Spark 2.0の回帰分析アプリをScalaのSBTで実装し、EMRで実行:Amazon EMRで構築するApache Spark超入門(2)(2/3 ページ)
本連載では、Sparkの概要や、ローカル環境でのSparkのクラスタの構築、Sparkの基本的な概念やプログラミングの方法を説明していきます。今回は、簡単な機械学習のSparkアプリケーションを作成し、Amazon EMRで実行するまでを説明します。
メインとなる実装ファイルを記述する
メインとなる実装ファイルは、「src/main/scala/」以下に書いていきます。今回は、「SparkExampleApp.scala」というファイルを作って処理を記述していきます。
SparkExampleApp.scalaを作成して下記のように編集してください。
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.feature._
import org.apache.spark.ml.regression.LinearRegression
object SparkExampleApp {
def main(args: Array[String]) {
// SparkSessionオブジェクトの作成
val spark = SparkSession
.builder()
.appName("Spark Sample App")
.getOrCreate()
import spark.implicits._ // データフレームを扱うためのおまじない
// この後に処理を書いていきます。
}
}
上記のコードの解説です。
1〜4行目では必要なパッケージをimportしています。
Spark 2のSparkSessionオブジェクトを作成
次に、SparkExampleAppというシングルトンオブジェクトを定義して(6〜20行目)、その中のmainメソッド内にアプリケーションの処理を記述しています(8〜19行目)。
mainメソッド内では、まず、Spark 2.0.0から追加されたSparkSessionオブジェクトを作成しています。このオブジェクトを通して、データの処理が行えます。生成時には、メソッドチェーンでSessionの設定を記述できます。今回はAppNameメソッドでアプリケーションの名前を指定しています(10〜13行目)。
他にもいろいろ指定できますが、実行時に直接指定したりconfigファイルに別途記述したりすることもできるので、そちらの方が便利です。そのため筆者は、ここでは簡潔に書くようにしています。
15行目で「import spark.implicits._」という記述がありますが、これは「データフレーム」を扱うための記述です。今回用いる「spark.ml」という機械学習のパッケージは、データフレームを扱うので必要になります。
データフレームとは
簡単に説明すると、前回説明した「RDD(Resilient Distributed Dataset)」をより便利したもので、より直感的にデータを扱える仕組みです。
SQLライクにデータを取得できる高レベルなAPIがそろっているので、簡潔により短いコードで実装していくことが可能です。また、処理の最適化も行われています。そのため、直接RDDを扱うよりもメリットがあります。
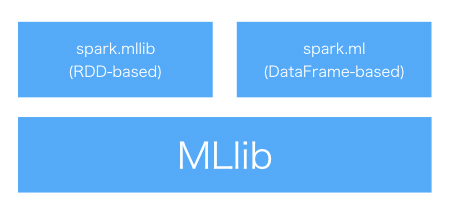
spark.mlを含む「MLLib」について
Sparkには「MLlib」という機械学習のパッケージがあります。回帰や分類、クラスタリングと基本的なアルゴリズムを備えています。
MLlibにはRDDベース(spark.mllib)とDataFrameベース(spark.ml)の2つがあります。前者はSpark 2.0.0からメンテナンスモードとなりました。なので、spark.mlを使うことを推奨されています。今回は後者の方を使っていきます。
AWSへの接続とcsvからデータを読み込むデータフレームの作成
実装の解説に戻ります。続けて、先ほどのコードのmainメソッド内の17行目に下記のコードを書いていきます。
// AWSのAccessKeyの設定
spark.sparkContext.hadoopConfiguration.set("fs.s3n.awsAccessKeyId", "*********")
spark.sparkContext.hadoopConfiguration.set("fs.s3n.awsSecretAccessKey", "*********")
// csvからデータを読み込むデータフレームの作成
val filePath = args(0)
val df = spark.sqlContext.read
.format("com.databricks.spark.csv") // データのフォーマットを指定します。
.option("header", "true") // カラム名をデータフレームのスキーマに反映します。
.option("inferSchema", "true") // 型の自動変換も行います。
.load(filePath)
まず、S3へアクセスするためのAccessKeyIdを設定しています(1〜3行目)。こちらは各自の環境に合わせて設定してください。
次に、S3上のcsvファイルを読み込んでデータフレームを作成しています(5〜11行目)。filePathはアプリケーション実行時に引数で指定する想定です。
パイプラインオブジェクトを作成
続けて、下記のコードを書いてください。
// Pipelineの各要素を作成
// 【1】素性のベクトルを生成します
val assembler = new VectorAssembler()
.setInputCols(Array("x")) // 説明変数を指定します。
.setOutputCol("features") // 変換後の値をfeaturesという名前でデータフレームに追加
// 【2】素性のベクトルを多項式にします
val polynomialExpansion = new PolynomialExpansion()
.setInputCol(assembler.getOutputCol) // featuresの文字列です。
.setOutputCol("polyFeatures") // 変換後の値をpolyFeaturesという名前でデータフレームに追加
.setDegree(4) // 4次の多項式です。
// 【3】線形回帰の予測器を指定します
val linearRegression = new LinearRegression()
.setLabelCol("y") // 目的変数です。
.setFeaturesCol(polynomialExpansion.getOutputCol) // polyFeaturesの文字列です。
.setMaxIter(100) // 繰り返しが100回
.setRegParam(0.0) // 正則化パラメータ
