R(プログラミング言語):Dev Basics/Keyword
Rは主に統計解析やその可視化を行うためのオープンソースのソフトウェア環境。さらに機械学習を行うためのツールとしても広く使われている。
Rは主に統計解析やその可視化を行うためのオープンソースのソフトウェア環境(プログラミング言語およびそのランタイム環境)。さらに統計解析だけではなく、機械学習を行うためのツールとしても広く使われている。
Rの特徴
今も述べた通り、Rは統計解析を行い、その結果を視覚化するための機能を豊富に持ったプログラミング言語およびランタイム環境であり、対話的にデータを操作しながら、さまざまな知見を得ることができる。また、サンプルデータが豊富に取りそろえられているので、Rをインストールするだけで、統計処理についての学習を始められる。加えて、さまざまなライブラリ/パッケージがCRAN(The Comprehensive R Archive Network)で提供されている。なお、以下ではRおよびそのIDEとして有名なRStudioをインストールした環境で動作を確認している。

言語として見たときのRの特徴はベクトルや行列、データフレームといったRが提供する各種のデータ型を直感的に扱えるという点にある。ここでいうベクトルとは特定の型の値を要素とする1次元のデータ構造、行列は同じく同じ型の値を要素とする2次元のデータ構造、データフレームとはExcelと同様な行列形式のデータ構造であるが、行列とは異なり列ごとに異なる型のデータを格納できる。この他にも任意の種類のデータを格納可能なリスト、多次元行列を表す配列などの複雑なデータ構造がRでは使用できる。
直感的とは次のような計算がRでは可能ということだ。ここで関数cは引数に指定した値を要素とするベクトルを作成し、「4:1」は「4, 3, 2, 1」というベクトルを作成する。
v1 = c(1, 2, 3, 4)
v2 = 4:1
v1 + v2 # [1] 5 5 5 5
v1 - v2 # [1] -3 -1 1 3
v1 * v2 # [1] 4 6 6 4
v1 / v2 # [1] 0.2500000 0.6666667 1.5000000 4.0000000
上のコード例では同じ要素数のベクトルの各要素について加減乗除を行っている。通常の言語であれば、各要素を加算するにはループあるいはマップなどを使用して行うことになるだろうが、Rはベクトルなど、複数の値を格納するデータ構造に対する加減乗除が直感的に行えることが分かる。以下のような演算も可能だ。これはベクトルの各要素を3倍するコードだ。
v1 * 3 # [1] 3 6 9 12
行列についても見てみよう。
(m1 = matrix(1:4, ncol = 2)) # 2×2の行列
(m2 = matrix(c(1, 0, 0, 1), ncol = 2)) # 2×2の単位行列
m1 + m2 # 行列の加算
m1 * m2 # 行列の要素ごとの乗算
m1 %*% m2 # 行列の積
行列はこのように関数matrixを使用して作成する(最初の2行がかっこで囲まれているのは、代入結果をコンソールに出力するため。以下の実行例を参照)。引数ncolには列数を指定している。最初の例では「1:4」、次の例では「c(1, 0, 0, 1)」と4つの要素を渡しているので、結果的には2×2の行列が作成されることになる(行数を指定する引数nrowもある。引数ncol/nrowの両者を指定した場合、渡した要素の数が行列の総要素数より多ければそれらは捨てられ、少なければエラーとなる)。また、行列の積を求めるのに「%*%」演算子を使用する点には注意しよう。実行結果を以下に示す。
> (m1 = matrix(1:4, ncol = 2)) # 2×2の行列
[,1] [,2]
[1,] 1 3
[2,] 2 4
> (m2 = matrix(c(1, 0, 0, 1), ncol = 2)) # 2×2の単位行列
[,1] [,2]
[1,] 1 0
[2,] 0 1
> m1 + m2 # 行列の加算
[,1] [,2]
[1,] 2 3
[2,] 2 5
> m1 * m2 # 行列の要素ごとの乗算
[,1] [,2]
[1,] 1 0
[2,] 0 4
> m1 %*% m2 # 行列の積
[,1] [,2]
[1,] 1 3
[2,] 2 4
このように、ベクトルなどのデータ構造に対する直感的な操作をサポートしているのがR言語の大きな特徴の1つといえる。
そして、Rを特徴付けるもう1つの大きな要素が「データフレーム」といえる。先ほども述べたがデータフレームとはExcelライクな行列形式のデータ構造であり、列ごとに異なる型の値を格納できる。以下に例を示す。
students = c("isshiki", "kawasaki", "endo")
math_results = c(95, 50, 80)
