデックスを保持し、常に検索クエリや更新クエリを受け付けています。インデックスの破損・消失が発生しても速やかに復旧できるようにすることは、運用において特に重視すべきところです。
Elasticsearch 1.0.0からSnapshot And Restore APIが利用可能になりました。これを使うとREST APIでインデックスまたはクラスター全体のバックアップ(スナップショット)をリモートリポジトリに保存し、復元することができます。
スナップショットに際しては専用のリモートリポジトリ(以下「バックアップリポジトリ」と呼びます)を用意する必要がありますが、Qassではスケーラビリティを考慮してAmazon S3を利用しています。S3バケットをバックアップリポジトリとして設定し、「AWS Cloud Plugin for Elasticsearch」を検索サーバーに導入した上で次の処理を行います。
- Jenkinsで作成したバックアップジョブを1時間おきに実行し、Snapshot APIを使ってクラスター全体のスナップショットをバックアップリポジトリに保存する
- 直近24時間分および過去7日間の各1回分だけを保存するように別途Delete index APIで古いスナップショットを削除する

バックアップジョブが始まると、ElasticsearchはSnapshot APIを利用してバックアップリポジトリにある過去のスナップショットを分析し、最後に取得した時点からの差分を新たなスナップショットとして保存します。このとき、スナップショット名をYYYYMMDDHHMMと指定することでリストアやパージの際に対象のスナップショットを選択しやすくしています。
バックアップの仕組みは、このようにシンプルですが、リストアの手順も基本的にはインデックスをクローズしてRestore APIを実行するだけと簡潔です。また、スナップショットは障害発生時に限らず、例えば検証用のクラスターをもう一つ他のところに複製するといった使い方もできるため開発時にも役立ちます。実際にQassでも開発環境を構築する際にスナップショットを活用しています。
今後の展望
Qassでは検索品質の向上やアーキテクチャの改善を継続的に行ってきました。今後はどのようなエンハンスを検討しているか、最後に触れておきたいと思います。
- QueryRewriter
- 検索品質をより高速に向上させるため、アプリの改修なしで検索クエリを動的に変更する仕組み
- サービスの企画者自身がカスタマーの求める検索結果を直接調整できる仕組みを整え、より早くカスタマーに価値を提供できるようにする
- 運用作業の省力化
- サーバーリソースの可視化や監視結果に応じたアクションの自動化を進め、人手による運用作業をできるだけ削減する
- 限られた人員でサービス開発に専念するため、SaaSなども取り入れながらサービスのコアでない部分の作業工数を抑える
上記のように、コアなところや重要な基盤部分については検索ユニットでしっかりと引き受け、外部のリソースを用いて実施できる箇所は外部に任せることで、更なる展開スピードの向上を目指しています。
連載第1回の「リクルート全社検索基盤のアーキテクチャ、採用技術、開発体制はどうなっているのか」でお伝えした通り、検索基盤はマッチングビジネスを展開するリクルートにとって必要不可欠な技術要素です。カスタマーが求めるものは日々変遷し、QassのコアエンジンであるElasticsearchも常に進化しています。そうしたビジネスや技術のトレンドに対応しながら、より多くのサービスにQassを展開していきたいと考えています。
筆者紹介
満生 大智
SI企業で公共系Webシステムの運用などを経験後、2014年6月にリクルートテクノロジーズに入社。現在は検索ユニットでインフラ面の開発に従事している。
中原 裕成
大手通信会社でネットワークサービスの開発を経験後、2014年10月にリクルートテクノロジーズに入社。現在は検索ユニットやプッシュ基盤のインフラ面での開発に従事。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 継続的インテグレーションを始めるための基礎知識
継続的インテグレーションを始めるための基礎知識
大規模開発とCIの関係、CI製品/サービス7選、選定の3つのポイント、Jenkins導入で解決した問題点などを解説する 継続的デリバリ/デプロイを実現する手法・ツールまとめ
継続的デリバリ/デプロイを実現する手法・ツールまとめ
バージョン管理や継続的インテグレーションとも密接に関わる継続的デリバリ/デプロイメントの概要や主なツール、経緯、実践事例を紹介。実践手法として「ブルーグリーン・デプロイメント」「Immutable Infrastructure」が注目だ。 24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
24時間途切れないサービスで有効なImmutable Infrastructureの運用方法
大規模プッシュ通知基盤について、「Pusna-RS」の実装事例を基にアーキテクチャや運用を解説する連載。今回は、Pusna-RSの運用面や発生した課題について、使用している技術やツール「AWS Elastic Beanstalk」「Jenkins」「Amazon CloudWatch」「GrowthForecast」「fluentd」「Elasticsearch」「Kibana」などの説明を交えながら紹介します。 いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
いまさら聞けない「クラウドの基礎」〜クラウドファースト時代の常識・非常識〜
クラウドの可能性や適用領域を評価する時代は過ぎ去り、クラウド利用を前提に考える「クラウドファースト」時代に突入している。本連載ではクラウドを使ったSIに豊富な知見を持つ、TISのITアーキテクト 松井暢之氏が、クラウド時代のシステムインテグレーションの在り方を基礎から分かりやすく解説する。 絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
絶対に押さえておきたい、超高速システム構築5要件と3つのテクノロジ
多くの企業にとって“クラウドファースト”がキーワードとなっている今、クラウドを「適切に」活用する能力はSIerやIT部門のエンジニアにとって必須の技能となっている。今回はビジネス要請にアジャイルに応える「クラウドファースト時代のシステムインテグレーション」に必要な要素技術を解説する。