Caffeで画像解析を始めるための基礎知識とインストール、基本的な使い方:いまさら聞けないDeep Learning超入門(2)(1/2 ページ)
最近注目を浴びることが多くなった「Deep Learning」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していく連載。今回は、画像解析における物体認識、Convolutional Neural Netの概要に加え、Caffeの環境構築の仕方や基本的な使い方を解説する。
最近注目を浴びることが多くなった「Deep Learning(ディープラーニング)」と、それを用いた画像に関する施策周りの実装・事例について、リクルートグループにおける実際の開発経験を基に解説していく本連載。前回の「ニューラルネットワーク、Deep Learning、Convolutional Neural Netの基礎知識と活用例、主なDeep Learningフレームワーク6選」では、ニューラルネットワーク、Deep Learning、Convolutional Neural Netの基礎知識と活用例、主なDeep Learningフレームワークを紹介しました。今回は、リクルートグループで画像解析において積極的に利用しているフレームワーク「Caffe」を中心にDeep Learningを利用した画像解析について解説します。
最初に、画像解析で実施している「物体認識」の概要を紹介し、次に物体認識を実現している技術であるConvolutional Neural Netについて、第1回の説明よりもう少し幅広く説明します。その後、この技術を利用するためのモジュールであるCaffeの概要やインストール、基本的な使い方について触れていきます。
画像解析における「物体認識」とは
画像解析における「物体認識」とは、「正解カテゴリ」の付いた「教師画像」を用いて「判別モデル」を作成し、そのモデルに未知の画像を通して各カテゴリに属する確率を算出することで、属するカテゴリを識別する処理を指します。
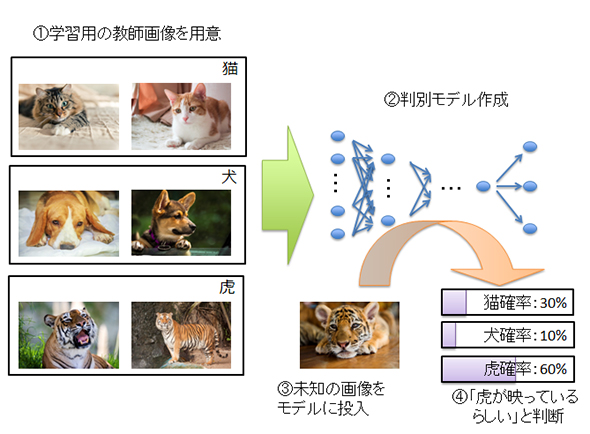
上図は、猫・犬・虎の画像で判別モデルを作成し、学習していない虎の画像をモデルに通して、「映っているのは虎らしい」という識別を実現している例です。この教師画像と正解カテゴリを目的に合った形にカスタマイズすれば、おのおのの物体認識が可能となります。
例えば「ホットペッパービューティ」(リクルートライフスタイル提供)では、ネイル画像の中にどのデザインのネイルが映っているのかを識別して、「類似デザイン検索」機能に活用しています。またキュレーションメディアの「ギャザリー」(リクルートライフスタイル提供)では画像がセクシャルやグロテスクかどうかを識別し、排除する画像校閲機能などに使用しています。この物体認識に活用されている技術が、Deep Learningの一つである「Convolutional Neural Net(CNN)」です。
Convolutional Neural Netを使う際に重要な2つの設定
CNNでは、Convolutional層での「特徴抽出」と、Pooling層での「その特徴をまとめ上げる処理」との繰り返しによって画像の特徴を抽出していきます。そして、最終的に得られる特徴量に、Softmax関数などを適応して判別モデルを作っていきます。
以下の図のイメージで、Convolutional層とPooling層での処理を実施します。この際、処理を実施する順番と、各層におけるパラメーターの設定値(以降、これらを合わせて「ネットワーク定義」と呼びます)が、特徴量の抽出において重要になります。そして、得られた特徴量を元に、出力層で「Softmax関数」などを用いて各カテゴリに属する確率を算出します。
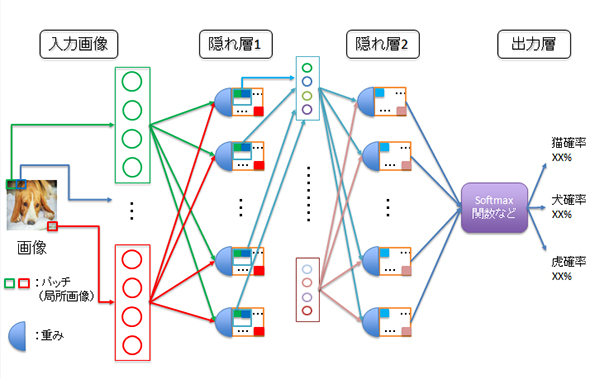
このとき、予測したカテゴリと、正解カテゴリを照らし合わせることで、誤判定率の計算が可能です。つまり、この誤判定率を最小にすれば、識別力が高い判別モデルを作成できたといえます。
誤判定率を減らすためには、各層の重みの最適化が必要です。これは、「誤差逆伝播法(Back Propagation)」を用いて出力層から順番に1つ前の重みを更新することで実現します。重みの更新は一度で完了せず、繰り返し実施することで、識別精度が上昇していきます。最終的に重みの更新が誤判定率に影響しなくなったら、そこで重みの更新は終了となります。
しかし、複雑なネットワーク定義の判別モデルに対して、細かいチューニングを実施し続けると、学習データに対する過学習が起こりやすくなります。これを防ぐために利用されるのが「Dropout」という手法です。Dropoutは、重みの更新時に一定の割合で出力を「0」にします。これにより、モデル作成に利用したデータに最適化され過ぎることを防ぎ、未知の画像に対する予測精度を高めることができます。なお、Dropoutはネットワーク定義で明示的に「どこにどれくらいの割合で実行するか」を指定します。
このようにCNNにおいては、Convolution層やPooling層およびDropoutなどのネットワーク定義と、重みの学習方法の設定の二つが重要となります。
以上がCNNの概要です。以降は、このCNNを得意とするモジュール「Caffe」について紹介します。