eng_results = c(80, 60, 70)
(df = data.frame(Student = students, Math = math_results, English = eng_results))
これは3人の学生とその数学/英語の試験の成績をデータフレームにまとめるものだ。実行例を以下に示す。
> students = c("isshiki", "kawasaki", "endo")
> math_results = c(95, 50, 80)
> eng_results = c(80, 60, 70)
> (df = data.frame(Student = students, Math = math_results, English = eng_results))
Student Math English
1 isshiki 95 80
2 kawasaki 50 60
3 endo 80 70
行列やベクトルとは異なり、異なる型のデータを扱えていることが分かる。ただし、注意点が幾つかある。まず、関数data.frame呼び出しで名前付き引数の形でStudent/Math/Englishを指定している点だ。これにより、列名が指定されている。もう1つは、変数studentsは文字列を含むベクトルとなっていたが、データフレームには引用符が見えないところだ。実は、上のコード例では文字列は因子(factor)と呼ばれる型のデータに変換されている。これは解析を行う際に使用されるもので、例えば、天気が「晴れ」「曇り」「雨」といったカテゴリで表現される場合に、それらを因子として表現する(因子は文字列のように見えるデータ、シンボルを扱うためのものだが、実際には何らかの数値と関連付けられて保存され、これによりカテゴリを表す要素として文字列をそのまま利用するよりもメモリ効率がよくなる。これについてはこの後で例で見てみよう)。
行列形式に並べられたデータには幾つかの方法でアクセスできる。基本的には列名を指定する方法と、「[行, 列]」形式で指定する方法がある。ただし、単独で「[x]」とした場合には第x列が参照される。上の出力結果と照らし合わせながら見てほしい。
df$Student # Student列
df[1, ] # 第1行(列指定を省略)
df[1] # 第1列
df[, 2] # 第2列(行指定を省略)
df[3, 1] # 第3行第1列
df[2:3, 1:3] # 第2行と第3行の全列
class(df[1]) # 第1列のクラス
class(df[3, 1]) # endoのクラス
as.integer(df[3, 1]) # 因子endoに関連付けられている数値
以下に実行結果を示す。
> df$Student # Student列
[1] isshiki kawasaki endo
Levels: endo isshiki kawasaki
> df[1, ] # 第1行(列指定を省略)
Student Math English
1 isshiki 95 80
> df[1] # 第1列
Student
1 isshiki
2 kawasaki
3 endo
> df[, 2] # 第2列(行指定を省略)
[1] 95 50 80
> df[3, 1] # 第3行第1列
[1] endo
Levels: endo isshiki kawasaki
> df[2:3, 1:3] # 第2行と第3行の全列
Student Math English
2 kawasaki 50 60
3 endo 80 70
> class(df[1]) # 第1列のクラス
[1] "data.frame"
> class(df[3, 1]) # endoのクラス
[1] "factor"
> as.integer(df[3, 1]) # 因子endoに関連付けられている数値
[1] 1
最後の方にある2つの関数class呼び出しは1列目(Student列)とその要素(df[3,1])のクラスを調べるものだ。最初の関数class呼び出しでは"data.frame"が返されている。これはdf[1]が返すものがデータフレームである(行列形式のデータ構造)であることを示している。これと同じデータは先頭の「df$Student」でも取り出しているが、その出力形式が異なっている点に注意しよう。「df$Student」と「df[3, 1]」の実行結果には「Levels」で始まる行も出力されている。これは、これらの結果が因子(factor)を取り出していて、その因子には「endo」「isshiki」「kawasaki」の3つのレベルがあることを示している(ただし、これらの因子は順序性を持たない。実際には何かのエラーの重大度について例えば「Error>Warning>Info」などのように順序性を持たせることも可能)。また、最後の「as.integer」呼び出しでは因子endoが数値1に関連付けられていることが分かる。
