どのようなデータ基盤を作ったのか? データ収集/蓄積/加工/活用、パイプライン管理の設計:開発現場に“データ文化”を浸透させる「データ基盤」大解剖(2)(1/3 ページ)
「ゼクシィ縁結び・恋結び」の開発現場において、筆者が実際に行ったことを題材として、「データ基盤」の構築事例を紹介する連載。今回は、データ基盤システムの構成要素や採用技術の選定理由などをお伝えします。
「使われるデータ基盤」を構築するために筆者が取り組んだ試行錯誤を紹介する本連載『開発現場に“データ文化”を浸透させる「データ基盤」大解剖』。前回はデータ活用の事例やデータ基盤が必要になった理由について解説しました。第2回となる今回は基盤システムの設計、構築についてお伝えします。
なお、技術要素としてはPythonやBigQueryを扱いますが、技術選定の考え方に比重を置いて解説します。細部にとらわれずにご自身の担当する業務や組織に当てはめながら読んでいただければと思います。
「データ基盤」設計における2つのポリシー
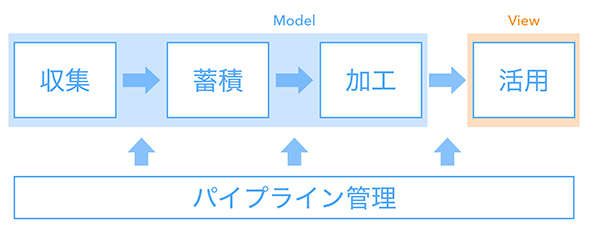
前回の記事では、データ基盤とは複数のデータソースと複数の利用者をリボンのように結び付けるものだとお伝えしました。実態としてはデータの収集から活用までの一連の流れを扱う処理システム群となります。

こちらは構築当初のもので、現在は改善が進み構成要素が多少変わっていますが、設計意図やエッセンスは当初から変えていません。むしろ細部をチューニングする前のシステム設計だからこそ、重要な考え方をお伝えできると思っています。
筆者が掲げた設計ポリシーは「ModelとViewを分ける」「なるべく楽をする」の2つです。
【1】ModelとViewを分ける
「責務に応じてシステムを分離、結合する」ということです。
- Model:データの蓄積や加工(例:集計ロジックなど)
- View:データの参照や活用(例:ダッシュボードなど)

Beforeに当たる箇所は、前回示した図と同じです。データを取り巻くシステム群が、コンウェイの法則が示す通りに責務の混在した構成になってしまいました。「Modelが共通化されていないことでデータ品質の担保が困難になってしまった」というのが根本的な課題です。
この状況を打開して本来あるべきシステム構成へと修正することが求められます。
注意すべき点は、「部署や役割によって最適なViewが異なる」ということです。筆者が担当現場でヒアリングしたところ、以下のような回答が寄せられました。
- ビジネス部門:Excelを使いたい
日常的な分析を、慣れたツールで、気軽に数値を変えてシミュレーションしたい - 分析部門:Tableauを使いたい
高価格なので全員に配布できるわけではないが、専門部隊にはライセンスがある。高機能なので多様な分析要求に対応することができる - Webディレクター:Redashを使いたい
近年のデータ活用の重要性を受けて、SQLを勉強しているメンバーは多い。ビジネス部門へのダッシュボード共有という観点でも便利であり、なおかつエンジニア部門にデータの取り方を相談する意味でも便利。複雑なことをやるのは難しいが、手軽に利用できてちょうどいい - エンジニア(機械学習のチームを含む):Jupyter Notebookを使いたい
プログラミングや統計解析のスキルがある人間にとっては使いやすいツール。Pythonプログラムとの相性が良く、簡単な処理をより簡単に行い、難しい処理も行える。データ可視化や記録・共有の観点でも必要な機能がそろっている。

ここで伝えたいのはツールの良しあしではなく、「自分にとって使いやすいツールが、必ずしも他の役割を担う人々にとってベストではない」ということです。
向き不向きを考慮せずに特定のツールを押し付けるだけでは、使われるデータ基盤にはなりません。大切なのは適切なシステム構成を描くことです。全員が同じデータを参照できるようにModelを共通化することは、データ品質担保のために必要な設計です。各自のユースケースに合わせてViewを個別最適化することは、データ活用促進のために必要な設計です。
一般的なシステム設計と同じで、ModelとViewは分けて考えることが必要となります。
【2】なるべく楽をする
「支払わなくても構わないコストやリスクを極力排除する」ということです。
特別な理由がなければ車輪の再発明をせずに、デファクトスタンダードに準拠しました。主な技術要素としてPythonとBigQuery(Googleが提供するクラウドのデータウェアハウス)を選定しました。
◆Python