Deep Learning用のC++フレームワーク「Caffe」とは
Caffeとは、C++で実装された、Deep Learning用のフレームワークです。グーグルに籍を置くYangqing Jia氏が、カリフォルニア大学のバークレー校の博士課程に在籍したころに開発がスタートしました。
現在では、Berkeley Vision and Learning Center(BVLC)を中心として、コミュニティのコミッターたちがGitHub上で開発/改良を重ねています。
Deep LearningにCaffeを選択したポイント
筆者らは、主に以下二つの観点でCaffeの利用を決めました。なお、Caffeの利用を決めたのは2014年の8月ごろでしたので、その時期の状況を前提に記載します。
画像識別の高精度を報告する論文に、Caffeを利用したものが多かった
「Cifar-10」と呼ばれる、飛行機・車など10種類の画像が各6000枚ずつの計60000枚のデータセットが公開されています。これを使って、世界中で画像識別の精度の競争が起きており、ロジックや結果に関する論文も掲載されています。その中で高精度を出した論文によく使われていたのがCaffeでした。
オープンソースコミュニティが活発
Caffeには「Caffe Model Zoo」という学習済みのモデルを配布するフレームワークがあります。Deep Learningでは適切なネットワーク定義を一から作るのが一つの壁となりますが、Caffe Model Zooの存在がこの壁を乗り超える大きな力になります(※ただし各モデルにはライセンス情報があるため、商用利用の際には注意が必要です)。
その他
上記以外にも、「高速で動作する」「GPUに対応している」「Pythonで利用するインターフェースがある」などが決め手となりました。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 グーグルの人工知能を利用できるWebインターフェースが登場
グーグルの人工知能を利用できるWebインターフェースが登場
オズミックコーポレーションとイントロンワークスは7月7日、グーグルの人工知能アルゴリズム「Deep Dream」を利用できるWebインターフェースを公開した。 顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成――デザイナー/クリエイターが茫然自失で拍手喝采な最先端技術動画11連発
アドビ システムズは、2015年10月6日(現地時間)に開催した「Adobe MAX 2015 Sneak Peeks」で、11の新技術を披露。顔写真3Dモデル化、絶対フォント感、複数画像検索、観光写真無人化、陰影分離、簡単フォント自作、消失点自動作成naなど、今回もデザイナー/クリエイターのみならず、日常的にデジカメやスマホで写真を撮る人でも欲しくなるような機能が多数見られた。 米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
米AlpacaDBがDeep-Learningを使った金融プラットフォームを開発へ
Deep-Learning技術による画像認識プラットフォームを展開してきたAlpacaDBが、資金調達に成功し、金融系の事業領域に本格進出する。 セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
セキュリティ対策に数学の力を――機械学習は先行防御の夢を見るか?
どうしても攻撃者の後手に回りがちなセキュリティ対策。ここに機械学習を活用することで、先手を打った対策を実現できないか――そんな取り組みが始まろうとしている。 個人と対話するボットの裏側――大衆化するITの出口とバックエンド
個人と対話するボットの裏側――大衆化するITの出口とバックエンド
マシンラーニング、ディープラーニングなど、未来を感じさせる数理モデルを使ったコンピューター実装が注目されている。自ら学習し、機械だけでなく人間との対話も可能な技術だ。では、コンピューターはどのように人間との対話を図ればよいのだろうか。コンピューターの技術だけでなく、そこで実装されるべきインターフェースデザインを考えるヒントを、あるコンシューマーアプリ開発のストーリーから見ていく。 自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
自動車を制御するロボットの思考と行動の仕組み――Google Carが現実世界を認識する際の3つのアルゴリズムと実用化への課題
本連載では、公開情報を基に主にソフトウエア(AI、アルゴリズム)の観点でGoogle Carの仕組みを解説していきます。今回は、制御AIの思考と行動のサイクル、位置推定の考え方「Markov Localization」における3つのアルゴリズムと、その使い分け、現実世界の認識における課題などについて。 バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
バンナム、スクエニ、東ロボ、MS――人工知能や機械学習はゲーム開発者に何をもたらすのか
8月26日に開催されたゲーム開発者向けイベントの中から、バンナム、スクエニ、東ロボ、MSなどによる人工知能や機械学習、データ解析における取り組みについての講演内容をまとめてお伝えする。