次にグラフのプロットについて見てみよう。Rではとても簡単にグラフも描画できる。まずは関数を定義して、その関数の値をグラフ化してみる。
f <- function(x) { x ^ 2 }
x = 1:5
f(x)
plot(x, f(x))
plot(x, f(x), type="l")
関数fは見ての通り、渡された値の二乗を返す(「<-」はRにおける代入演算子なので、変数fに関数が代入されている)。ここでは、「1, 2, 3, 4, 5」を要素とするベクトルを関数に渡しているので、その結果はもちろん「1, 4, 9, 16, 25」となる(このように関数にベクトルを渡すと、その全要素に関数が適用されるのもRの特徴の1つだ)。実行結果を以下に示す。最初のグラフは点で値をプロットし、次のグラフは各値を折れ線でつないでいる(ので、グラフの線が示す値は実際の値とは異なる)。
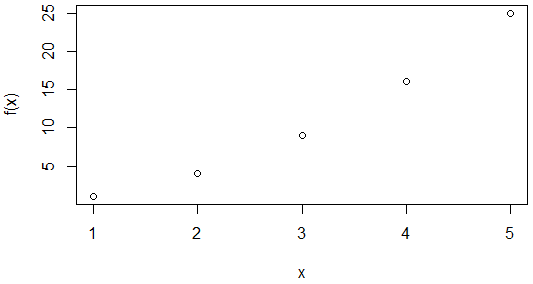
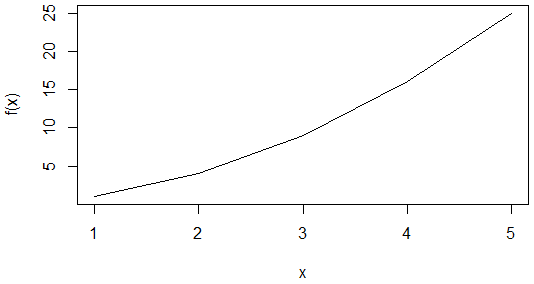
また、Rには統計処理を学ぶために使えるさまざまなデモやサンプルデータも用意されている。最後に、その例から1つ選んで、そのグラフを実際にプロットしてみよう。ここでは「HairEyeColor」という学生の性別ごとにまとめた髪の毛と目の色についての統計データを例にする。まずはHairEyeColorについての概要を見てみよう。
?HairEyeColor # ヘルプを表示
これによりHairEyeColorのドキュメントが表示される。
ドキュメントの最後にあるExampleに従って集計を行ってみよう。
HairEyeColor # 男女別の集計結果を表示
x <- apply(HairEyeColor, c(1, 2), sum) # 1つの表にまとめる
x
以下に実行結果を示す。
> HairEyeColor # 男女別の集計結果を表示
, , Sex = Male
Eye
Hair Brown Blue Hazel Green
Black 32 11 10 3
Brown 53 50 25 15
Red 10 10 7 7
Blond 3 30 5 8
, , Sex = Female
Eye
Hair Brown Blue Hazel Green
Black 36 9 5 2
Brown 66 34 29 14
Red 16 7 7 7
Blond 4 64 5 8
> x <- apply(HairEyeColor, c(1, 2), sum) # 1つの表にまとめる
> x
Eye
Hair Brown Blue Hazel Green
Black 68 20 15 5
Brown 119 84 54 29
Red 26 17 14 14
Blond 7 94 10 16
これを基にモザイク状にグラフをプロットするのがドキュメントにある「mosaicplot(x, main = "……")」という行だ。興味のある方はプロットをしてみよう。ここでは、これは行わずに、HairEyeColorオブジェクトからデータフレームを作成してみよう。
y <- data.frame(HairEyeColor)
y
plot(y$Hair, y$Eye, xlab="hair", ylab="eye")
plot(y$Eye, y$Hair, xlab="eye", ylab="hair")
実行結果を以下に示す(パッと見には相関はないようだ)。
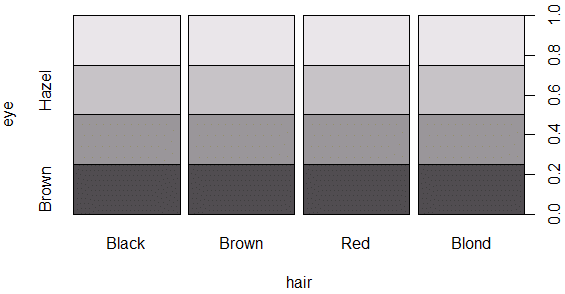
Rにはこの他にも多数のサンプルデータがあるので、いろいろと試してみるとよい。どんなサンプルデータがあるかについては「R言語 サンプルデータ一覧」が役に立つ。前述のページで概要を見た後に、ドキュメントを見ながら実際にデータを操作してみよう。
Rは統計解析を行い、その結果を視覚化するための機能を豊富に持ったプログラミング言語およびランタイム環境であり、対話的にデータを操作しながら、さまざまな知見を得ることができる。本稿ではRにおける特徴的なデータ構造と、簡単なグラフのプロットだけを紹介したが、CRANから提供されている多くのパッケージを使用することで、統計解析や機械学習を行うためのツールとして広く使われている。
参考資料
- R: Rの公式サイト
- RStudio: R用のIDE「RStudio」の公式サイト。コード補完機能をはじめとして、高度な機能が提供されているので、Rを使ってみようという場合にはぜひインストールしておきたい
- The Microsoft R Portal: マイクロソフトによるR実装の公式サイト
- R言語 サンプルデータ一覧: Rが標準で提供しているサンプルデータにどんなものがあるかを紹介してくれているページ
Copyright© Digital Advantage Corp. All Rights Reserved.