開発言語としてPythonを採択したのは以下の理由からです。
- オープンな知見が豊富である
利用者の多い言語のため、サンプルコード探しやトラブルシューティングが容易です。国内コミュニティーも活発で、筆者自身もPythonを触り始めた頃は勉強会で技術相談に乗っていただきました。
- データ操作に優れたライブラリがある
「Pandas」というライブラリでデータの加工や描画を行い、分散していた集計ロジックを一元化しました。BigQueryをはじめ、RDBMSやCSVなど多様なデータソースに対して読み書きを行い、データの中身を「Dataframe」と呼ばれる共通の型に変換して処理することが可能です。
- 汎用的なプログラム処理を書ける
一般的なプログラミング言語なので、想定外の制約が生じるリスクを抑えることができます。例えば、Pandas未対応のシステムと連携したい場合は、Web APIコールやスクレイピングの処理をすぐに書けます。
なお今であれば、BigQueryを使うならGoogle Cloud Platform(以下、GCP)のソリューション群を組み合わせてデータ連携処理を組むのが望ましいでしょう。当時は、まだ必要な条件を満たさず、技術検証に工数を当てる余裕もなかったため、初期構築はPythonのプログラム上であらゆる処理を書き、必要に応じて後から置き換える方針を撮りました。
- 機械学習スクリプトとの相性が良い
もともとプロダクトに組み込まれている機械学習施策のスクリプトがPython製(Scikit Learn)だったことも理由の1つです。将来的に機械学習の処理を統合する可能性があるため、移植しやすさは重視しました。
本連載で扱っているものを、「分析基盤」や「機械学習基盤」ではなく「データ基盤」と呼んでいるのは、用途を限定しないからです。
データが部署ごとにサイロ化して非整合が生じたことが課題なので、機械学習用途もシステム整理の対象となり得ます。
- Jupyter Notebookという利便性の高い実行環境がある
コマンド1つでデバッグやデータ可視化ができるので、データの中身を確認したりクレンジングしたりする用途に向いています。ローカル環境で動作確認をした後に、Pythonスクリプトを吐き出せば、そのままサーバでの運用に乗せられます。
また、内部的にはJSONファイルとして管理されるので、Gitで差分管理が可能であり、記録、再現が行えます。Gitのホスティングサービス(GitHubなど)ではプレビュー機能があるため、共有観点でも利便性が高いです。
次回説明する「開発プロセス」や「データ活用文化醸成」を支えるキードライバーでもあります。
なお、GCPやAmazon Web Services(AWS)、Microsoft Azureといったクラウド事業者はJupyter Notebookを構築するサービスをそれぞれ提供しています。後述するクラウドデータウェアハウスのサービス利用者は相性の良いものを選ぶことができます。Jupyter Notebook自体はローカル環境でもオンプレミスのサーバにでも気軽に立ち上げることが可能です。

◆BigQuery
ここからはDWHにBigQueryを採択した理由についてお話しします。
そもそもDWHにBigQueryのようなクラウドサービスを利用できないところでは、オンプレミス環境にHadoopを構築するといった形になるかもしれません。おのおので事情が異なるので一概には言えませんが、筆者の環境では早い段階でクラウドサービスの利用を意思決定しました。
サーバの保守運用にリソースを費やしても、本来の課題解決には直接つながらず、増え続けるデータやユースケースに対応するために、優秀なSRE人材を駆り出すことになり、機会損失が生じると考えたからです。本当に守るべき制約、達成したい目的は何か。これらを踏まえた技術選定、意思決定を大切にしました。
最終的に、当時のスペックで他のクラウド提供者と比較検討し、以下の3点の理由でBigQueryに決めました。
- 安価である
米Alphabet社(Google)が保持するデータセンターに相乗りすることで、コスト面におけるスケールメリットを享受できます。
- 高性能である
簡単なSELECTクエリを投げるだけで、裏では大量のサーバにアクセスして集計処理を並列実行します。
- 使いやすい
ユーザーインタフェースは標準的なSQLとなっており、学習コストの低さや移植性の高さ、テストのしやすさは魅力的です。周辺ツールと連携しやすく、RedashやTableauなどの主要BIツールならすぐにつながりますし、Python(Pandas)にも接続メソッドが用意されているので、Jupyter Notebookでのデータ処理が簡単に行えます。
上記はあくまでも当時の筆者にとっての見え方です。他にもAmazon RedshiftやTreasure Dataなど候補となるDWHサービスは多々あります。日進月歩の分野で魅力的なサービスが多いので、参考になれば幸いです。また、データ量がそこまで多くないのであれば、主要なRDBMS(MySQL、PostgreSQL)やELKスタック(Elasticsearch+Logstash+Kibana)を分析用途に1つ立て、そこにデータを流し込むだけで十分でしょう。
データフローの構築
このような設計思想に基づいて処理システム群を構築しました。データの収集から活用までの一連の流れに沿って紹介します。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 ネット広告のデータ分析プロジェクトはどのように行われるのか
ネット広告のデータ分析プロジェクトはどのように行われるのか
広告宣伝費を各宣伝媒体へのコスト配分を調整することで効率化したいという事業部の課題に対してデータ分析のプロジェクトはどう進められるものなのか。筆者の経験を基に紹介する。 CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
CVRをあと10%アップする、ビッグデータ分析とアダプティブUXの使い方
ABテストを利用したサイト改善の限界にぶつかっている人たちに向けて、リクルートグループ内で実践している改善ノウハウをお伝えする連載。今回は、中古車販売サイト「カーセンサー」を例に「検討フェーズ」を軸とした個別最適化やビッグデータ分析の有効な生かし方について解説する。 Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
Hadoop+Embulk+Kibanaのデータ集計基盤によるデータ可視化と集計データを活用したキーワードサジェストの仕組み
リクルートの事例を基に、大規模BtoCサービスに求められる検索基盤はどう構築されるものなのか、どんな技術が採用されているのか、運用はどうなっているのかなどについて解説する連載。今回は、ログデータの分析および可視化の基盤を構成する5つの主なOSSや集計データを活用したキーワードサジェストの事例を紹介します。