Pythonの機械学習ライブラリ「scikit-learn」で実践する「教師あり学習」「教師なし学習」:Pythonで始める機械学習入門(7)(3/3 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回は、Pythonの機械学習ライブラリ「scikit-learn」を使って「教師あり学習」「教師なし学習」などについて説明します。
教師なし学習
予測時のお手本となるデータがない場合の学習を「教師なし学習」と呼びます。教師あり学習と異なるのは、訓練データに、ターゲットに当たるデータがないことです。特徴量のみから予測を行います。ここでは典型的タスクとして「クラスタリング」と「次元圧縮」を行います。
K-Means法
「K-Means」法とは、クラスタ(かたまり)を見つけ出す手法です。クラスタの数を指定すると、データをその数のクラスタに分けます。今度はがくの幅と花びらの長さ(インデックス番号で1と2)を使って学習させてみます。
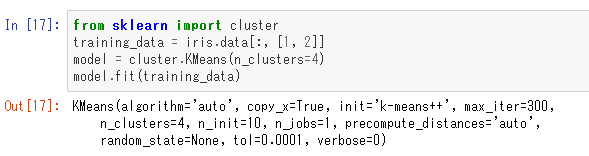
特徴量のデータのみが与えられていて、ターゲットは学習時の入力には与えられていないことに注意してください。「KMeans」クラスのインスタンス化時の引数「n_cluster」でクラスタ数を指定しています。これで学習が終わり、結果は「labels_」というメンバ変数に入っています。

では、この結果を色分けして表示してみます
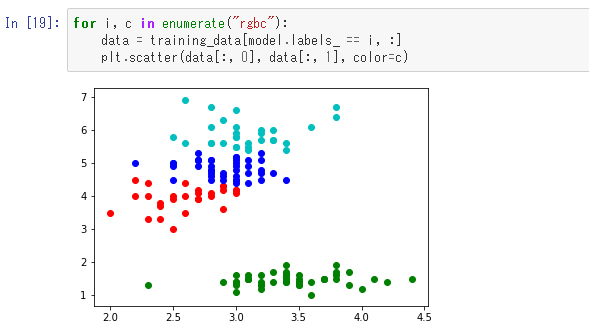
見た目では左上と下に大きなクラスタが2つあるように見えますが、クラスタ数を4として指定したので、左上のクラスタがさらに3つに分けられています。これは教師なし学習であり、あやめの分類についての情報は与えられておらず、点の位置関係のみからクラスタを見つけ出している点に注意してください。
次元圧縮
「PCA」(主成分分析)と呼ばれる手法を使ってあやめデータを2次元に圧縮してみます。
あやめデータは特徴量が4種類ありましたが、今までの例では、平面上に表現するため、そのうちの2つを選択してきました。そのように適当な座標値2つを取る以外にも平面上に射影する方法は無限にあります。PCAでは、その中でも特に点列が広く散らばるような射影を自動的に選択してくれます。これは多次元のデータを可視化するときに特に便利です。
以下に実装を見てみます。

インスタンス化時の引数「n_components」は圧縮後の次元を意味しています。ここでは2次元に圧縮したいので「2」を指定しています。
これで学習が終わりました。学習済みモデルを使って実際に次元圧縮を行うには次のようにします。
これで変数「compressed」には圧縮済みのデータが入っています。ではこれを平面上に可視化してみます。あやめの種類によって色も付けてみます。
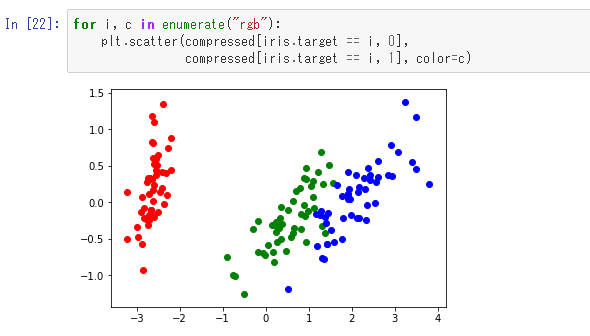
サポートベクターマシンの時に見せた図と比べて緑と赤の点の間が広がっているように見えます。
scikit-learnの本家ドキュメントは教科書としても、とても有用
本稿では、教師あり学習の例として、線形回帰とサポートベクターマシンを、教師なし学習の例として、K-Means法とPCAを見てきました。これはscikit-learnの豊富な機能の一部を示したにすぎず、同じタスクでも複数のアルゴリズムの選択肢があるので注意が必要です。しかし、scikit-learnはアルゴリズムによらず統一性のあるインタフェースを持っているのも特徴であり、ここまでの例で一般的な使い方は示せていると思います。
ここで、scikit-learnの機械学習アルゴリズムにおけるクラスの使い方を一般化して、疑似コードでまとめてみます。教師あり学習では次のような処理の流れになります。
model = SomeAlgorithm() # 何かのアルゴリズムを実現するクラスをインスタンス化 model.fit(data, target) # 特徴量とターゲットを入力にして学習 pred = model.predict(other_data) # 他のデータについて予測
ここで「SomeAlgorithm」とは実際にそういうクラスがあるわけではなく、ここで何らかのアルゴリズムのクラスをインスタンス化するということです。それに対して、教師なし学習では次のような流れになります。
model = SomeAlgorithm() # 何かのアルゴリズムを実現するクラスをインスタンス化 model.fit(data) # 特徴量のみを入力として学習 # ここでモデルのメンバ変数を見て結果を確認するか、次元圧縮の場合はtransformメソッドで変換する
また本稿では、scikit-learnのあやめデータのみを扱ってきました。これはデータ量が少ないので、どのアルゴリズムを使っても一瞬で計算できますが、大量データについては、アルゴリズムによって向き不向きがあります。「やりたいことやデータの特徴に応じて、どのアルゴリズムを選択すべきか」については、scikit-learnのドキュメントに含まれるチャート「Choosing the right estimator」が参考になります。
なお、scikit-learnの本家ドキュメントは、ただクラスや関数の使い方を説明してあるだけではなく、アルゴリズムの解説や機械学習の考え方の解説などもあり、この分野を勉強するときの教科書としてもとても有用です。必要に応じて参照するようにすると理解が深まるでしょう。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
機械学習、ビッグデータ解析に欠かせない、PythonをWindowsにダウンロードしてインストール、アンインストールする
本連載では、さまざまなソフトウェアのインストール、実行するためのセットアップ設定、実行確認、アンインストールの手順を解説する。今回は、Pythonとは何か、Pythonのインストールとアンインストールについて解説。Pythonがよく使われる機械学習やビッグデータ解析を始める参考にしてほしい。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。 Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
Recurrent Neural Networkとは何か、他のニューラルネットワークと何が違うのか
本連載では、Deep Learningの中でも、時系列データを扱うRecurrent Neural Networkについて解説。加えて、その応用方法として原稿校正(誤字脱字の検知)の自動化について解説します。