React/Redux/Node.jsのSSR/SPAを速くする6つのチューニングポイント:大規模ブログサイト表示速度改善 大解剖(終)(2/3 ページ)
2004年から続くブログサービス「アメブロ」が2016年9月にシステムをリニューアル。本連載では、そこで取り入れた主要な技術や、その効果を紹介していく。今回は、React/Redux/Node.jsを使ったIsomorphic JavaScript特有のパフォーマンスチューニング手法や実際にあった問題および、その解決方法について。
【チューニングポイント1】非同期レンダリング
先述の通り、ReactのrenderToStringを修正して非同期レンダリングを実現するのはほぼ不可能です。しかしマルチプロセスを使い、CPU負荷の大きなレンダリングタスクを別のプロセスに移せば、メインプロセスとは非同期でレンダリングを行えます。
それには、Node.jsのclusterモジュールを使うと便利です。メインプロセスとWorkerの間を「process.send」「process.on('message')」メソッドで通信します。
【チューニングポイント2】モジュールの遅延ロード
ほとんどの場合、サーバでレンダリングする必要がないコンポーネントは、ブラウザ上で最初にユーザーに見せるものではないため、その内容はスクロールに応じて表示していきます。
「モジュールの遅延ロード」は、ページの上から下へスクロールする際にコンポーネントのレンダリングを遅延させるだけではなく、「SSRに必要ないコンポーネントをサーバサイドでレンダリングせずフロントエンドでレンダリングする」ように遅延させます。これにより、「renderToString()」メソッドの実行時間を短縮できます。
アメブロでは「rrr-lazy」を使い、それらのコンポーネントを完全にLazy化して、サーバもフロントもパフォーマンスを改善できました。
class LazyComponent extends React.Component {
constructor() {
this.state = {
show: false,
}
}
componentDidMount() {
this.setState({
show: true;
});
}
render() {
if (!this.state.show) {
return null;
}
return (
<div>Content</div>
);
}
}
Reactのライフサイクルの特徴として、サーバサイドのレンダリングは「componentWillMount()」→「render()」までとなっているので、この特徴を活用し、フロントエンドでしか実行されない「componentDidMount()」を一緒に使うことで、レンダリング処理をフロントエンドまで遅延します。
非同期レンダリングと遅延ロードを採用した結果
非同期レンダリングと遅延ロードを採用してチューニングした結果は下図のようになりました。
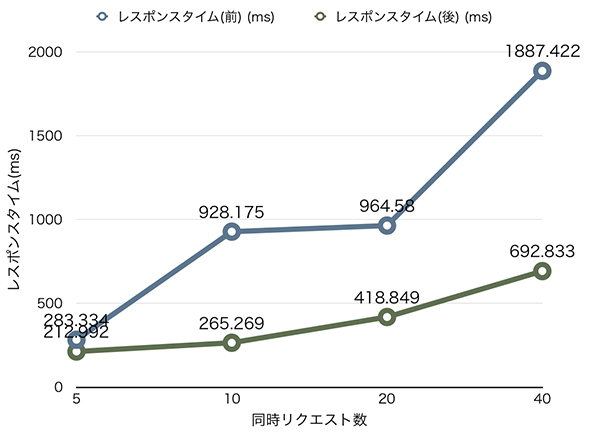
同時リクエスト数が40の場合、スループットは3000rpmぐらいになりました。サーバ1台当たり3000rpmだと、完全に許容する範囲ですが、アメブロのチームでは、レスポンスタイムを100ms以下に抑えることを目標にしました。そこで、次に注目したのが、キャッシュの設計です。
【チューニングポイント3】キャッシュの設計
アメブロでは、投稿・編集系のページよりも閲覧系のページの数が明らかに多いため、レンダリングされたページをキャッシュすると、かなり大きな効果が期待されます。
キャッシュは下図のように2階層に設計しました。

第1階層はOn-memoryキャッシュです。こちらに「lru(least-recently-used)-cache」を使っています。キャッシュされたページの数が少なく制限され、よくアクセスされたページのみを残します。
第2階層はキャッシュサーバです。ユーザーのリクエストが来た際は、レンダリングされたページは、リクエストを受けたサーバ上でキャッシュされますが、それと同時にキャッシュ用のサーバにもキャッシュします。すると、他のリクエストサーバは同じリクエストを受け入れた際に、一度キャッシュサーバに問い合わせてキャッシュされたページを見つけたら、再びレンダリングせずキャッシュされた内容を返します。その際にOn-memoryキャッシュにも入れます。
