ニューラルネットワークライブラリTensorFlow/Kerasで実践するディープラーニング:Pythonで始める機械学習入門(8)(2/3 ページ)
最近流行の機械学習/Deep Learningを試してみたいという人のために、Pythonを使った機械学習について主要なライブラリ/ツールの使い方を中心に解説する連載。今回はニューラルネットワークのライブラリであるTensorFlow/Kerasについて解説します。
画像の分類
ここまでは、あやめの分類の例を見てきましたが、あやめの例を出したのは簡単なネットワーク構造で結果が出せるからです。あやめの分類では、ディープラーニング以前の古典的なアルゴリズムで十分精度を上げることができます。一方で、画像の分類ではディープラーニングが実際にブレークスルーになりました。ここからは、画像の分類の例を見てみます。
画像分類のデータセット「cifar10」の準備
「cifar10」という有名な画像分類のデータセットを使います。
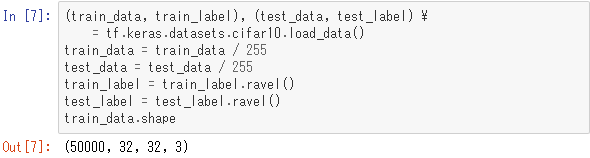
cifar10のデータをダウンロードし、訓練用データを「(train_data, train_label)」に、テスト用データを「(test_data, test_label)」に格納しています。train_dataとtest_dataは特徴量のデータであり、つまり画像データです。基のデータは画素のRGB値を0〜255で表していますが、それを0〜1の範囲になるようにスケーリングしています。
また、ラベルデータは2次元配列で与えられますが、後の処理のためにravelで1次元配列に変換しています。train_data.shapeを表示して確認したように、train_dataは4次元配列です。4次元のうち最初の次元は何枚目の画像かを示しています。
次の2つの次元はピクセルの座標に対応し、最後の次元はRGBのどれを指すかを示しています。つまりi番目(0から数える)の画像の座標(j,k)のピクセルのR(赤)の値はインデックス[i,j,k,0]の値に対応しています。
ラベルの値は0〜9の整数値になっていますが、それぞれの番号に対応する物体は次のようになっています。
ディープラーニングを適用する前にデータの中身を見てみます。各ラベルに対応する画像を10個ずつ訓練データから取り出して表示すると次のようになります。

「コンボリューション(畳み込み)」層と「マックスプール」層
では、これを学習させるためのネットワークを定義します。

あやめの例ではDenseというクラスを使って上位層と下位層を密につないでいましたが、cifar10のデータでは、各画像が32×32×3個の数値を持つので、その入力層と中間層を密につなぐと計算コストが高くなり過ぎます。そこで、「コンボリューション(畳み込み)」層と「マックスプール」層を組み合わせています。これは画像認識ではよく使われるテクニックです。
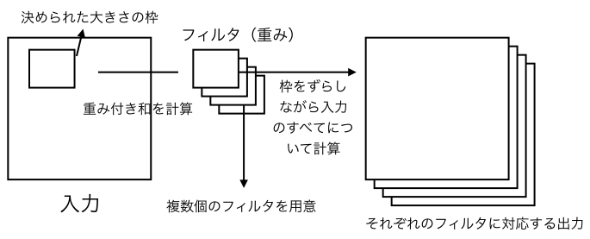
コンボリューション層は、決められたサイズの長方形(多くの場合は正方形)の中の点についての重み付け和を計算したものを、ノードに割り当てる仕組みです。その重み付けのことを「フィルター」と呼びます。フィルターを1つずつずらしながら画像の左上から順番に画像の全体をカバーするように重み付け和を計算します。通常は複数のフィルターを用意し、それぞれに重み付け和を計算します。上記サンプルコードでは「Conv2D」の第1引数の「16」というのがフィルター数で、第2引数の「(3,3)」がフィルターのサイズです。
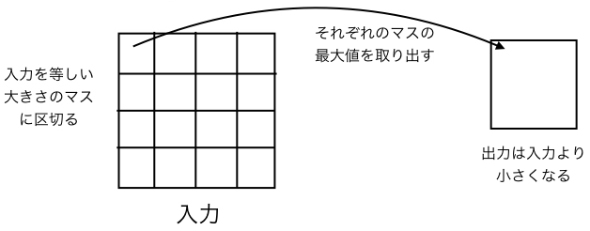
マックスプール層は、入力を同じ大きさのマスに区切って、各マスの中にある点の最大値を取ったものをノードに割り当てる仕組みです。サンプルコード中の「MaxPool2D」の引数として指定している「(2,2)」はマスの大きさを意味します。
ここではコンボリューション(Conv2D)とマックスプール(MaxPool2D)を作用させる操作を2回行っています。その次に「Flatten」という層がありますが、ここでは2次元配列だったものを1次元に変換します。Flattenの層では数値的な計算をするわけではありません。最後の2つの層は密につなげていて、出力層はsoftmax関数を使ってワンホットエンコーディングをしています。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intel、Xeon上での「TensorFlow」使用時向けにDNNモデルコンパイラ「nGraph」の性能を強化
Intelは、「Intel Xeonスケーラブルプロセッサー」上で「TensorFlow」を使用するデータサイエンティスト向けに、フレームワーク非依存のディープニューラルネットワークモデルコンパイラ「nGraph Compiler」のパフォーマンスを高めるブリッジコードを提供開始した。 NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
NVIDIAとGoogle、「TensorRT」と「TensorFlow 1.7」を統合
「NVIDIA TensorRT」とオープンソースソフトウェアの機械学習ライブラリの最新版「TensorFlow 1.7」が統合され、ディープラーニングの推論アプリケーションがGPUで実行しやすくなった。 ITエンジニアがデータサイエンティストを目指すには?
ITエンジニアがデータサイエンティストを目指すには?
それぞれの専門分野を生かした「データサイエンスチーム」を結成すればデータ活用への道は短縮できる。そのとき、ITエンジニアはどんな知識があればいい? データサイエンティストとして活動する筆者が必須スキル「だけ」に絞って伝授します。