// 【1】〜【3】を元にパイプラインオブジェクトを作ります
val pipeline = new Pipeline()
.setStages(Array(assembler, polynomialExpansion, linearRegression))
上記はパイプラインオブジェクトを生成しています。
「Pipeline」とは
Pipelineはデータの整形から予測モデルの生成までの一連の処理を、簡潔に書くことができる仕組みです。
Pipelineのコンポーネントは「変換器」「予測器」の2つで構成されています。変換器を使ってデータを整形し、それを元に予測器でモデルを作成します。
- 変換器(Transformer)
データフレームを分析可能な値に変換できる。例えば、複数のスカラー値からベクトルオブジェクトへの変換、形態素解析、文字数カウントなどが可能 - 予測器(Estimator)
ロジスティック回帰などの分類、回帰分析などの推定、クラスタリングなどができる
上記コードの解説に戻ります。
まず、コード内の【1】の部分では、csvデータの中から分析に使うカラムを指定しています。
// 【1】素性のベクトルを生成します
val assembler = new VectorAssembler()
.setInputCols(Array("x")) // 説明変数を指定します。
.setOutputCol("features") // 変換後の値をfeaturesという名前でデータフレームに追加
今回は、説明変数が1つなので、xカラムだけを指定していますが、もし多変量の分析がしたい場合はsetInputCols(Array("x1", "x2", "x3", "x4"))などのように複数指定することもできます。
次に、コード内の【2】では、上で指定したカラム「x」の値を4次の多項式化しています。
// 【2】素性のベクトルを多項式にします
val polynomialExpansion = new PolynomialExpansion()
.setInputCol(assembler.getOutputCol) // featuresの文字列です。
.setOutputCol("polyFeatures") // 変換後の値をpolyFeaturesという名前でデータフレームに追加
.setDegree(4) // 4次の多項式です。
具体的には、カラム「x」をインプットにして、(x, x^2, x^3, x^4)のベクトルを「polyFeatures」という新しいカラムにセットしています。
コード内の【3】では予測器について定義しています。先ほど生成したベクトルを説明変数に、データフレーム(つまりcsv内)のカラム「y」を目的変数として学習モデルを作ります。
// 3. 線形回帰の予測器を指定します
val linearRegression = new LinearRegression()
.setLabelCol("y") // 目的変数です。
.setFeaturesCol(polynomialExpansion.getOutputCol) // polyFeaturesの文字列です。
.setMaxIter(100) // 繰り返しが100回
.setRegParam(0.0) // 正則化パラメータ
今回は、繰り返し回数を「100」に、正則化パラメータ(setRegParam)を「0.0」に指定して正則化は「なし」に設定しています。
パラメータの設定はモデルの作成において重要です。
繰り返し回数は大きく設定すればするほど、精度の向上が期待できますが、計算時間が増えてしまいます。また、正則化パラメータは、大きくすればするほどモデルの複雑さを解消できますが、大きくし過ぎると、素性の効果が薄れ過ぎてしまいます。
これらのパラメータは最適な値を設定する必要があります。最適な値を求める方法として「グリッドサーチ」がありますが、Sparkではそれも簡単にできます(次回以降に説明する予定です)。
最後に、pipelineオブジェクトを作成しています。変換器や予測器がステージごとに処理されるように、setStageメソッドでそれらを指定しています。
データの指定と実行結果の保存
続けて、下記のコードを書きます。
val Array(trainingData, testData) = df.randomSplit(Array(0.7, 0.3))
val model = pipeline.fit(trainingData) // 学習データを指定します。
// csvに保存
val outputFilePath = args(1)
model.transform(testData) // テストデータを指定します
.select("x", "prediction")
.write
.format("com.databricks.spark.csv") // データのフォーマットを指定します。
.option("header", "false") // ヘッダーにカラム名をつけるか
.save(outputFilePath) // ファイルの保存先です。
まず、最初に生成したデータフレームを学習用とテスト用に分けています。次に、piplelineオブジェクトからモデルを作成しています。そして、そのモデルを元にテスト用データの変換(予測)を行い、csvとして書き込みます。
SparkExampleApp.scalaの完成コード
完成すると下記のようなコードになっているかと思います。GitHubに上げておきました。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 知らないと大損する、Apache Sparkの基礎知識と3つのメリット
知らないと大損する、Apache Sparkの基礎知識と3つのメリット
社会一般から大きな注目を集めているIoT(Internet of Things)。だが、その具体像はまだ浸透しているとはいえない。今回は、IoTやビッグデータのキーテクノロジとして注目されている「Apache Spark」について、Sparkを製品に取り込んでいる日本IBMの土屋敦氏と、数多くの企業のデータ分析を担うブレインパッドの下田倫大氏に話をうかがった。 Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
Sparkのエンタープライズ対応が「成熟」――Clouderaが宣言
HadoopディストリビューターもあらためてSparkへの注力をアピール。既に800ノード超のSparkクラスターを運用するユーザーも存在するという。 Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
Sparkは“誰”に例えられる?──多様化と進化を続ける「Hadoop」、人気急上昇「Spark」
先日、日本Hadoopユーザー会主催のイベントが開催されました。データベースと関係性が深いデータ分散処理プラットフォームである「Hadoop」と「Spark」の最近事情に迫ります。