ここで解決しなければならないポイントが2つあります。
1つは最終的にユーザーに返されたページに、認証情報やブラウザに依存する情報などユーザーごとに異なるデータを含める場合がありますが、全て同じページを返すべきではないということです。
これを解決するためにキャッシュに入れるものは、「renderToString()で実行された結果」のままではなく、「実行された結果+Redux State+ユーザーに依存しないデータ」で生成された“テンプレート”です。このテンプレートはリクエストから抽出されたユーザー依存情報でもう1回レンダリングすると、最終のレスポンス用ページを生成します。図式化すると、下記のようになります。
renderToString()+Redux State+ユーザーに依存しないデータ=キャッシュ用テンプレート キャッシュ用テンプレート+ユーザー情報=最終ページ
もう1つは、ブログが更新されると即時にキャッシュが反映されることです。
これを解決するためには、一般的には「CAS(Check And Set)」が必要ですが、アメブロでは現状に基づいてキャッシュのバージョンを主動的に更新する仕組みを設計しました。
キャッシュサーバに入れるキャッシュキーは、2種類設けます。
- 【キー1】blogger_ver:${NAMESPACE}
- 【キー2】blogger:${NAMESPACE}:${CACHE_VERSION}:${REQUEST_PATH}
NAMESPACEはブロガーのIDです。【キー1】の値はキャッシュのバージョンで、【キー2】の値はレンダリングされたページです。つまり1人のブロガーに対して、全ページに同じバージョンを使います。全てのキャッシュバージョン情報はキャッシュサーバのみに入れます。新しいリクエストが来た際にキャッシュバージョンの情報がない場合、またはバックエンドシステムからキャッシュ削除リクエストが来た場合は、キャッシュのバージョンを生成、更新します。
例えばブロガーが記事を更新したときに、まずバックエンドシステムは即時にブロガーのIDをNode.jsサーバの削除APIに送ります。そして、Node.jsは新しいバージョンを生成し、【キー1】としてキャッシュサーバに保存します。ここまででキャッシュ削除は完了です。
そして更新されたブログページにアクセスした際に、まずNode.jsは一度【キー1】をキャッシュサーバから取ります。取ってきたバージョンで【キー2】を組んで、On-memoryキャッシュとキャッシュサーバから値を探します。【キー2】が変更されているので、「キャッシュが存在しない」と判断し、新しいページをレンダリングします。
例えば、ブロガーがページまたはブログスキンなどを更新したら、このブロガーに関連する全てのキャッシュを無効にさせます。直感的に「効率はあまり良くないのでは」と思われるかもしれませんが、実際の運用状況を見ると比較的効率は良い方です。
この時点で、キャッシュサーバのヒットレートは75%ほどに維持しています。レスポンスタイムは平均100ms以下です。


New Relicでキャッシュされたページとされていないページのレスポンスタイムを確認してみると、キャッシュが比較的効いていることが分かりました。特に、数がより少ない一覧ページはほとんどキャッシュにヒットします。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 マイクロサービスベースのAbemaTV開発プロジェクトが切り開くスクラムとプロジェクト管理の“新境地”
マイクロサービスベースのAbemaTV開発プロジェクトが切り開くスクラムとプロジェクト管理の“新境地”
急成長を遂げるインターネットテレビ局「AbemaTV」の開発現場では、マイクロサービスをベースとするスクラム開発とプロジェクト管理の新たな取り組みが進んでいる。 サイバーエージェントに聞いた、DevOps実践の要件
サイバーエージェントに聞いた、DevOps実践の要件
近年、開発と運用が連携してリリースサイクルを速める「DevOps」という概念が関心を集めている。だが人によって解釈が異なるなど、いまだ言葉先行の感も強い。DevOpsの本当の意義と実践のポイントを探った。